Copyright © 2015 Bert N. Langford (Images may be subject to copyright. Please send feedback)
Welcome to Our Generation USA!
On this Page We Cover
The Best of The Internet.
Note that, however,
For Social Networking, click here
For Web-based Television, click here
For Internet Security, click here
Google: Search Engine and Multinational Technology Company.
YouTube Video: Introducing Google Gnome Game
YouTube Video: (Google) Waymo's fully self-driving cars are here
YouTube Video: Made by Google 2017 | Event highlights

Google LLC is an American multinational technology company that specializes in Internet-related services and products. These include the following:
Google was founded in 1998 by Larry Page and Sergey Brin while they were Ph.D. students at Stanford University, in California. Together, they own about 14 percent of its shares, and control 56 percent of the stockholder voting power through supervoting stock. They incorporated Google as a privately held company on September 4, 1998.
An initial public offering (IPO) took place on August 19, 2004, and Google moved to its new headquarters in Mountain View, California, nicknamed the Googleplex.
In August 2015, Google announced plans to reorganize its various interests as a conglomerate called Alphabet Inc. Google, Alphabet's leading subsidiary, will continue to be the umbrella company for Alphabet's Internet interests. Upon completion of the restructure, Sundar Pichai was appointed CEO of Google; he replaced Larry Page, who became CEO of Alphabet.
The company's rapid growth since incorporation has triggered a chain of products, acquisitions, and partnerships beyond Google's core search engine (Google Search).
It offers services designed for
The company leads the development of the Android mobile operating system, the Google Chrome web browser, and Chrome OS, a lightweight operating system based on the Chrome browser.
Google has moved increasingly into hardware; from 2010 to 2015, it partnered with major electronics manufacturers in the production of its Nexus devices, and in October 2016, it released multiple hardware products, including the following:
The new hardware chief, Rick Osterloh, stated: "a lot of the innovation that we want to do now ends up requiring controlling the end-to-end user experience". Google has also experimented with becoming an Internet carrier.
In February 2010, it announced Google Fiber, a fiber-optic infrastructure that was installed in Kansas City; in April 2015, it launched Project Fi in the United States, combining Wi-Fi and cellular networks from different providers; and in 2016, it announced the Google Station initiative to make public Wi-Fi available around the world, with initial deployment in India.
Alexa, a company that monitors commercial web traffic, lists Google.com as the most visited website in the world. Several other Google services also figure in the top 100 most visited websites, including YouTube and Blogger. Google is the most valuable brand in the world as of 2017, but has received significant criticism involving issues such as privacy concerns, tax avoidance, antitrust, censorship, and search neutrality.
Google's mission statement, from the outset, was "to organize the world's information and make it universally accessible and useful", and its unofficial slogan was "Don't be evil". In October 2015, the motto was replaced in the Alphabet corporate code of conduct by the phrase "Do the right thing".
Click on any of the following blue hyperlinks for more about the company "Google"
- online advertising technologies,
- search,
- cloud computing,
- software,
- and hardware.
Google was founded in 1998 by Larry Page and Sergey Brin while they were Ph.D. students at Stanford University, in California. Together, they own about 14 percent of its shares, and control 56 percent of the stockholder voting power through supervoting stock. They incorporated Google as a privately held company on September 4, 1998.
An initial public offering (IPO) took place on August 19, 2004, and Google moved to its new headquarters in Mountain View, California, nicknamed the Googleplex.
In August 2015, Google announced plans to reorganize its various interests as a conglomerate called Alphabet Inc. Google, Alphabet's leading subsidiary, will continue to be the umbrella company for Alphabet's Internet interests. Upon completion of the restructure, Sundar Pichai was appointed CEO of Google; he replaced Larry Page, who became CEO of Alphabet.
The company's rapid growth since incorporation has triggered a chain of products, acquisitions, and partnerships beyond Google's core search engine (Google Search).
It offers services designed for
- work and productivity:
- email (Gmail/Inbox),
- scheduling and time management (Google Calendar),
- cloud storage (Google Drive),
- social networking (Google+),
- instant messaging and video chat (Google Allo/Duo/Hangouts),
- language translation (Google Translate),
- mapping and turn-by-turn navigation (Google Maps/Waze/Earth/Street View),
- video sharing (YouTube),
- notetaking (Google Keep),
- and photo organizing and editing (Google Photos).
The company leads the development of the Android mobile operating system, the Google Chrome web browser, and Chrome OS, a lightweight operating system based on the Chrome browser.
Google has moved increasingly into hardware; from 2010 to 2015, it partnered with major electronics manufacturers in the production of its Nexus devices, and in October 2016, it released multiple hardware products, including the following:
- Google Pixel smartphone,
- Home smart speaker,
- Wifi mesh wireless router,
- and Daydream View virtual reality headset.
The new hardware chief, Rick Osterloh, stated: "a lot of the innovation that we want to do now ends up requiring controlling the end-to-end user experience". Google has also experimented with becoming an Internet carrier.
In February 2010, it announced Google Fiber, a fiber-optic infrastructure that was installed in Kansas City; in April 2015, it launched Project Fi in the United States, combining Wi-Fi and cellular networks from different providers; and in 2016, it announced the Google Station initiative to make public Wi-Fi available around the world, with initial deployment in India.
Alexa, a company that monitors commercial web traffic, lists Google.com as the most visited website in the world. Several other Google services also figure in the top 100 most visited websites, including YouTube and Blogger. Google is the most valuable brand in the world as of 2017, but has received significant criticism involving issues such as privacy concerns, tax avoidance, antitrust, censorship, and search neutrality.
Google's mission statement, from the outset, was "to organize the world's information and make it universally accessible and useful", and its unofficial slogan was "Don't be evil". In October 2015, the motto was replaced in the Alphabet corporate code of conduct by the phrase "Do the right thing".
Click on any of the following blue hyperlinks for more about the company "Google"
- History
- Products and services
- Corporate affairs and culture
- Criticism and controversy
- See also:
- AngularJS
- Comparison of web search engines
- Don't Be Evil
- Google (verb)
- Google Balloon Internet
- Google Catalogs
- Google China
- Google bomb
- Google Chrome Experiments
- Google Get Your Business Online
- Google logo
- Google Maps
- Google platform
- Google Street View
- Google tax
- Google Ventures – venture capital fund
- Google X
- Life sciences division of Google X
- Googlebot – web crawler
- Googlization
- List of Google apps for Android
- List of mergers and acquisitions by Alphabet
- Apple, Inc.
- Outline of Google
- Reunion
- Ungoogleable
- Surveillance capitalism
- Calico
- Official website
- Google website at the Wayback Machine (archived November 11, 1998)
- Google at CrunchBase
- Google companies grouped at OpenCorporates
- Business data for Google, Inc.:
YouTube Including a List of the most watched YouTube Videos
YouTube Video: HOW TO MAKE VIDEOS AND START A YOUTUBE CHANNEL
Video Sharing Website Ranked #2 by Alexa (#3 by SimilarWeb)

Click here for a List of the Most Watched YouTube Videos.
YouTube is an American video-sharing website headquartered in San Bruno, California. The service was created by three former PayPal employees — Chad Hurley, Steve Chen, and Jawed Karim — in February 2005. Google bought the site in November 2006 for US$1.65 billion; YouTube now operates as one of Google's subsidiaries.
YouTube allows users to upload, view, rate, share, add to favorites, report, comment on videos, and subscribe to other users. It uses WebM, H.264/MPEG-4 AVC, and Adobe Flash Video technology to display a wide variety of user-generated and corporate media videos.
Available content includes the following:
Most of the content on YouTube has been uploaded by individuals, but media corporations including CBS, the BBC, Vevo, and Hulu offer some of their material via YouTube as part of the YouTube partnership program.
Unregistered users can only watch videos on the site, while registered users are permitted to upload an unlimited number of videos and add comments to videos. Videos deemed potentially offensive are available only to registered users affirming themselves to be at least 18 years old.
YouTube earns advertising revenue from Google AdSense, a program which targets ads according to site content and audience. The vast majority of its videos are free to view, but there are exceptions, including subscription-based premium channels, film rentals, as well as YouTube Red, a subscription service offering ad-free access to the website and access to exclusive content made in partnership with existing users.
As of February 2017, there are more than 400 hours of content uploaded to YouTube each minute, and one billion hours of content are watched on YouTube every day. As of April 2017, the website is ranked as the second most popular site in the world by Alexa Internet, a web traffic analysis company.
Click on any of the following blue hyperlinks for more about YouTube Videos:
YouTube is an American video-sharing website headquartered in San Bruno, California. The service was created by three former PayPal employees — Chad Hurley, Steve Chen, and Jawed Karim — in February 2005. Google bought the site in November 2006 for US$1.65 billion; YouTube now operates as one of Google's subsidiaries.
YouTube allows users to upload, view, rate, share, add to favorites, report, comment on videos, and subscribe to other users. It uses WebM, H.264/MPEG-4 AVC, and Adobe Flash Video technology to display a wide variety of user-generated and corporate media videos.
Available content includes the following:
- video clips,
- TV show clips,
- music videos,
- short and documentary films,
- audio recordings,
- movie trailers,
- video blogging,
- short original videos,
- and educational videos.
Most of the content on YouTube has been uploaded by individuals, but media corporations including CBS, the BBC, Vevo, and Hulu offer some of their material via YouTube as part of the YouTube partnership program.
Unregistered users can only watch videos on the site, while registered users are permitted to upload an unlimited number of videos and add comments to videos. Videos deemed potentially offensive are available only to registered users affirming themselves to be at least 18 years old.
YouTube earns advertising revenue from Google AdSense, a program which targets ads according to site content and audience. The vast majority of its videos are free to view, but there are exceptions, including subscription-based premium channels, film rentals, as well as YouTube Red, a subscription service offering ad-free access to the website and access to exclusive content made in partnership with existing users.
As of February 2017, there are more than 400 hours of content uploaded to YouTube each minute, and one billion hours of content are watched on YouTube every day. As of April 2017, the website is ranked as the second most popular site in the world by Alexa Internet, a web traffic analysis company.
Click on any of the following blue hyperlinks for more about YouTube Videos:
- Company history
- Features
- Video technology
- Playback
- Uploading
Quality and formats
3D videos
360° videos
- User features
- Content accessibility
- Localization
- YouTube Red
- YouTube TV
- Video technology
- Social impact
- Revenue
- Community policy
- Censorship and filtering
- Music Key licensing
- NSA Prism program
- April Fools
- CNN-YouTube presidential debates
- List of YouTubers
- BookTube
- Ouellette v. Viacom International Inc.
- Reply Girls
- YouTube Awards
- YouTube Instant
- YouTube Live
- YouTube Multi Channel Network
- YouTube Symphony Orchestra
- Viacom International Inc. v. YouTube, Inc.
- Alternative media
- Comparison of video hosting services
- List of Internet phenomena
- List of video hosting services
- YouTube on Blogger
- Press room – YouTube
- YouTube – Google Developers
- Haran, Brady; Hamilton, Ted. "Why do YouTube views freeze at 301?". Numberphile. Brady Haran.
- Dickey, Megan Rose (February 15, 2013). "The 22 Key Turning Points in the History of YouTube". Business Insider. Axel Springer SE. Retrieved March 25, 2017.
- Are Youtubers Revolutionizing Entertainment? (June 6, 2013), video produced for PBS by Off Book.
- First Youtube video ever
Facebook and its owner Meta Platforms Pictured below: Infographic: Timeline of Facebook data scandal
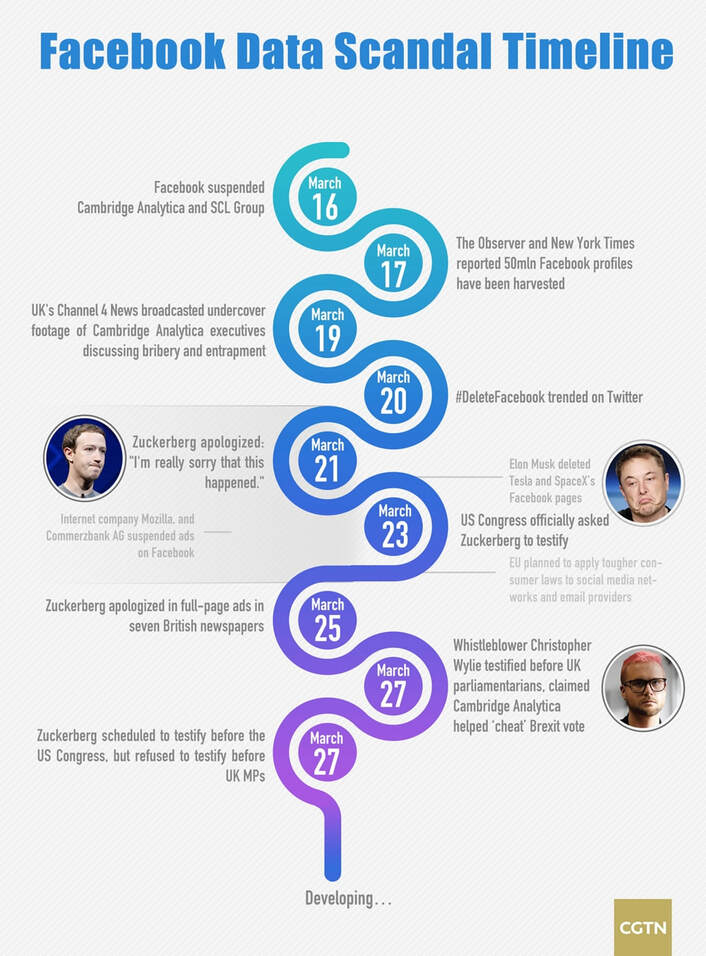
Facebook is an online social media and social networking service owned by American company Meta Platforms (see below).
Founded in 2004 by Mark Zuckerberg with fellow Harvard College students and roommates Eduardo Saverin, Andrew McCollum, Dustin Moskovitz, and Chris Hughes, its name comes from the face book directories often given to American university students.
Membership was initially limited to Harvard students, gradually expanding to other North American universities and, since 2006, anyone over 13 years old.
As of July 2022, Facebook claimed 2.93 billion monthly active users, and ranked third worldwide among the most visited websites as of July 2022. It was the most downloaded mobile app of the 2010s.
Facebook can be accessed from devices with Internet connectivity, such as personal computers, tablets and smartphones. After registering, users can create a profile revealing information about themselves. They can post text, photos and multimedia which are shared with any other users who have agreed to be their "friend" or, with different privacy settings, publicly.
Users can also communicate directly with each other with Facebook Messenger, join common-interest groups, and receive notifications on the activities of their Facebook friends and the pages they follow.
The subject of numerous controversies, Facebook has often been criticized over issues such as user privacy (as with the Cambridge Analytica data scandal), political manipulation (as with the 2016 U.S. elections) and mass surveillance.
Posts originating from the Facebook page of Breitbart News, a media organization previously affiliated with Cambridge Analytica, are currently among the most widely shared political content on Facebook.
Facebook has also been subject to criticism over psychological effects such as addiction and low self-esteem, and various controversies over content such as fake news, conspiracy theories, copyright infringement, and hate speech.
Commentators have accused Facebook of willingly facilitating the spread of such content, as well as exaggerating its number of users to appeal to advertisers
Click on any of the following blue hyperlinks for more about Facebook:
Meta Platforms, Inc., doing business as Meta and formerly named Facebook, Inc., and TheFacebook, Inc., is an American multinational technology conglomerate based in Menlo Park, California.
The company owns Facebook, Instagram, and WhatsApp, among other products and services. Meta was once one of the world's most valuable companies, but as of 2022 is not one of the top twenty biggest companies in the United States.
Meta is considered one of the Big Five American information technology companies, alongside Alphabet (Google), Amazon, Apple, and Microsoft.
As of 2022, it is the least profitable of the five.
Meta's products and services include Facebook, Messenger, Facebook Watch, and Meta Portal. It has also acquired Oculus, Giphy, Mapillary, Kustomer, Presize and has a 9.99% stake in Jio Platforms. In 2021, the company generated 97.5% of its revenue from the sale of advertising.
In October 2021, the parent company of Facebook changed its name from Facebook, Inc., to Meta Platforms, Inc., to "reflect its focus on building the metaverse". According to Meta, the "metaverse" refers to the integrated environment that links all of the company's products and services.
Click on any of the following blue hyperlinks for more about Meta Platforms, Inc.:
Founded in 2004 by Mark Zuckerberg with fellow Harvard College students and roommates Eduardo Saverin, Andrew McCollum, Dustin Moskovitz, and Chris Hughes, its name comes from the face book directories often given to American university students.
Membership was initially limited to Harvard students, gradually expanding to other North American universities and, since 2006, anyone over 13 years old.
As of July 2022, Facebook claimed 2.93 billion monthly active users, and ranked third worldwide among the most visited websites as of July 2022. It was the most downloaded mobile app of the 2010s.
Facebook can be accessed from devices with Internet connectivity, such as personal computers, tablets and smartphones. After registering, users can create a profile revealing information about themselves. They can post text, photos and multimedia which are shared with any other users who have agreed to be their "friend" or, with different privacy settings, publicly.
Users can also communicate directly with each other with Facebook Messenger, join common-interest groups, and receive notifications on the activities of their Facebook friends and the pages they follow.
The subject of numerous controversies, Facebook has often been criticized over issues such as user privacy (as with the Cambridge Analytica data scandal), political manipulation (as with the 2016 U.S. elections) and mass surveillance.
Posts originating from the Facebook page of Breitbart News, a media organization previously affiliated with Cambridge Analytica, are currently among the most widely shared political content on Facebook.
Facebook has also been subject to criticism over psychological effects such as addiction and low self-esteem, and various controversies over content such as fake news, conspiracy theories, copyright infringement, and hate speech.
Commentators have accused Facebook of willingly facilitating the spread of such content, as well as exaggerating its number of users to appeal to advertisers
Click on any of the following blue hyperlinks for more about Facebook:
- History
- 2003–2006: Thefacebook, Thiel investment, and name change
- 2006–2012: Public access, Microsoft alliance, and rapid growth
- 2012–2013: IPO, lawsuits, and one billion active users
- 2013–2014: Site developments, A4AI, and 10th anniversary
- 2015–2020: Algorithm revision; fake news
- 2020–present: FTC lawsuit, corporate re-branding, shut down of facial recognition technology, ease of policy
- Website
- Reception
- Criticisms and controversies
- Impact
- See also:
Meta Platforms, Inc., doing business as Meta and formerly named Facebook, Inc., and TheFacebook, Inc., is an American multinational technology conglomerate based in Menlo Park, California.
The company owns Facebook, Instagram, and WhatsApp, among other products and services. Meta was once one of the world's most valuable companies, but as of 2022 is not one of the top twenty biggest companies in the United States.
Meta is considered one of the Big Five American information technology companies, alongside Alphabet (Google), Amazon, Apple, and Microsoft.
As of 2022, it is the least profitable of the five.
Meta's products and services include Facebook, Messenger, Facebook Watch, and Meta Portal. It has also acquired Oculus, Giphy, Mapillary, Kustomer, Presize and has a 9.99% stake in Jio Platforms. In 2021, the company generated 97.5% of its revenue from the sale of advertising.
In October 2021, the parent company of Facebook changed its name from Facebook, Inc., to Meta Platforms, Inc., to "reflect its focus on building the metaverse". According to Meta, the "metaverse" refers to the integrated environment that links all of the company's products and services.
Click on any of the following blue hyperlinks for more about Meta Platforms, Inc.:
- History
- Mergers and acquisitions
- Lobbying
- Lawsuits
- Structure
- Revenue
- Facilities
- Reception
- See also:
- Big Tech
- Criticism of Facebook
- Facebook–Cambridge Analytica data scandal
- 2021 Facebook leak
- Meta AI
- The Social Network
- Official website
- Meta Platforms companies grouped at OpenCorporates
- Business data for Meta Platforms, Inc.:
Yahoo!
Portal and media Website Ranked #5 by both Alexa and SimilarWeb.
YouTube Video Yahoo!: What It's Really Like To Buy A Tesla

Yahoo Inc. (styled as Yahoo!) is an American multinational technology company headquartered in Sunnyvale, California.
It is globally known for its Web portal, search engine Yahoo! Search, and related services, including:
- Yahoo! Directory,
- Yahoo! Mail,
- Yahoo! News,
- Yahoo! Finance,
- Yahoo! Groups,
- Yahoo! Answers,
- advertising,
- online mapping,
- video sharing,
- fantasy sports
- and its social media website.
It is one of the most popular sites in the United States. According to third-party web analytics providers, Alexa and SimilarWeb, Yahoo! is the highest-read news and media website, with over 7 billion readers per month, being the fourth most visited website globally, as of June 2015.
According to news sources, roughly 700 million people visit Yahoo websites every month. Yahoo itself claims it attracts "more than half a billion consumers every month in more than 30 languages."
Yahoo was founded by Jerry Yang and David Filo in January 1994 and was incorporated on March 2, 1995. Marissa Mayer, a former Google executive, serves as CEO and President of the company.
In January 2015, the company announced it planned to spin-off its stake in Alibaba Group in a separately listed company. In December 2015 it reversed this decision, opting instead to spin-off its internet business as a separate company.
Amazon including its founder, Jeff Bezos
YouTube by Billionaire Jeff Bezos in Starting Amazon

Amazon.com, Inc., doing business as Amazon, is an American electronic commerce and cloud computing company based in Seattle, Washington, that was founded by Jeff Bezos [see next topic below] on July 5, 1994.
The tech giant is the largest Internet retailer in the world as measured by revenue and market capitalization, and second largest after Alibaba Group in terms of total sales.
The Amazon.com website started as an online bookstore and later diversified to sell the following:
The company also owns/produces the following:
Amazon is the world's largest provider of cloud infrastructure services (IaaS and PaaS) through its AWS subsidiary. Amazon also sells certain low-end products under its in-house brand AmazonBasics.
Amazon has separate retail websites for the United States, the United Kingdom and Ireland, France, Canada, Germany, Italy, Spain, Netherlands, Australia, Brazil, Japan, China, India, Mexico, Singapore, and Turkey. In 2016, Dutch, Polish, and Turkish language versions of the German Amazon website were also launched. Amazon also offers international shipping of some of its products to certain other countries.
In 2015, Amazon surpassed Walmart as the most valuable retailer in the United States by market capitalization.
Amazon is:
In 2017, Amazon acquired Whole Foods Market for $13.4 billion, which vastly increased Amazon's presence as a brick-and-mortar retailer. The acquisition was interpreted by some as a direct attempt to challenge Walmart's traditional retail stores.
In 2018, for the first time, Jeff Bezos released in Amazon's shareholder letter the number of Amazon Prime subscribers, which is 100 million worldwide.
In 2018, Amazon.com contributed US$1 million to the Wikimedia Endowment.
In November 2018, Amazon announced it would be splitting its second headquarters project between two cities. They are currently in the finalization stage of the process.
Click on any of the following blue hyperlinks for more about Amazon, Inc.:
Jeffrey Preston Bezos (né Jorgensen; born January 12, 1964) is an American technology and retail entrepreneur, investor, electrical engineer, computer scientist, and philanthropist, best known as the founder, chairman, and chief executive officer of Amazon.com, the world's largest online shopping retailer.
The company began as an Internet merchant of books and expanded to a wide variety of products and services, most recently video and audio streaming. Amazon.com is currently the world's largest Internet sales company on the World Wide Web, as well as the world's largest provider of cloud infrastructure services, which is available through its Amazon Web Services arm.
Bezos' other diversified business interests include aerospace and newspapers. He is the founder and manufacturer of Blue Origin (founded in 2000) with test flights to space which started in 2015, and plans for commercial suborbital human spaceflight beginning in 2018.
In 2013, Bezos purchased The Washington Post newspaper. A number of other business investments are managed through Bezos Expeditions.
When the financial markets opened on July 27, 2017, Bezos briefly surpassed Bill Gates on the Forbes list of billionaires to become the world's richest person, with an estimated net worth of just over $90 billion. He lost the title later in the day when Amazon's stock dropped, returning him to second place with a net worth just below $90 billion.
On October 27, 2017, Bezos again surpassed Gates on the Forbes list as the richest person in the world. Bezos's net worth surpassed $100 billion for the first time on November 24, 2017 after Amazon's share price increased by more than 2.5%.
Click on any of the following blue hyperlinks for more about Jeff Bezos:
The tech giant is the largest Internet retailer in the world as measured by revenue and market capitalization, and second largest after Alibaba Group in terms of total sales.
The Amazon.com website started as an online bookstore and later diversified to sell the following:
- video downloads/streaming,
- MP3 downloads/streaming,
- audiobook downloads/streaming,
- software,
- video games,
- electronics,
- apparel,
- furniture,
- food,
- toys,
- and jewelry.
The company also owns/produces the following:
- a publishing arm, Amazon Publishing,
- a film and television studio, Amazon Studios,
- produces consumer electronics lines including;
Amazon is the world's largest provider of cloud infrastructure services (IaaS and PaaS) through its AWS subsidiary. Amazon also sells certain low-end products under its in-house brand AmazonBasics.
Amazon has separate retail websites for the United States, the United Kingdom and Ireland, France, Canada, Germany, Italy, Spain, Netherlands, Australia, Brazil, Japan, China, India, Mexico, Singapore, and Turkey. In 2016, Dutch, Polish, and Turkish language versions of the German Amazon website were also launched. Amazon also offers international shipping of some of its products to certain other countries.
In 2015, Amazon surpassed Walmart as the most valuable retailer in the United States by market capitalization.
Amazon is:
- the third most valuable public company in the United States (behind Apple and Microsoft),
- the largest Internet company by revenue in the world,
- and after Walmart, the second largest employer in the United States.
In 2017, Amazon acquired Whole Foods Market for $13.4 billion, which vastly increased Amazon's presence as a brick-and-mortar retailer. The acquisition was interpreted by some as a direct attempt to challenge Walmart's traditional retail stores.
In 2018, for the first time, Jeff Bezos released in Amazon's shareholder letter the number of Amazon Prime subscribers, which is 100 million worldwide.
In 2018, Amazon.com contributed US$1 million to the Wikimedia Endowment.
In November 2018, Amazon announced it would be splitting its second headquarters project between two cities. They are currently in the finalization stage of the process.
Click on any of the following blue hyperlinks for more about Amazon, Inc.:
- History
- Choosing a name
Online bookstore and IPO
2000's
2010 to present
Amazon Go
Amazon 4-Star
Mergers and acquisitions
- Choosing a name
- Board of directors
- Merchant partnerships
- Products and services
- Subsidiaries
- Website at www.amazon.com
- Amazon sales rank
- Technology
- Multi-level sales strategy
- Finances
- October 2018 wage increase
- Controversies
- Notable businesses founded by former employees
- See also:
- Amazon Breakthrough Novel Award
- Amazon Flexible Payments Service
- Amazon Marketplace
- Amazon Standard Identification Number (ASIN)
- List of book distributors
- Statistically improbable phrases – Amazon.com's phrase extraction technique for indexing books
- Amazon (company) companies grouped at OpenCorporates
- Business data for Amazon.com, Inc.: Google Finance
Jeffrey Preston Bezos (né Jorgensen; born January 12, 1964) is an American technology and retail entrepreneur, investor, electrical engineer, computer scientist, and philanthropist, best known as the founder, chairman, and chief executive officer of Amazon.com, the world's largest online shopping retailer.
The company began as an Internet merchant of books and expanded to a wide variety of products and services, most recently video and audio streaming. Amazon.com is currently the world's largest Internet sales company on the World Wide Web, as well as the world's largest provider of cloud infrastructure services, which is available through its Amazon Web Services arm.
Bezos' other diversified business interests include aerospace and newspapers. He is the founder and manufacturer of Blue Origin (founded in 2000) with test flights to space which started in 2015, and plans for commercial suborbital human spaceflight beginning in 2018.
In 2013, Bezos purchased The Washington Post newspaper. A number of other business investments are managed through Bezos Expeditions.
When the financial markets opened on July 27, 2017, Bezos briefly surpassed Bill Gates on the Forbes list of billionaires to become the world's richest person, with an estimated net worth of just over $90 billion. He lost the title later in the day when Amazon's stock dropped, returning him to second place with a net worth just below $90 billion.
On October 27, 2017, Bezos again surpassed Gates on the Forbes list as the richest person in the world. Bezos's net worth surpassed $100 billion for the first time on November 24, 2017 after Amazon's share price increased by more than 2.5%.
Click on any of the following blue hyperlinks for more about Jeff Bezos:
- Early life and education
- Business career
- Philanthropy
- Recognition
- Criticism
- Personal life
- Politics
- See also:
Twitter
Ranked #10 by Alexa and #11 by SimilarWeb
YouTube Video: How to Use Twitter

Twitter is an online social networking service that enables users to send and read short 280-character messages called "tweets".
Registered users can read and post tweets, but those who are unregistered can only read them. Users access Twitter through the website interface, SMS or mobile device app.
Twitter Inc. is based in San Francisco and has more than 25 offices around the world. Twitter was created in March 2006 by Jack Dorsey, Evan Williams, Biz Stone, and Noah Glass and launched in July 2006.
The service rapidly gained worldwide popularity, with more than 100 million users posting 340 million tweets a day in 2012. The service also handled 1.6 billion search queries per day.
In 2013, Twitter was one of the ten most-visited websites and has been described as "the SMS of the Internet". As of May 2015, Twitter has more than 500 million users, out of which more than 332 million are active.
Registered users can read and post tweets, but those who are unregistered can only read them. Users access Twitter through the website interface, SMS or mobile device app.
Twitter Inc. is based in San Francisco and has more than 25 offices around the world. Twitter was created in March 2006 by Jack Dorsey, Evan Williams, Biz Stone, and Noah Glass and launched in July 2006.
The service rapidly gained worldwide popularity, with more than 100 million users posting 340 million tweets a day in 2012. The service also handled 1.6 billion search queries per day.
In 2013, Twitter was one of the ten most-visited websites and has been described as "the SMS of the Internet". As of May 2015, Twitter has more than 500 million users, out of which more than 332 million are active.
List of Most Subscribed Users onYouTube
YouTube Music Video by Taylor Swift performing 22
Pictured: LEFT: PewDiePie (43 Million Followers) and RIGHT: Rihanna (20 Million Followers)

This list of the most subscribed users on YouTube contains representations of the channels with the most subscribers on the video platform YouTube.
The ability to "subscribe" to a user's videos was added to YouTube by late October 2005, The "most subscribed" list on YouTube began being listed by a chart on the site by May 2006, at which time Smosh was #1 with fewer than 3,000 subscribers. As of April 5, 2016, the most subscribed user is PewDiePie, with over 42 million subscribers. The PewDiePie channel has held the peak position since December 22, 2013 (2 years, 3 months and 14 days), when it surpassed YouTube's Spotlight channel.
This list depicts the 25 most subscribed channels on YouTube as of March 10, 2016. This lists omits "channels", and instead only includes "users". A "user" is defined as a channel that has released videos. "Channels" that have released zero videos, such as #Music, #Gaming, or #Sports, are not included on this list, even if they have more subscribers than the users on this list. Additionally, these subscriber counts are approximations.
Reactions
In late 2006 when Peter Oakley aka Geriatric1927 became most subscribed, a number of TV channels wanted to interview him on his rise to fame. The Daily Mail and TechBlog did an article about him and his success. In 2009, the FRED channel was the first channel to have over one million subscribers.
Following the third time that the user Smosh became most subscribed, Ray William Johnson collaborated with the duo.
A flurry of top YouTubers including Ryan Higa, Shane Dawson, Felix Kjellberg, Michael Buckley, Kassem Gharaibeh, The Fine Brothers, and Johnson himself, congratulated the duo shortly after they surpassed Johnson as the most subscribed channel.
Following Felix Kjellberg's positioning at the top of YouTube, Variety heavily criticized the Swede's videos.
See also
The ability to "subscribe" to a user's videos was added to YouTube by late October 2005, The "most subscribed" list on YouTube began being listed by a chart on the site by May 2006, at which time Smosh was #1 with fewer than 3,000 subscribers. As of April 5, 2016, the most subscribed user is PewDiePie, with over 42 million subscribers. The PewDiePie channel has held the peak position since December 22, 2013 (2 years, 3 months and 14 days), when it surpassed YouTube's Spotlight channel.
This list depicts the 25 most subscribed channels on YouTube as of March 10, 2016. This lists omits "channels", and instead only includes "users". A "user" is defined as a channel that has released videos. "Channels" that have released zero videos, such as #Music, #Gaming, or #Sports, are not included on this list, even if they have more subscribers than the users on this list. Additionally, these subscriber counts are approximations.
Reactions
In late 2006 when Peter Oakley aka Geriatric1927 became most subscribed, a number of TV channels wanted to interview him on his rise to fame. The Daily Mail and TechBlog did an article about him and his success. In 2009, the FRED channel was the first channel to have over one million subscribers.
Following the third time that the user Smosh became most subscribed, Ray William Johnson collaborated with the duo.
A flurry of top YouTubers including Ryan Higa, Shane Dawson, Felix Kjellberg, Michael Buckley, Kassem Gharaibeh, The Fine Brothers, and Johnson himself, congratulated the duo shortly after they surpassed Johnson as the most subscribed channel.
Following Felix Kjellberg's positioning at the top of YouTube, Variety heavily criticized the Swede's videos.
See also
Vevo
YouTube Video: Lenny Kravitz - Lenny Kravitz Talks ‘Raise Vibration,’ And Why Love Still Rules

Vevo is a multinational video hosting service owned and operated by a joint venture of Universal Music Group (UMG), Google, Sony Music Entertainment (SME), and Abu Dhabi Media, and based in New York City.
Launched on December 8, 2009, Vevo hosts videos syndicated across the web, with Google and Vevo sharing the advertising revenue.
Vevo offers music videos from two of the "big three" major record labels, UMG and SME. EMI also licensed its library for Vevo shortly before launch; it was acquired by UMG in 2012.
Warner Music Group was initially reported to be considering hosting its content on the service, but formed an alliance with rival MTV Networks (now Viacom Media Networks). In August 2015, Vevo expressed interest in licensing music from Warner Music Group.
The concept for Vevo was described as being a streaming service for music videos (similar to the streaming service Hulu, a streaming service for movies and TV shows after they air), with the goal being to attract more high-end advertisers.
The site's other revenue sources include a merchandise store and referral links to purchase viewed songs on Amazon Music and iTunes.
UMG acquired the domain name vevo.com on November 20, 2008. SME reached a deal to add its content to the site in June 2009.
The site went live on December 8, 2009, and that same month became the number one most visited music site in the United States, overtaking MySpace Music.
In June 2012, Vevo launched its Certified awards, which honors artists with at least 100 million views on Vevo and its partners (including YouTube) through special features on the Vevo website.
Vevo TV:On March 12, 2013, Vevo launched Vevo TV, an advertising-supported internet television channel running 24 hours a day, featuring blocks of music videos and specials. The channel is only available to viewers in North America and Germany, with geographical IP address blocking being used to enforce the restriction. Vevo has planned launches in other countries.
After revamping its website, Vevo TV later branched off into three separate networks: Hits, Flow (hip hop and R&B), and Nashville (country music).
Availability:
Vevo is available in Belgium, Brazil, Canada, Chile, France, Germany, Ireland, Italy, Mexico, the Netherlands, New Zealand, Poland, Spain, the United Kingdom, and the United States. The website was scheduled to go worldwide in 2010, but as of January 1, 2016, it was still not available outside these countries.
Vevo's official blog cited licensing issues for the delay in the worldwide rollout. Most of Vevo's videos on YouTube are viewable by users in other countries, while others will produce the message "The uploader has not made this video available in your country."
The Vevo service in the United Kingdom and Ireland was launched on April 26, 2011.
On April 16, 2012, Vevo was launched in Australia and New Zealand by MCM Entertainment. On August 14, 2012, Brazil became the first Latin American country to have the service. It was expected to be launched in six more European and Latin American countries in 2012. Vevo launched in Spain, Italy, and France on November 15, 2012. Vevo launched in the Netherlands on April 3, 2013, and on May 17, 2013, also in Poland.
In September 29, 2013, Vevo updated its iOS application that now includes launching in Germany. On April 30, 2014, Vevo was launched in Mexico.
Vevo is also available for a range of platforms including Android, iOS, Windows Phone, Windows 8, Fire OS, Google TV, Apple TV, Boxee, Roku, Xbox 360, PlayStation 3, and PlayStation 4.
Edited content Versions of videos on Vevo with explicit content such as profanity may be edited, according to a company spokesperson, "to keep everything clean for broadcast, 'the MTV version.'" This allows Vevo to make their network more friendly to advertising partners such as McDonald's.
Vevo has stated that it does not have specific policies or a list of words that are forbidden. Some explicit videos are provided with uncut versions in addition to the edited version.
There is no formal rating system in place, aside from classifying videos as explicit or non-explicit, but discussions are taking place to create a rating system that allows users and advertisers to choose the level of profanity they are willing to accept.
24-Hour Vevo Record:
The 24-Hour Vevo Record, commonly referred to as the Vevo Record, is the record for the most views a music video associated with Vevo has received within 24 hours of its release.
The video that currently holds this record is "Hello" by Adele with 27.7 million views.
In 2012, Nicki Minaj's "Stupid Hoe" became one of the first Vevo music videos to receive a significant amount of media attention upon its release day, during which it accumulated 4.8 million views. The record has consistently been kept track of by Vevo ever since.
Total views of a video are counted from across all of Vevo's platforms, including YouTube, Yahoo! and other syndication partners.
On 14 April 2013, Psy's "Gentleman" unofficially broke the record by reaching 38.4 million views in its first 24 hours. However, this record is not acknowledged by Vevo because it was only associated with them four days after its release.
Minaj has broken the Vevo Record more than any other artist with three separate videos: "Stupid Hoe", "Beauty and a Beat" and "Anaconda". She has held the record for an accumulated 622 days.
Justin Bieber, One Direction and Miley Cyrus have all broken the record twice.
Launched on December 8, 2009, Vevo hosts videos syndicated across the web, with Google and Vevo sharing the advertising revenue.
Vevo offers music videos from two of the "big three" major record labels, UMG and SME. EMI also licensed its library for Vevo shortly before launch; it was acquired by UMG in 2012.
Warner Music Group was initially reported to be considering hosting its content on the service, but formed an alliance with rival MTV Networks (now Viacom Media Networks). In August 2015, Vevo expressed interest in licensing music from Warner Music Group.
The concept for Vevo was described as being a streaming service for music videos (similar to the streaming service Hulu, a streaming service for movies and TV shows after they air), with the goal being to attract more high-end advertisers.
The site's other revenue sources include a merchandise store and referral links to purchase viewed songs on Amazon Music and iTunes.
UMG acquired the domain name vevo.com on November 20, 2008. SME reached a deal to add its content to the site in June 2009.
The site went live on December 8, 2009, and that same month became the number one most visited music site in the United States, overtaking MySpace Music.
In June 2012, Vevo launched its Certified awards, which honors artists with at least 100 million views on Vevo and its partners (including YouTube) through special features on the Vevo website.
Vevo TV:On March 12, 2013, Vevo launched Vevo TV, an advertising-supported internet television channel running 24 hours a day, featuring blocks of music videos and specials. The channel is only available to viewers in North America and Germany, with geographical IP address blocking being used to enforce the restriction. Vevo has planned launches in other countries.
After revamping its website, Vevo TV later branched off into three separate networks: Hits, Flow (hip hop and R&B), and Nashville (country music).
Availability:
Vevo is available in Belgium, Brazil, Canada, Chile, France, Germany, Ireland, Italy, Mexico, the Netherlands, New Zealand, Poland, Spain, the United Kingdom, and the United States. The website was scheduled to go worldwide in 2010, but as of January 1, 2016, it was still not available outside these countries.
Vevo's official blog cited licensing issues for the delay in the worldwide rollout. Most of Vevo's videos on YouTube are viewable by users in other countries, while others will produce the message "The uploader has not made this video available in your country."
The Vevo service in the United Kingdom and Ireland was launched on April 26, 2011.
On April 16, 2012, Vevo was launched in Australia and New Zealand by MCM Entertainment. On August 14, 2012, Brazil became the first Latin American country to have the service. It was expected to be launched in six more European and Latin American countries in 2012. Vevo launched in Spain, Italy, and France on November 15, 2012. Vevo launched in the Netherlands on April 3, 2013, and on May 17, 2013, also in Poland.
In September 29, 2013, Vevo updated its iOS application that now includes launching in Germany. On April 30, 2014, Vevo was launched in Mexico.
Vevo is also available for a range of platforms including Android, iOS, Windows Phone, Windows 8, Fire OS, Google TV, Apple TV, Boxee, Roku, Xbox 360, PlayStation 3, and PlayStation 4.
Edited content Versions of videos on Vevo with explicit content such as profanity may be edited, according to a company spokesperson, "to keep everything clean for broadcast, 'the MTV version.'" This allows Vevo to make their network more friendly to advertising partners such as McDonald's.
Vevo has stated that it does not have specific policies or a list of words that are forbidden. Some explicit videos are provided with uncut versions in addition to the edited version.
There is no formal rating system in place, aside from classifying videos as explicit or non-explicit, but discussions are taking place to create a rating system that allows users and advertisers to choose the level of profanity they are willing to accept.
24-Hour Vevo Record:
The 24-Hour Vevo Record, commonly referred to as the Vevo Record, is the record for the most views a music video associated with Vevo has received within 24 hours of its release.
The video that currently holds this record is "Hello" by Adele with 27.7 million views.
In 2012, Nicki Minaj's "Stupid Hoe" became one of the first Vevo music videos to receive a significant amount of media attention upon its release day, during which it accumulated 4.8 million views. The record has consistently been kept track of by Vevo ever since.
Total views of a video are counted from across all of Vevo's platforms, including YouTube, Yahoo! and other syndication partners.
On 14 April 2013, Psy's "Gentleman" unofficially broke the record by reaching 38.4 million views in its first 24 hours. However, this record is not acknowledged by Vevo because it was only associated with them four days after its release.
Minaj has broken the Vevo Record more than any other artist with three separate videos: "Stupid Hoe", "Beauty and a Beat" and "Anaconda". She has held the record for an accumulated 622 days.
Justin Bieber, One Direction and Miley Cyrus have all broken the record twice.
Alexa Internet
YouTube Video: The Secret to Becoming the Top Website in Any Popular Niche 2017 - Better Alexa Rank

Alexa Internet, Inc. is a California-based company that provides commercial web traffic data and analytics. It is a wholly owned subsidiary of Amazon.com.
Founded as an independent company in 1996, Alexa was acquired by Amazon in 1999. Its toolbar collects data on browsing behavior and transmits them to the Alexa website, where they are stored and analyzed, forming the basis for the company's web traffic reporting. According to its website, Alexa provides traffic data, global rankings and other information on 30 million websites, and as of 2015 its website is visited by over 6.5 million people monthly.
Alexa Internet was founded in April 1996 by American web entrepreneurs Brewster Kahle and Bruce Gilliat. The company's name was chosen in homage to the Library of Alexandria of Ptolemaic Egypt, drawing a parallel between the largest repository of knowledge in the ancient world and the potential of the Internet to become a similar store of knowledge.
Alexa initially offered a toolbar that gave Internet users suggestions on where to go next, based on the traffic patterns of its user community. The company also offered context for each site visited: to whom it was registered, how many pages it had, how many other sites pointed to it, and how frequently it was updated.
Alexa's operations grew to include archiving of web pages as they are crawled. This database served as the basis for the creation of the Internet Archive accessible through the Wayback Machine. In 1998, the company donated a copy of the archive, two terabytes in size, to the Library of Congress. Alexa continues to supply the Internet Archive with Web crawls.
In 1999, as the company moved away from its original vision of providing an "intelligent" search engine, Alexa was acquired by Amazon.com for approximately US$250 million in Amazon stock.
Alexa began a partnership with Google in early 2002, and with the web directory DMOZ in January 2003. In May 2006, Amazon replaced Google with Bing (at the time known as Windows Live Search) as a provider of search results.
In December 2006, Amazon released Alexa Image Search. Built in-house, it was the first major application built on the company's Web platform.
In December 2005, Alexa opened its extensive search index and Web-crawling facilities to third party programs through a comprehensive set of Web services and APIs. These could be used, for instance, to construct vertical search engines that could run on Alexa's own servers or elsewhere. In May 2007, Alexa changed their API to limit comparisons to three websites, reduce the size of embedded graphs in Flash, and add mandatory embedded BritePic advertisements.
In April 2007, the lawsuit Alexa v. Hornbaker was filed to stop trademark infringement by the Statsaholic service. In the lawsuit, Alexa alleged that Hornbaker was stealing traffic graphs for profit, and that the primary purpose of his site was to display graphs that were generated by Alexa's servers. Hornbaker removed the term Alexa from his service name on March 19, 2007.
On November 27, 2008, Amazon announced that Alexa Web Search was no longer accepting new customers, and that the service would be deprecated or discontinued for existing customers on January 26, 2009. Thereafter, Alexa became a purely analytics-focused company.
On March 31, 2009, Alexa launched a major website redesign. The redesigned site provided new web traffic metrics—including average page views per individual user, bounce rate, and user time on site. In the following weeks, Alexa added more features, including visitor demographics, clickstream and search traffic statistics. Alexa introduced these new features to compete with other web analytics services.
Tracking:
Toolbar: Alexa ranks sites based primarily on tracking a sample set of internet traffic—users of its toolbar for the Internet Explorer, Firefox and Google Chrome web browsers.
The Alexa Toolbar includes a popup blocker, a search box, links to Amazon.com and the Alexa homepage, and the Alexa ranking of the site that the user is visiting. It also allows the user to rate the site and view links to external, relevant sites.
In early 2005, Alexa stated that there had been 10 million downloads of the toolbar, though the company did not provide statistics about active usage. Originally, web pages were only ranked amongst users who had the Alexa Toolbar installed, and could be biased if a specific audience subgroup was reluctant to take part in the rankings. This caused some controversy over how representative Alexa's user base was of typical Internet behavior, especially for less-visited sites.
In 2007, Michael Arrington provided examples of Alexa rankings known to contradict data from the comScore web analytics service, including ranking YouTube ahead of Google.
Until 2007, a third-party-supplied plugin for the Firefox browser served as the only option for Firefox users after Amazon abandoned its A9 toolbar. On July 16, 2007, Alexa released an official toolbar for Firefox called Sparky.
On 16 April 2008, many users reported dramatic shifts in their Alexa rankings. Alexa confirmed this later in the day with an announcement that they had released an updated ranking system, claiming that they would now take into account more sources of data "beyond Alexa Toolbar users".
Certified statistics:
Using the Alexa Pro service, website owners can sign up for "certified statistics," which allows Alexa more access to a site's traffic data. Site owners input Javascript code on each page of their website that, if permitted by the user's security and privacy settings, runs and sends traffic data to Alexa, allowing Alexa to display—or not display, depending on the owner's preference—more accurate statistics such as total pageviews and unique pageviews.
Privacy and malware assessments:
A number of antivirus companies have assessed Alexa's toolbar. The toolbar for Internet Explorer 7 was at one point flagged as malware by Microsoft Defender.
Symantec classifies the toolbar as "trackware", while McAfee classifies it as adware, deeming it a "potentially unwanted program." McAfee Site Advisor rates the Alexa site as "green", finding "no significant problems" but warning of a "small fraction of downloads ... that some people consider adware or other potentially unwanted programs."
Though it is possible to delete a paid subscription within an Alexa account, it is not possible to delete an account that is created at Alexa through any web interface, though any user may contact the company via its support webpage.
Founded as an independent company in 1996, Alexa was acquired by Amazon in 1999. Its toolbar collects data on browsing behavior and transmits them to the Alexa website, where they are stored and analyzed, forming the basis for the company's web traffic reporting. According to its website, Alexa provides traffic data, global rankings and other information on 30 million websites, and as of 2015 its website is visited by over 6.5 million people monthly.
Alexa Internet was founded in April 1996 by American web entrepreneurs Brewster Kahle and Bruce Gilliat. The company's name was chosen in homage to the Library of Alexandria of Ptolemaic Egypt, drawing a parallel between the largest repository of knowledge in the ancient world and the potential of the Internet to become a similar store of knowledge.
Alexa initially offered a toolbar that gave Internet users suggestions on where to go next, based on the traffic patterns of its user community. The company also offered context for each site visited: to whom it was registered, how many pages it had, how many other sites pointed to it, and how frequently it was updated.
Alexa's operations grew to include archiving of web pages as they are crawled. This database served as the basis for the creation of the Internet Archive accessible through the Wayback Machine. In 1998, the company donated a copy of the archive, two terabytes in size, to the Library of Congress. Alexa continues to supply the Internet Archive with Web crawls.
In 1999, as the company moved away from its original vision of providing an "intelligent" search engine, Alexa was acquired by Amazon.com for approximately US$250 million in Amazon stock.
Alexa began a partnership with Google in early 2002, and with the web directory DMOZ in January 2003. In May 2006, Amazon replaced Google with Bing (at the time known as Windows Live Search) as a provider of search results.
In December 2006, Amazon released Alexa Image Search. Built in-house, it was the first major application built on the company's Web platform.
In December 2005, Alexa opened its extensive search index and Web-crawling facilities to third party programs through a comprehensive set of Web services and APIs. These could be used, for instance, to construct vertical search engines that could run on Alexa's own servers or elsewhere. In May 2007, Alexa changed their API to limit comparisons to three websites, reduce the size of embedded graphs in Flash, and add mandatory embedded BritePic advertisements.
In April 2007, the lawsuit Alexa v. Hornbaker was filed to stop trademark infringement by the Statsaholic service. In the lawsuit, Alexa alleged that Hornbaker was stealing traffic graphs for profit, and that the primary purpose of his site was to display graphs that were generated by Alexa's servers. Hornbaker removed the term Alexa from his service name on March 19, 2007.
On November 27, 2008, Amazon announced that Alexa Web Search was no longer accepting new customers, and that the service would be deprecated or discontinued for existing customers on January 26, 2009. Thereafter, Alexa became a purely analytics-focused company.
On March 31, 2009, Alexa launched a major website redesign. The redesigned site provided new web traffic metrics—including average page views per individual user, bounce rate, and user time on site. In the following weeks, Alexa added more features, including visitor demographics, clickstream and search traffic statistics. Alexa introduced these new features to compete with other web analytics services.
Tracking:
Toolbar: Alexa ranks sites based primarily on tracking a sample set of internet traffic—users of its toolbar for the Internet Explorer, Firefox and Google Chrome web browsers.
The Alexa Toolbar includes a popup blocker, a search box, links to Amazon.com and the Alexa homepage, and the Alexa ranking of the site that the user is visiting. It also allows the user to rate the site and view links to external, relevant sites.
In early 2005, Alexa stated that there had been 10 million downloads of the toolbar, though the company did not provide statistics about active usage. Originally, web pages were only ranked amongst users who had the Alexa Toolbar installed, and could be biased if a specific audience subgroup was reluctant to take part in the rankings. This caused some controversy over how representative Alexa's user base was of typical Internet behavior, especially for less-visited sites.
In 2007, Michael Arrington provided examples of Alexa rankings known to contradict data from the comScore web analytics service, including ranking YouTube ahead of Google.
Until 2007, a third-party-supplied plugin for the Firefox browser served as the only option for Firefox users after Amazon abandoned its A9 toolbar. On July 16, 2007, Alexa released an official toolbar for Firefox called Sparky.
On 16 April 2008, many users reported dramatic shifts in their Alexa rankings. Alexa confirmed this later in the day with an announcement that they had released an updated ranking system, claiming that they would now take into account more sources of data "beyond Alexa Toolbar users".
Certified statistics:
Using the Alexa Pro service, website owners can sign up for "certified statistics," which allows Alexa more access to a site's traffic data. Site owners input Javascript code on each page of their website that, if permitted by the user's security and privacy settings, runs and sends traffic data to Alexa, allowing Alexa to display—or not display, depending on the owner's preference—more accurate statistics such as total pageviews and unique pageviews.
Privacy and malware assessments:
A number of antivirus companies have assessed Alexa's toolbar. The toolbar for Internet Explorer 7 was at one point flagged as malware by Microsoft Defender.
Symantec classifies the toolbar as "trackware", while McAfee classifies it as adware, deeming it a "potentially unwanted program." McAfee Site Advisor rates the Alexa site as "green", finding "no significant problems" but warning of a "small fraction of downloads ... that some people consider adware or other potentially unwanted programs."
Though it is possible to delete a paid subscription within an Alexa account, it is not possible to delete an account that is created at Alexa through any web interface, though any user may contact the company via its support webpage.
Public Key Certificate or Digital Certificate
YouTube Video: Understanding Digital Certificates
Pictured: Public Key Infrastructure: Basics about digital certificates (HTTPS, SSL)
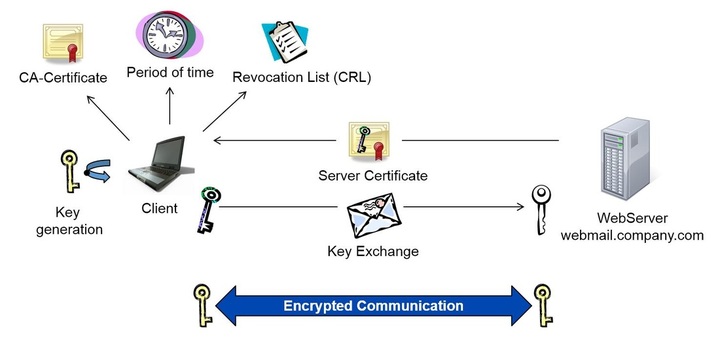
In cryptography, a public key certificate (also known as a digital certificate or identity certificate) is an electronic document used to prove ownership of a public key.
The certificate includes information about the key, information about its owner's identity, and the digital signature of an entity that has verified the certificate's contents are correct. If the signature is valid, and the person examining the certificate trusts the signer, then they know they can use that key to communicate with its owner.
In a typical public-key infrastructure (PKI) scheme, the signer is a certificate authority (CA), usually a company which charges customers to issue certificates for them.
In a web of trust scheme, the signer is either the key's owner (a self-signed certificate) or other users ("endorsements") whom the person examining the certificate might know and trust.
Certificates are an important component of Transport Layer Security (TLS, sometimes called by its older name SSL, Secure Sockets Layer), where they prevent an attacker from impersonating a secure website or other server. They are also used in other important applications, such as email encryption and code signing.
For the Rest about this Topic, Click Here
The certificate includes information about the key, information about its owner's identity, and the digital signature of an entity that has verified the certificate's contents are correct. If the signature is valid, and the person examining the certificate trusts the signer, then they know they can use that key to communicate with its owner.
In a typical public-key infrastructure (PKI) scheme, the signer is a certificate authority (CA), usually a company which charges customers to issue certificates for them.
In a web of trust scheme, the signer is either the key's owner (a self-signed certificate) or other users ("endorsements") whom the person examining the certificate might know and trust.
Certificates are an important component of Transport Layer Security (TLS, sometimes called by its older name SSL, Secure Sockets Layer), where they prevent an attacker from impersonating a secure website or other server. They are also used in other important applications, such as email encryption and code signing.
For the Rest about this Topic, Click Here
How to Protect Your Child from Accessing Inappropriate Content on the Internet
YouTube Video: How to Block Websites with Parental Controls on Your iPhone, Android, and Computer
Pictured: CIPA Logo

The Children's Internet Protection Act (CIPA) requires that K-12 schools and libraries in the United States use Internet filters and implement other measures to protect children from harmful online content as a condition for federal funding. It was signed into law on December 21, 2000, and was found to be constitutional by the United States Supreme Court on June 23, 2003.
Background:
CIPA is one of a number of bills that the United States Congress proposed to limit children's exposure to pornography and explicit content online. Both of Congress's earlier attempts at restricting indecent Internet content, the Communications Decency Act and the Child Online Protection Act, were held to be unconstitutional by the U.S. Supreme Court on First Amendment grounds.
CIPA represented a change in strategy by Congress. While the federal government had no means of directly controlling local school and library boards, many schools and libraries took advantage of Universal Service Fund (USF) discounts derived from universal service fees paid by users in order to purchase eligible telecom services and Internet access.
In passing CIPA, Congress required libraries and K-12 schools using these E-Rate discounts on Internet access and internal connections to purchase and use a "technology protection measure" on every computer connected to the Internet.
These conditions also applied to a small subset of grants authorized through the Library Services and Technology Act (LSTA). CIPA did not provide additional funds for the purchase of the "technology protection measure".
Stipulations:
CIPA requires K-12 schools and libraries using E-Rate discounts to operate "a technology protection measure with respect to any of its computers with Internet access that protects against access through such computers to visual depictions that are obscene, child pornography, or harmful to minors".
Such a technology protection measure must be employed "during any use of such computers by minors". The law also provides that the school or library "may disable the technology protection measure concerned, during use by an adult, to enable access for bona fide research or other lawful purpose".
Schools and libraries that do not receive E-Rate discounts or only receive discounts for telecommunication services and not for Internet access or internal connections, do not have an obligation to filter under CIPA. As of 2007, approximately one-third of libraries had chosen to forego federal E-Rate and certain types of LSTA funds so they would not be required to institute filtering.
This act has several requirements for institutions to meet before they can receive government funds. Libraries and schools must "provide reasonable public notice and hold at least one public hearing or meeting to address the proposed Internet safety policy" (47 U.S.C. § 254(1)(B)) as added by CIPA sec. 1732).
The policy proposed at this meeting must address:
CIPA does not, however, require that Internet use be tracked. All Internet access, even by adults, must be filtered, though filtering requirements can be less restrictive for adults.
Content to be filtered:
The following content must be filtered or blocked:
Some of the terms mentioned in this act, such as “inappropriate matter” and what is “harmful to minors”, are explained in the law. Under the Neighborhood Act (47 U.S.C. § 254(l)(2) as added by CIPA sec. 1732), the definition of “inappropriate matter” is locally determined:
Local Determination of Content – a determination regarding what matter is inappropriate for minors shall be made by the school board, local educational agency, library, or other United States authority responsible for making the determination.
No agency or instrumentality of the Government may – (a) establish criteria for making such determination; (b) review agency determination made by the certifying school, school board, local educational agency, library, or other authority; or (c) consider the criteria employed by the certifying school, school board, educational agency, library, or other authority in the administration of subsection 47 U.S.C. § 254(h)(1)(B).
The CIPA defines “harmful to minors” as:
Any picture, image, graphic image file, or other visual depiction that –
(i) taken as a whole and with respect to minors, appeals to a prurient interest in nudity, sex, or excretion;
(ii) depicts, describes, or represents, in a patently offensive way with respect to what is suitable for minors, an actual or simulated sexual act or sexual contact, actual or simulated normal or perverted sexual acts, or a lewd exhibition of the genitals;
and (iii) taken as a whole, lacks serious literary, artistic, political, or scientific value as to minors” (Secs. 1703(b)(2), 20 U.S.C. sec 3601(a)(5)(F) as added by CIPA sec 1711, 20 U.S.C. sec 9134(b)(f )(7)(B) as added by CIPA sec 1712(a), and 147 U.S.C. sec. 254(h)(c)(G) as added by CIPA sec. 1721(a)).
As mentioned above, there is an exception for Bona Fide Research. An institution can disable filters for adults in the pursuit of bona fide research or another type of lawful purpose. However, the law provides no definition for “bona fide research”.
However, in a later ruling the U.S. Supreme Court said that libraries would be required to adopt an Internet use policy providing for unblocking the Internet for adult users, without a requirement that the library inquire into the user's reasons for disabling the filter.
Justice Rehnquist stated "[a]ssuming that such erroneous blocking presents constitutional difficulties, any such concerns are dispelled by the ease with which patrons may have the filtering software disabled. When a patron encounters a blocked site, he need only ask a librarian to unblock it or (at least in the case of adults) disable the filter". This effectively puts the decision of what constitutes "bona fide research" in the hands of the adult asking to have the filter disabled.
The U.S. Federal Communications Commission (FCC) subsequently instructed libraries complying with CIPA to implement a procedure for unblocking the filter upon request by an adult.
Other filtered content includes sites that contain "inappropriate language", "blogs", or are deemed "tasteless".
This can be somewhat limiting in research for some students, as a resource they wish to use may be disallowed by the filter's vague explanations of why a page is banned. For example, if someone tries to access the page "March 4", and, ironically "Internet Censorship" on Wikipedia, the filter will immediately turn them away, claiming the page contains "Extreme language".
Suits challenging CIPA’s Constitutionality:
On January 17, 2001, the American Library Association (ALA) voted to challenge CIPA, on the grounds that the law required libraries to unconstitutionally block access to constitutionally protected information on the Internet. It charged first that, because CIPA's enforcement mechanism involved removing federal funds intended to assist disadvantaged facilities, "CIPA runs counter to these federal efforts to close the digital divide for all Americans". Second, it argued that "no filtering software successfully differentiates constitutionally protected speech from illegal speech on the Internet".
Working with the American Civil Liberties Union (ACLU), the ALA successfully challenged the law before a three-judge panel of the U.S. District Court for the Eastern District of Pennsylvania.
In a 200-page decision, the judges wrote that "in view of the severe limitations of filtering technology and the existence of these less restrictive alternatives [including making filtering software optional or supervising users directly], we conclude that it is not possible for a public library to comply with CIPA without blocking a very substantial amount of constitutionally protected speech, in violation of the First Amendment". 201 F.Supp.2d 401, 490 (2002).
Upon appeal to the U.S. Supreme Court, however, the law was upheld as constitutional as a condition imposed on institutions in exchange for government funding. In upholding the law, the Supreme Court, adopting the interpretation urged by the U.S. Solicitor General at oral argument, made it clear that the constitutionality of CIPA would be upheld only "if, as the Government represents, a librarian will unblock filtered material or disable the Internet software filter without significant delay on an adult user's request".
In the ruling Chief Justice William Rehnquist, joined by Justice Sandra Day O'Connor, Justice Antonin Scalia, and Justice Clarence Thomas, concluded two points. First, “Because public libraries' use of Internet filtering software does not violate their patrons' First Amendment rights, CIPA does not induce libraries to violate the Constitution, and is a valid exercise of Congress' spending power”.
The argument goes that, because of the immense amount of information available online and how quickly it changes, libraries cannot separate items individually to exclude, and blocking entire websites can often lead to an exclusion of valuable information. Therefore, it is reasonable for public libraries to restrict access to certain categories of content.
Secondly, “CIPA does not impose an unconstitutional condition on libraries that receive E-Rate and LSTA subsidies by requiring them, as a condition on that receipt, to surrender their First Amendment right to provide the public with access to constitutionally protected speech”. The argument here is that, the government can offer public funds to help institutions fulfill their roles, as in the case of libraries providing access to information.
The Justices cited Rust v. Sullivan (1991) as precedent to show how the Court has approved using government funds with certain limitations to facilitate a program. Furthermore, since public libraries traditionally do not include pornographic material in their book collections, the court can reasonably uphold a law that imposes a similar limitation for online texts.
As noted above, the text of the law authorized institutions to disable the filter on request "for bona fide research or other lawful purpose", implying that the adult would be expected to provide justification with his request. But under the interpretation urged by the Solicitor General and adopted by the Supreme Court, libraries would be required to adopt an Internet use policy providing for unblocking the Internet for adult users, without a requirement that the library inquire into the user's reasons for disabling the filter.
Legislation after CIPA:
An attempt to expand CIPA to include "social networking" web sites was considered by the U.S. Congress in 2006. See Deleting Online Predators Act. More attempts have been made recently by the International Society for Technology in Education (ISTE) and the Consortium for School Networking (CoSN) urging Congress to update CIPA terms in hopes of regulating, not abolishing, students' access to social networking and chat rooms.
Neither ISTE nor CoSN wish to ban these online communication outlets entirely however, as they believe the "Internet contains valuable content, collaboration and communication opportunities that can and do materially contribute to a student's academic growth and preparation for the workforce".
See Also:
Background:
CIPA is one of a number of bills that the United States Congress proposed to limit children's exposure to pornography and explicit content online. Both of Congress's earlier attempts at restricting indecent Internet content, the Communications Decency Act and the Child Online Protection Act, were held to be unconstitutional by the U.S. Supreme Court on First Amendment grounds.
CIPA represented a change in strategy by Congress. While the federal government had no means of directly controlling local school and library boards, many schools and libraries took advantage of Universal Service Fund (USF) discounts derived from universal service fees paid by users in order to purchase eligible telecom services and Internet access.
In passing CIPA, Congress required libraries and K-12 schools using these E-Rate discounts on Internet access and internal connections to purchase and use a "technology protection measure" on every computer connected to the Internet.
These conditions also applied to a small subset of grants authorized through the Library Services and Technology Act (LSTA). CIPA did not provide additional funds for the purchase of the "technology protection measure".
Stipulations:
CIPA requires K-12 schools and libraries using E-Rate discounts to operate "a technology protection measure with respect to any of its computers with Internet access that protects against access through such computers to visual depictions that are obscene, child pornography, or harmful to minors".
Such a technology protection measure must be employed "during any use of such computers by minors". The law also provides that the school or library "may disable the technology protection measure concerned, during use by an adult, to enable access for bona fide research or other lawful purpose".
Schools and libraries that do not receive E-Rate discounts or only receive discounts for telecommunication services and not for Internet access or internal connections, do not have an obligation to filter under CIPA. As of 2007, approximately one-third of libraries had chosen to forego federal E-Rate and certain types of LSTA funds so they would not be required to institute filtering.
This act has several requirements for institutions to meet before they can receive government funds. Libraries and schools must "provide reasonable public notice and hold at least one public hearing or meeting to address the proposed Internet safety policy" (47 U.S.C. § 254(1)(B)) as added by CIPA sec. 1732).
The policy proposed at this meeting must address:
- Measures to restrict a minor’s access to inappropriate or harmful materials on the Internet
- Security and safety of minors using chat rooms, email, instant messaging, or any other types of online communications
- Unauthorized disclosure of a minor’s personal information
- Unauthorized access like hacking by minors.
CIPA does not, however, require that Internet use be tracked. All Internet access, even by adults, must be filtered, though filtering requirements can be less restrictive for adults.
Content to be filtered:
The following content must be filtered or blocked:
- Obscenity as defined by Miller v. California (1973)
- Child pornography as defined by 18 U.S.C. 2256
- Harmful to minors
Some of the terms mentioned in this act, such as “inappropriate matter” and what is “harmful to minors”, are explained in the law. Under the Neighborhood Act (47 U.S.C. § 254(l)(2) as added by CIPA sec. 1732), the definition of “inappropriate matter” is locally determined:
Local Determination of Content – a determination regarding what matter is inappropriate for minors shall be made by the school board, local educational agency, library, or other United States authority responsible for making the determination.
No agency or instrumentality of the Government may – (a) establish criteria for making such determination; (b) review agency determination made by the certifying school, school board, local educational agency, library, or other authority; or (c) consider the criteria employed by the certifying school, school board, educational agency, library, or other authority in the administration of subsection 47 U.S.C. § 254(h)(1)(B).
The CIPA defines “harmful to minors” as:
Any picture, image, graphic image file, or other visual depiction that –
(i) taken as a whole and with respect to minors, appeals to a prurient interest in nudity, sex, or excretion;
(ii) depicts, describes, or represents, in a patently offensive way with respect to what is suitable for minors, an actual or simulated sexual act or sexual contact, actual or simulated normal or perverted sexual acts, or a lewd exhibition of the genitals;
and (iii) taken as a whole, lacks serious literary, artistic, political, or scientific value as to minors” (Secs. 1703(b)(2), 20 U.S.C. sec 3601(a)(5)(F) as added by CIPA sec 1711, 20 U.S.C. sec 9134(b)(f )(7)(B) as added by CIPA sec 1712(a), and 147 U.S.C. sec. 254(h)(c)(G) as added by CIPA sec. 1721(a)).
As mentioned above, there is an exception for Bona Fide Research. An institution can disable filters for adults in the pursuit of bona fide research or another type of lawful purpose. However, the law provides no definition for “bona fide research”.
However, in a later ruling the U.S. Supreme Court said that libraries would be required to adopt an Internet use policy providing for unblocking the Internet for adult users, without a requirement that the library inquire into the user's reasons for disabling the filter.
Justice Rehnquist stated "[a]ssuming that such erroneous blocking presents constitutional difficulties, any such concerns are dispelled by the ease with which patrons may have the filtering software disabled. When a patron encounters a blocked site, he need only ask a librarian to unblock it or (at least in the case of adults) disable the filter". This effectively puts the decision of what constitutes "bona fide research" in the hands of the adult asking to have the filter disabled.
The U.S. Federal Communications Commission (FCC) subsequently instructed libraries complying with CIPA to implement a procedure for unblocking the filter upon request by an adult.
Other filtered content includes sites that contain "inappropriate language", "blogs", or are deemed "tasteless".
This can be somewhat limiting in research for some students, as a resource they wish to use may be disallowed by the filter's vague explanations of why a page is banned. For example, if someone tries to access the page "March 4", and, ironically "Internet Censorship" on Wikipedia, the filter will immediately turn them away, claiming the page contains "Extreme language".
Suits challenging CIPA’s Constitutionality:
On January 17, 2001, the American Library Association (ALA) voted to challenge CIPA, on the grounds that the law required libraries to unconstitutionally block access to constitutionally protected information on the Internet. It charged first that, because CIPA's enforcement mechanism involved removing federal funds intended to assist disadvantaged facilities, "CIPA runs counter to these federal efforts to close the digital divide for all Americans". Second, it argued that "no filtering software successfully differentiates constitutionally protected speech from illegal speech on the Internet".
Working with the American Civil Liberties Union (ACLU), the ALA successfully challenged the law before a three-judge panel of the U.S. District Court for the Eastern District of Pennsylvania.
In a 200-page decision, the judges wrote that "in view of the severe limitations of filtering technology and the existence of these less restrictive alternatives [including making filtering software optional or supervising users directly], we conclude that it is not possible for a public library to comply with CIPA without blocking a very substantial amount of constitutionally protected speech, in violation of the First Amendment". 201 F.Supp.2d 401, 490 (2002).
Upon appeal to the U.S. Supreme Court, however, the law was upheld as constitutional as a condition imposed on institutions in exchange for government funding. In upholding the law, the Supreme Court, adopting the interpretation urged by the U.S. Solicitor General at oral argument, made it clear that the constitutionality of CIPA would be upheld only "if, as the Government represents, a librarian will unblock filtered material or disable the Internet software filter without significant delay on an adult user's request".
In the ruling Chief Justice William Rehnquist, joined by Justice Sandra Day O'Connor, Justice Antonin Scalia, and Justice Clarence Thomas, concluded two points. First, “Because public libraries' use of Internet filtering software does not violate their patrons' First Amendment rights, CIPA does not induce libraries to violate the Constitution, and is a valid exercise of Congress' spending power”.
The argument goes that, because of the immense amount of information available online and how quickly it changes, libraries cannot separate items individually to exclude, and blocking entire websites can often lead to an exclusion of valuable information. Therefore, it is reasonable for public libraries to restrict access to certain categories of content.
Secondly, “CIPA does not impose an unconstitutional condition on libraries that receive E-Rate and LSTA subsidies by requiring them, as a condition on that receipt, to surrender their First Amendment right to provide the public with access to constitutionally protected speech”. The argument here is that, the government can offer public funds to help institutions fulfill their roles, as in the case of libraries providing access to information.
The Justices cited Rust v. Sullivan (1991) as precedent to show how the Court has approved using government funds with certain limitations to facilitate a program. Furthermore, since public libraries traditionally do not include pornographic material in their book collections, the court can reasonably uphold a law that imposes a similar limitation for online texts.
As noted above, the text of the law authorized institutions to disable the filter on request "for bona fide research or other lawful purpose", implying that the adult would be expected to provide justification with his request. But under the interpretation urged by the Solicitor General and adopted by the Supreme Court, libraries would be required to adopt an Internet use policy providing for unblocking the Internet for adult users, without a requirement that the library inquire into the user's reasons for disabling the filter.
Legislation after CIPA:
An attempt to expand CIPA to include "social networking" web sites was considered by the U.S. Congress in 2006. See Deleting Online Predators Act. More attempts have been made recently by the International Society for Technology in Education (ISTE) and the Consortium for School Networking (CoSN) urging Congress to update CIPA terms in hopes of regulating, not abolishing, students' access to social networking and chat rooms.
Neither ISTE nor CoSN wish to ban these online communication outlets entirely however, as they believe the "Internet contains valuable content, collaboration and communication opportunities that can and do materially contribute to a student's academic growth and preparation for the workforce".
See Also:
- Content-control software
- Internet censorship
- The King's English v. Shurtleff
- State of Connecticut v. Julie Amero
- Think of the children
The Internet, including its History, Access, Protocol, and a List of the Largest Internet Companies by Revenue
YouTube Video of "How Does the Internet Work ?"
Pictured: Packet routing across the Internet involves several tiers of Internet service providers.
(Courtesy of User:Ludovic.ferre - Internet Connectivity Distribution&Core.svg, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=10030716)
The Internet is the global system of interconnected computer networks that use the Internet protocol suite (TCP/IP) to link billions of devices worldwide. It is a network of networks that consists of millions of private, public, academic, business, and government networks of local to global scope, linked by a broad array of electronic, wireless, and optical networking technologies.
The Internet carries an extensive range of information resources and services, such as the inter-linked hypertext documents and applications of the World Wide Web (WWW), electronic mail, telephony, and peer-to-peer networks for file sharing.
The origins of the Internet date back to research commissioned by the United States government in the 1960s to build robust, fault-tolerant communication via computer networks. The primary precursor network, the ARPANET, initially served as a backbone for interconnection of regional academic and military networks in the 1980s.
The funding of the National Science Foundation Network as a new backbone in the 1980s, as well as private funding for other commercial extensions, led to worldwide participation in the development of new networking technologies, and the merger of many networks. The linking of commercial networks and enterprises by the early 1990s marks the beginning of the transition to the modern Internet, and generated a sustained exponential growth as generations of institutional, personal, and mobile computers were connected to the network.
Although the Internet has been widely used by academia since the 1980s, the commercialization incorporated its services and technologies into virtually every aspect of modern life.
Internet use grew rapidly in the West from the mid-1990s and from the late 1990s in the developing world. In the 20 years since 1995, Internet use has grown 100-times, measured for the period of one year, to over one third of the world population.
Most traditional communications media, including telephony and television, are being reshaped or redefined by the Internet, giving birth to new services such as Internet telephony and Internet television. Newspaper, book, and other print publishing are adapting to website technology, or are reshaped into blogging and web feeds.
The entertainment industry was initially the fastest growing segment on the Internet. The Internet has enabled and accelerated new forms of personal interactions through instant messaging, Internet forums, and social networking. Online shopping has grown exponentially both for major retailers and small artisans and traders. Business-to-business and financial services on the Internet affect supply chains across entire industries.
The Internet has no centralized governance in either technological implementation or policies for access and usage; each constituent network sets its own policies. Only the overreaching definitions of the two principal name spaces in the Internet, the Internet Protocol address space and the Domain Name System (DNS), are directed by a maintainer organization, the Internet Corporation for Assigned Names and Numbers (ICANN).
The technical underpinning and standardization of the core protocols is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise.
(For more detailed information about the Internet, click here)
___________________________________________________________________________
The history of the Internet begins with the development of electronic computers in the 1950s. Initial concepts of packet networking originated in several computer science laboratories in the United States, United Kingdom, and France.
The US Department of Defense awarded contracts as early as the 1960s for packet network systems, including the development of the ARPANET. The first message was sent over the ARPANET from computer science Professor Leonard Kleinrock's laboratory at University of California, Los Angeles (UCLA) to the second network node at Stanford Research. Institute (SRI).
Packet switching networks such as ARPANET, NPL network, CYCLADES, Merit Network, Tymnet, and Telenet, were developed in the late 1960s and early 1970s using a variety of communications protocols. Donald Davies first designed a packet-switched network at the National Physics Laboratory in the UK, which became a testbed for UK research for almost two decades.
The ARPANET project led to the development of protocols for internetworking, in which multiple separate networks could be joined into a network of networks.
Access to the ARPANET was expanded in 1981 when the National Science Foundation (NSF) funded the Computer Science Network (CSNET). In 1982, the Internet protocol suite (TCP/IP) was introduced as the standard networking protocol on the ARPANET.
In the early 1980s the NSF funded the establishment for national supercomputing centers at several universities, and provided interconnectivity in 1986 with the NSFNET project, which also created network access to the supercomputer sites in the United States from research and education organizations. Commercial Internet service providers (ISPs) began to emerge in the very late 1980s.
The ARPANET was decommissioned in 1990. Limited private connections to parts of the Internet by officially commercial entities emerged in several American cities by late 1989 and 1990, and the NSFNET was decommissioned in 1995, removing the last restrictions on the use of the Internet to carry commercial traffic.
In the 1980s, research at CERN in Switzerland by British computer scientist Tim Berners-Lee resulted in the World Wide Web, linking hypertext documents into an information system, accessible from any node on the network.
Since the mid-1990s, the Internet has had a revolutionary impact on culture, commerce, and technology, including the rise of near-instant communication by electronic mail, instant messaging, voice over Internet Protocol (VoIP) telephone calls, two-way interactive video calls, and the World Wide Web with its discussion forums, blogs, social networking, and online shopping sites.
The research and education community continues to develop and use advanced networks such as NSF's very high speed Backbone Network Service (vBNS), Internet2, and National LambdaRail.
Increasing amounts of data are transmitted at higher and higher speeds over fiber optic networks operating at 1-Gbit/s, 10-Gbit/s, or more. The Internet's takeover of the global communication landscape was almost instant in historical terms: it only communicated 1% of the information flowing through two-way telecommunications networks in the year 1993, already 51% by 2000, and more than 97% of the telecommunicated information by 2007.
Today the Internet continues to grow, driven by ever greater amounts of online information, commerce, entertainment, and social networking.
Click here further information about the History of the Internet.
___________________________________________________________________________
Internet access is the process that enables individuals and organisations to connect to the Internet using computer terminals, computers, mobile devices, sometimes via computer networks.
Once connected to the Internet, users can access Internet services, such as email and the World Wide Web. Internet service providers (ISPs) offer Internet access through various technologies that offer a wide range of data signaling rates (speeds).
Consumer use of the Internet first became popular through dial-up Internet access in the 1990s. By the first decade of the 21st century, many consumers in developed nations used faster, broadband Internet access technologies. By 2014 this was almost ubiquitous worldwide, with a global average connection speed exceeding 4 Mbit/s.
Click here for more about Internet Access.
___________________________________________________________________________
The Internet Protocol (IP) is the principal communications protocol in the Internet protocol suite for relaying datagrams across network boundaries. Its routing function enables internetworking, and essentially establishes the Internet.
IP has the task of delivering packets from the source host to the destination host solely based on the IP addresses in the packet headers. For this purpose, IP defines packet structures that encapsulate the data to be delivered. It also defines addressing methods that are used to label the datagram with source and destination information.
Historically, IP was the connectionless datagram service in the original Transmission Control Program introduced by Vint Cerf and Bob Kahn in 1974; the other being the connection-oriented Transmission Control Protocol (TCP). The Internet protocol suite is therefore often referred to as TCP/IP.
The first major version of IP, Internet Protocol Version 4 (IPv4), is the dominant protocol of the Internet. Its successor is Internet Protocol Version 6 (IPv6).
Click here for more about Internet Protocol.
___________________________________________________________________________
A List of the World's Largest Internet Companies:
This is a list of the world's largest internet companies by revenue and market capitalization.
The list is restricted to dot-com companies, defined as a company that does the majority of its business on the Internet, with annual revenues exceeding 1 billion USD. It excludes Internet service providers or other information technology companies. For a more general list of IT companies, see list of the largest information technology companies.
Click here for a listing of the Largest Internet Companies based on revenues.
The Internet carries an extensive range of information resources and services, such as the inter-linked hypertext documents and applications of the World Wide Web (WWW), electronic mail, telephony, and peer-to-peer networks for file sharing.
The origins of the Internet date back to research commissioned by the United States government in the 1960s to build robust, fault-tolerant communication via computer networks. The primary precursor network, the ARPANET, initially served as a backbone for interconnection of regional academic and military networks in the 1980s.
The funding of the National Science Foundation Network as a new backbone in the 1980s, as well as private funding for other commercial extensions, led to worldwide participation in the development of new networking technologies, and the merger of many networks. The linking of commercial networks and enterprises by the early 1990s marks the beginning of the transition to the modern Internet, and generated a sustained exponential growth as generations of institutional, personal, and mobile computers were connected to the network.
Although the Internet has been widely used by academia since the 1980s, the commercialization incorporated its services and technologies into virtually every aspect of modern life.
Internet use grew rapidly in the West from the mid-1990s and from the late 1990s in the developing world. In the 20 years since 1995, Internet use has grown 100-times, measured for the period of one year, to over one third of the world population.
Most traditional communications media, including telephony and television, are being reshaped or redefined by the Internet, giving birth to new services such as Internet telephony and Internet television. Newspaper, book, and other print publishing are adapting to website technology, or are reshaped into blogging and web feeds.
The entertainment industry was initially the fastest growing segment on the Internet. The Internet has enabled and accelerated new forms of personal interactions through instant messaging, Internet forums, and social networking. Online shopping has grown exponentially both for major retailers and small artisans and traders. Business-to-business and financial services on the Internet affect supply chains across entire industries.
The Internet has no centralized governance in either technological implementation or policies for access and usage; each constituent network sets its own policies. Only the overreaching definitions of the two principal name spaces in the Internet, the Internet Protocol address space and the Domain Name System (DNS), are directed by a maintainer organization, the Internet Corporation for Assigned Names and Numbers (ICANN).
The technical underpinning and standardization of the core protocols is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise.
(For more detailed information about the Internet, click here)
___________________________________________________________________________
The history of the Internet begins with the development of electronic computers in the 1950s. Initial concepts of packet networking originated in several computer science laboratories in the United States, United Kingdom, and France.
The US Department of Defense awarded contracts as early as the 1960s for packet network systems, including the development of the ARPANET. The first message was sent over the ARPANET from computer science Professor Leonard Kleinrock's laboratory at University of California, Los Angeles (UCLA) to the second network node at Stanford Research. Institute (SRI).
Packet switching networks such as ARPANET, NPL network, CYCLADES, Merit Network, Tymnet, and Telenet, were developed in the late 1960s and early 1970s using a variety of communications protocols. Donald Davies first designed a packet-switched network at the National Physics Laboratory in the UK, which became a testbed for UK research for almost two decades.
The ARPANET project led to the development of protocols for internetworking, in which multiple separate networks could be joined into a network of networks.
Access to the ARPANET was expanded in 1981 when the National Science Foundation (NSF) funded the Computer Science Network (CSNET). In 1982, the Internet protocol suite (TCP/IP) was introduced as the standard networking protocol on the ARPANET.
In the early 1980s the NSF funded the establishment for national supercomputing centers at several universities, and provided interconnectivity in 1986 with the NSFNET project, which also created network access to the supercomputer sites in the United States from research and education organizations. Commercial Internet service providers (ISPs) began to emerge in the very late 1980s.
The ARPANET was decommissioned in 1990. Limited private connections to parts of the Internet by officially commercial entities emerged in several American cities by late 1989 and 1990, and the NSFNET was decommissioned in 1995, removing the last restrictions on the use of the Internet to carry commercial traffic.
In the 1980s, research at CERN in Switzerland by British computer scientist Tim Berners-Lee resulted in the World Wide Web, linking hypertext documents into an information system, accessible from any node on the network.
Since the mid-1990s, the Internet has had a revolutionary impact on culture, commerce, and technology, including the rise of near-instant communication by electronic mail, instant messaging, voice over Internet Protocol (VoIP) telephone calls, two-way interactive video calls, and the World Wide Web with its discussion forums, blogs, social networking, and online shopping sites.
The research and education community continues to develop and use advanced networks such as NSF's very high speed Backbone Network Service (vBNS), Internet2, and National LambdaRail.
Increasing amounts of data are transmitted at higher and higher speeds over fiber optic networks operating at 1-Gbit/s, 10-Gbit/s, or more. The Internet's takeover of the global communication landscape was almost instant in historical terms: it only communicated 1% of the information flowing through two-way telecommunications networks in the year 1993, already 51% by 2000, and more than 97% of the telecommunicated information by 2007.
Today the Internet continues to grow, driven by ever greater amounts of online information, commerce, entertainment, and social networking.
Click here further information about the History of the Internet.
___________________________________________________________________________
Internet access is the process that enables individuals and organisations to connect to the Internet using computer terminals, computers, mobile devices, sometimes via computer networks.
Once connected to the Internet, users can access Internet services, such as email and the World Wide Web. Internet service providers (ISPs) offer Internet access through various technologies that offer a wide range of data signaling rates (speeds).
Consumer use of the Internet first became popular through dial-up Internet access in the 1990s. By the first decade of the 21st century, many consumers in developed nations used faster, broadband Internet access technologies. By 2014 this was almost ubiquitous worldwide, with a global average connection speed exceeding 4 Mbit/s.
Click here for more about Internet Access.
___________________________________________________________________________
The Internet Protocol (IP) is the principal communications protocol in the Internet protocol suite for relaying datagrams across network boundaries. Its routing function enables internetworking, and essentially establishes the Internet.
IP has the task of delivering packets from the source host to the destination host solely based on the IP addresses in the packet headers. For this purpose, IP defines packet structures that encapsulate the data to be delivered. It also defines addressing methods that are used to label the datagram with source and destination information.
Historically, IP was the connectionless datagram service in the original Transmission Control Program introduced by Vint Cerf and Bob Kahn in 1974; the other being the connection-oriented Transmission Control Protocol (TCP). The Internet protocol suite is therefore often referred to as TCP/IP.
The first major version of IP, Internet Protocol Version 4 (IPv4), is the dominant protocol of the Internet. Its successor is Internet Protocol Version 6 (IPv6).
Click here for more about Internet Protocol.
___________________________________________________________________________
A List of the World's Largest Internet Companies:
This is a list of the world's largest internet companies by revenue and market capitalization.
The list is restricted to dot-com companies, defined as a company that does the majority of its business on the Internet, with annual revenues exceeding 1 billion USD. It excludes Internet service providers or other information technology companies. For a more general list of IT companies, see list of the largest information technology companies.
Click here for a listing of the Largest Internet Companies based on revenues.
Glossary of Internet-related Terms
YouTube Video: Humorous Take by "Tonight with John Oliver: Net Neutrality (HBO)"
Pictured: Internet terms as a Crossword Puzzle
Click on the above link "Glossary of Internet-related Terms" for an alphabetical listed glossary of Internet Terms.
Listing of Online Retailers based in the United States
YouTube Video: Jeff Bezos* 7 Rules of Success | Amazon.com founder | inspirational speech
*- Jeff Bezos is the founder of Amazon.com
Pictured: Shopping online at Walmart.com

Online Digital Libraries
Wikipedia Library Database
YouTube Video: Transforming Tutorials: Tips to Make Digital Library Videos More Engaging and Accessible Online

[RE: YouTube Video (above): This presentation will show how to use the new TED-Ed tool to increase engagement, participation, and retention of concepts covered in library videos. The presentation will also showcase how library videos can be embedded in popular platforms such as LibGuides, Blackboard or social networking websites to reach a wider audience. Finally, the presentation will comment on how the YouTube hosting platform supports.]
Click here to access the Wikipedia Online Library
A digital library is a special library with a focused collection of digital objects that can include text, visual material, audio material, video material, stored as electronic media formats (as opposed to print, microform, or other media), along with means for organizing, storing, and retrieving the files and media contained in the library collection.
Digital libraries can vary immensely in size and scope, and can be maintained by individuals, organizations, or affiliated with established physical library buildings or institutions, or with academic institutions.
The digital content may be stored locally, or accessed remotely via computer networks. An electronic library is a type of information retrieval system.
For amplification, click on any of the following:
Click here to access the Wikipedia Online Library
A digital library is a special library with a focused collection of digital objects that can include text, visual material, audio material, video material, stored as electronic media formats (as opposed to print, microform, or other media), along with means for organizing, storing, and retrieving the files and media contained in the library collection.
Digital libraries can vary immensely in size and scope, and can be maintained by individuals, organizations, or affiliated with established physical library buildings or institutions, or with academic institutions.
The digital content may be stored locally, or accessed remotely via computer networks. An electronic library is a type of information retrieval system.
For amplification, click on any of the following:
- 1 Software implementation
- 2 History
- 3 Terminology
- 4 Academic repositories
- 5 Digital archives
- 6 The future
- 7 Searching
- 8 Advantages
- 9 Disadvantages
- 10 See also
- 11 References
- 12 Further reading
- 13 External links
TED (Technology, Entertainment, Design)
YouTube Video: The 20 Most-Watched TEDTalks

Click here to visit TED.COM website.
TED (Technology, Entertainment, Design) is a global set of conferences run by the private nonprofit organization Sapling Foundation, under the slogan "Ideas Worth Spreading".
TED was founded in February 1984 as a one-off event. The annual conference series began in 1990.
TED's early emphasis was technology and design, consistent with its Silicon Valley origins, but it has since broadened its focus to include talks on many scientific, cultural, and academic topics.
The main TED conference is held annually in Vancouver, British Columbia, Canada and its companion TEDActive is held in the neighboring city of Whistler. Prior to 2014, the two conferences were held in Long Beach and Palm Springs, California, respectively.
TED events are also held throughout North America and in Europe and Asia, offering live streaming of the talks. They address a wide range of topics within the research and practice of science and culture, often through storytelling.
The speakers are given a maximum of 18 minutes to present their ideas in the most innovative and engaging ways they can.
Past speakers include:
TED's current curator is the British former computer journalist and magazine publisher Chris Anderson.
As of March 2016, over 2,400 talks are freely available on the website. In June 2011, the talks' combined viewing figure stood at more than 500 million, and by November 2012, TED talks had been watched over one billion times worldwide.
Not all TED talks are equally popular, however. Those given by academics tend to be watched more online, and art and design videos tend to be watched less than average.
Click on any of the following blue hyperlinks for more about TED (Conference):
TED (Technology, Entertainment, Design) is a global set of conferences run by the private nonprofit organization Sapling Foundation, under the slogan "Ideas Worth Spreading".
TED was founded in February 1984 as a one-off event. The annual conference series began in 1990.
TED's early emphasis was technology and design, consistent with its Silicon Valley origins, but it has since broadened its focus to include talks on many scientific, cultural, and academic topics.
The main TED conference is held annually in Vancouver, British Columbia, Canada and its companion TEDActive is held in the neighboring city of Whistler. Prior to 2014, the two conferences were held in Long Beach and Palm Springs, California, respectively.
TED events are also held throughout North America and in Europe and Asia, offering live streaming of the talks. They address a wide range of topics within the research and practice of science and culture, often through storytelling.
The speakers are given a maximum of 18 minutes to present their ideas in the most innovative and engaging ways they can.
Past speakers include:
- Bill Clinton,
- Jane Goodall,
- Al Gore,
- Gordon Brown,
- Billy Graham,
- Richard Dawkins,
- Richard Stallman,
- Bill Gates,
- Bono,
- Mike Rowe,
- Google founders Larry Page and Sergey Brin,
- and many Nobel Prize winners.
TED's current curator is the British former computer journalist and magazine publisher Chris Anderson.
As of March 2016, over 2,400 talks are freely available on the website. In June 2011, the talks' combined viewing figure stood at more than 500 million, and by November 2012, TED talks had been watched over one billion times worldwide.
Not all TED talks are equally popular, however. Those given by academics tend to be watched more online, and art and design videos tend to be watched less than average.
Click on any of the following blue hyperlinks for more about TED (Conference):
Internet Content Management Systems (Web CMS)
YouTube Video: Web Content Management Explained
Pictured: Illustration of the process for Web CMS
A web content management system (WCMS) is a software system that provides website authoring, collaboration, and administration tools designed to allow users with little knowledge of web programming languages or markup languages to create and manage website content with relative ease.
A robust Web Content Management System provides the foundation for collaboration, offering users the ability to manage documents and output for multiple author editing and participation.
Most systems use a content repository or a database to store page content, metadata, and other information assets that might be needed by the system.
A presentation layer (template engine) displays the content to website visitors based on a set of templates, which are sometimes XSLT files.
Most systems use server side caching to improve performance. This works best when the WCMS is not changed often but visits happen regularly.
Administration is also typically done through browser-based interfaces, but some systems require the use of a fat client.
A WCMS allows non-technical users to make changes to a website with little training. A WCMS typically requires a systems administrator and/or a web developer to set up and add features, but it is primarily a website maintenance tool for non-technical staff.
Capabilities:
A web content management system is used to control a dynamic collection of web material, including HTML documents, images, and other forms of media. A CMS facilitates document control, auditing, editing, and timeline management. A WCMS typically has the following features:
Automated templates:
Create standard templates (usually HTML and XML) that can be automatically applied to new and existing content, allowing the appearance of all content to be changed from one central place.
Access control:
Some WCMS systems support user groups. User groups allow you to control how registered users interact with the site. A page on the site can be restricted to one or more groups. This means an anonymous user (someone not logged on), or a logged on user who is not a member of the group a page is restricted to, will be denied access to the page.
Scalable expansion:
Available in most modern WCMSs is the ability to expand a single implementation (one installation on one server) across multiple domains, depending on the server's settings.
WCMS sites may be able to create microsites/web portals within a main site as well.
Easily editable content:
Once content is separated from the visual presentation of a site, it usually becomes much easier and quicker to edit and manipulate. Most WCMS software includes WYSIWYG editing tools allowing non-technical users to create and edit content.
Scalable feature sets:
Most WCMS software includes plug-ins or modules that can be easily installed to extend an existing site's functionality.
Web standards upgrades:
Active WCMS software usually receives regular updates that include new feature sets and keep the system up to current web standards.
Workflow management:
Workflow is the process of creating cycles of sequential and parallel tasks that must be accomplished in the CMS. For example, one or many content creators can submit a story, but it is not published until the copy editor cleans it up and the editor-in-chief approves it.
Collaboration:
CMS software may act as a collaboration platform allowing content to be retrieved and worked on by one or many authorized users. Changes can be tracked and authorized for publication or ignored reverting to old versions. Other advanced forms of collaboration allow multiple users to modify (or comment) a page at the same time in a collaboration session.
Delegation:
Some CMS software allows for various user groups to have limited privileges over specific content on the website, spreading out the responsibility of content management.
Document management:
CMS software may provide a means of collaboratively managing the life cycle of a document from initial creation time, through revisions, publication, archive, and document destruction.
Content virtualization:
CMS software may provide a means of allowing each user to work within a virtual copy of the entire web site, document set, and/or code base. This enables changes to multiple interdependent resources to be viewed and/or executed in-context prior to submission.
Content syndication:
CMS software often assists in content distribution by generating RSS and Atom data feeds to other systems. They may also e-mail users when updates are available as part of the workflow process.
Multilingual:
Ability to display content in multiple languages.
Versioning:
Like document management systems, CMS software may allow the process of versioning by which pages are checked in or out of the WCMS, allowing authorized editors to retrieve previous versions and to continue work from a selected point. Versioning is useful for content that changes over time and requires updating, but it may be necessary to go back to or reference a previous copy.
Types: There are three major types of WCMS: offline processing, online processing, and hybrid systems. These terms describe the deployment pattern for the WCMS in terms of when presentation templates are applied to render web pages from structured content.
Offline processing: These systems, sometimes referred to as "static site generators", pre-process all content, applying templates before publication to generate web pages. Since pre-processing systems do not require a server to apply the templates at request time, they may also exist purely as design-time tools.
Online processing:These systems apply templates on-demand. HTML may be generated when a user visits the page or it is pulled from a web cache.
Most open source WCMSs have the capability to support add-ons, which provide extended capabilities including forums, blog, wiki, web stores, photo galleries, contact management, etc. These are often called modules, nodes, widgets, add-ons, or extensions.
Hybrid systems: Some systems combine the offline and online approaches. Some systems write out executable code (e.g., JSP, ASP, PHP, ColdFusion, or Perl pages) rather than just static HTML, so that the CMS itself does not need to be deployed on every web server. Other hybrids operate in either an online or offline mode.
Advantages:
Low cost:
Some content management systems are free, such as Drupal, eZ Publish, TYPO3, Joomla, and WordPress. Others may be affordable based on size subscriptions. Although subscriptions can be expensive, overall the cost of not having to hire full-time developers can lower the total costs. Plus software can be bought based on need for many CMSs.
Easy customization:
A universal layout is created, making pages have a similar theme and design without much code. Many CMS tools use a drag and drop AJAX system for their design modes. It makes it easy for beginner users to create custom front-ends.
Easy to use:
CMSs are designed with non-technical people in mind. Simplicity in design of the admin UI allows website content managers and other users to update content without much training in coding or technical aspects of system maintenance.
Workflow management:
CMSs provide the facility to control how content is published, when it is published, and who publishes it. Some WCMSs allow administrators to set up rules for workflow management, guiding content managers through a series of steps required for each of their tasks.
Good For SEO:
CMS websites are also good for search engine optimization (SEO).
Freshness of content is one factor that helps, as it is believed that some search engines give preference to website with new and updated content than websites with stale and outdated content.
Usage of social media plugins help in weaving a community around your blog. RSS feeds which are automatically generated by blogs or CMS websites can increase the number of subscribers and readers to your site.
Url rewriting can be implemented easily which produces clean urls without parameters which further help in seo. There are plugins available that specifically help with website.
SEO Disadvantages:
Cost of implementations:
Larger scale implementations may require training, planning, and certifications. Certain CMSs may require hardware installations. Commitment to the software is required on bigger investments. Commitment to training, developing, and upkeep are all costs that will be incurred for enterprise systems.
Cost of maintenance:
Maintaining CMSs may require license updates, upgrades, and hardware maintenance.
Latency issues:
Larger CMSs can experience latency if hardware infrastructure is not up to date, if databases are not being utilized correctly, and if web cache files that have to be reloaded every time data is updated grow large. Load balancing issues may also impair caching files.
Tool mixing:
Because the URLs of many CMSs are dynamically generated with internal parameters and reference information, they are often not stable enough for static pages and other web tools, particularly search engines, to rely on them.
Security:
CMS's are often forgotten about when hardware, software, and operating systems are patched for security threats. Due to lack of patching by the user, a hacker can use unpatched CMS software to exploit vulnerabilities to enter an otherwise secure environment. CMS's should be part of an overall, holistic security patch management program to maintain the highest possible security standards.
Notable web CMS:
See also: List of content management systems
Some notable examples of CMS:
See also:
A robust Web Content Management System provides the foundation for collaboration, offering users the ability to manage documents and output for multiple author editing and participation.
Most systems use a content repository or a database to store page content, metadata, and other information assets that might be needed by the system.
A presentation layer (template engine) displays the content to website visitors based on a set of templates, which are sometimes XSLT files.
Most systems use server side caching to improve performance. This works best when the WCMS is not changed often but visits happen regularly.
Administration is also typically done through browser-based interfaces, but some systems require the use of a fat client.
A WCMS allows non-technical users to make changes to a website with little training. A WCMS typically requires a systems administrator and/or a web developer to set up and add features, but it is primarily a website maintenance tool for non-technical staff.
Capabilities:
A web content management system is used to control a dynamic collection of web material, including HTML documents, images, and other forms of media. A CMS facilitates document control, auditing, editing, and timeline management. A WCMS typically has the following features:
Automated templates:
Create standard templates (usually HTML and XML) that can be automatically applied to new and existing content, allowing the appearance of all content to be changed from one central place.
Access control:
Some WCMS systems support user groups. User groups allow you to control how registered users interact with the site. A page on the site can be restricted to one or more groups. This means an anonymous user (someone not logged on), or a logged on user who is not a member of the group a page is restricted to, will be denied access to the page.
Scalable expansion:
Available in most modern WCMSs is the ability to expand a single implementation (one installation on one server) across multiple domains, depending on the server's settings.
WCMS sites may be able to create microsites/web portals within a main site as well.
Easily editable content:
Once content is separated from the visual presentation of a site, it usually becomes much easier and quicker to edit and manipulate. Most WCMS software includes WYSIWYG editing tools allowing non-technical users to create and edit content.
Scalable feature sets:
Most WCMS software includes plug-ins or modules that can be easily installed to extend an existing site's functionality.
Web standards upgrades:
Active WCMS software usually receives regular updates that include new feature sets and keep the system up to current web standards.
Workflow management:
Workflow is the process of creating cycles of sequential and parallel tasks that must be accomplished in the CMS. For example, one or many content creators can submit a story, but it is not published until the copy editor cleans it up and the editor-in-chief approves it.
Collaboration:
CMS software may act as a collaboration platform allowing content to be retrieved and worked on by one or many authorized users. Changes can be tracked and authorized for publication or ignored reverting to old versions. Other advanced forms of collaboration allow multiple users to modify (or comment) a page at the same time in a collaboration session.
Delegation:
Some CMS software allows for various user groups to have limited privileges over specific content on the website, spreading out the responsibility of content management.
Document management:
CMS software may provide a means of collaboratively managing the life cycle of a document from initial creation time, through revisions, publication, archive, and document destruction.
Content virtualization:
CMS software may provide a means of allowing each user to work within a virtual copy of the entire web site, document set, and/or code base. This enables changes to multiple interdependent resources to be viewed and/or executed in-context prior to submission.
Content syndication:
CMS software often assists in content distribution by generating RSS and Atom data feeds to other systems. They may also e-mail users when updates are available as part of the workflow process.
Multilingual:
Ability to display content in multiple languages.
Versioning:
Like document management systems, CMS software may allow the process of versioning by which pages are checked in or out of the WCMS, allowing authorized editors to retrieve previous versions and to continue work from a selected point. Versioning is useful for content that changes over time and requires updating, but it may be necessary to go back to or reference a previous copy.
Types: There are three major types of WCMS: offline processing, online processing, and hybrid systems. These terms describe the deployment pattern for the WCMS in terms of when presentation templates are applied to render web pages from structured content.
Offline processing: These systems, sometimes referred to as "static site generators", pre-process all content, applying templates before publication to generate web pages. Since pre-processing systems do not require a server to apply the templates at request time, they may also exist purely as design-time tools.
Online processing:These systems apply templates on-demand. HTML may be generated when a user visits the page or it is pulled from a web cache.
Most open source WCMSs have the capability to support add-ons, which provide extended capabilities including forums, blog, wiki, web stores, photo galleries, contact management, etc. These are often called modules, nodes, widgets, add-ons, or extensions.
Hybrid systems: Some systems combine the offline and online approaches. Some systems write out executable code (e.g., JSP, ASP, PHP, ColdFusion, or Perl pages) rather than just static HTML, so that the CMS itself does not need to be deployed on every web server. Other hybrids operate in either an online or offline mode.
Advantages:
Low cost:
Some content management systems are free, such as Drupal, eZ Publish, TYPO3, Joomla, and WordPress. Others may be affordable based on size subscriptions. Although subscriptions can be expensive, overall the cost of not having to hire full-time developers can lower the total costs. Plus software can be bought based on need for many CMSs.
Easy customization:
A universal layout is created, making pages have a similar theme and design without much code. Many CMS tools use a drag and drop AJAX system for their design modes. It makes it easy for beginner users to create custom front-ends.
Easy to use:
CMSs are designed with non-technical people in mind. Simplicity in design of the admin UI allows website content managers and other users to update content without much training in coding or technical aspects of system maintenance.
Workflow management:
CMSs provide the facility to control how content is published, when it is published, and who publishes it. Some WCMSs allow administrators to set up rules for workflow management, guiding content managers through a series of steps required for each of their tasks.
Good For SEO:
CMS websites are also good for search engine optimization (SEO).
Freshness of content is one factor that helps, as it is believed that some search engines give preference to website with new and updated content than websites with stale and outdated content.
Usage of social media plugins help in weaving a community around your blog. RSS feeds which are automatically generated by blogs or CMS websites can increase the number of subscribers and readers to your site.
Url rewriting can be implemented easily which produces clean urls without parameters which further help in seo. There are plugins available that specifically help with website.
SEO Disadvantages:
Cost of implementations:
Larger scale implementations may require training, planning, and certifications. Certain CMSs may require hardware installations. Commitment to the software is required on bigger investments. Commitment to training, developing, and upkeep are all costs that will be incurred for enterprise systems.
Cost of maintenance:
Maintaining CMSs may require license updates, upgrades, and hardware maintenance.
Latency issues:
Larger CMSs can experience latency if hardware infrastructure is not up to date, if databases are not being utilized correctly, and if web cache files that have to be reloaded every time data is updated grow large. Load balancing issues may also impair caching files.
Tool mixing:
Because the URLs of many CMSs are dynamically generated with internal parameters and reference information, they are often not stable enough for static pages and other web tools, particularly search engines, to rely on them.
Security:
CMS's are often forgotten about when hardware, software, and operating systems are patched for security threats. Due to lack of patching by the user, a hacker can use unpatched CMS software to exploit vulnerabilities to enter an otherwise secure environment. CMS's should be part of an overall, holistic security patch management program to maintain the highest possible security standards.
Notable web CMS:
See also: List of content management systems
Some notable examples of CMS:
- WordPress originated as a blogging CMS, but has been adapted into a full-fledged CMS.
- Textpattern is one of the first open source CMS.
- Joomla! is a popular content management system.
- TYPO3 is one of the most used open source enterprise class CMS.
- Drupal is the third most used CMS and originated before WordPress and Joomla.
- Expression Engine is in the top 5 most used CMSs. It is a commercial CMS made by EllisLab.
- MediaWiki powers Wikipedia and related projects, and is one of the most prominent examples of a wiki CMS.
- Magnolia CMS
- eXo Platform Open Source Social CMS
- Liferay Open Source Portal WCMS
- TWiki Open Source Structured wiki CMS
- Foswiki Open Source Structured wiki CMS
- HP TeamSite
- SoNET Web Engine
- EpiServer
- FileNet
- OpenText Web Experience Management
See also:
Web Browsers: click on topic hyperlinks below (in bold underline blue):
YouTube Video: Edge vs Chrome v Firefox - 2016 Visual Comparison of Web Browsers
Pictured: Web browsers and the date each became commercially available

Click Here for A List of Web Browsers
Click Here for a Comparison of Web Browsers as tables that compare general and technical information. Please see the individual products' articles for further information.
Click Here for Usage Share of Web Browsers.
A web browser (commonly referred to as a browser) is a software application for retrieving, presenting, and traversing information resources on the World Wide Web.
An information resource is identified by a Uniform Resource Identifier (URI/URL) and may be a web page, image, video or other piece of content. Hyperlinks present in resources enable users easily to navigate their browsers to related resources.
Although browsers are primarily intended to use the World Wide Web, they can also be used to access information provided by web servers in private networks or files in file systems.
The major web browsers are Firefox, Internet Explorer/Microsoft Edge, Google Chrome, Opera, and Safari.
Click on any of the following blue hyperlinks for more information about Web Browsers:
Click Here for a Comparison of Web Browsers as tables that compare general and technical information. Please see the individual products' articles for further information.
Click Here for Usage Share of Web Browsers.
A web browser (commonly referred to as a browser) is a software application for retrieving, presenting, and traversing information resources on the World Wide Web.
An information resource is identified by a Uniform Resource Identifier (URI/URL) and may be a web page, image, video or other piece of content. Hyperlinks present in resources enable users easily to navigate their browsers to related resources.
Although browsers are primarily intended to use the World Wide Web, they can also be used to access information provided by web servers in private networks or files in file systems.
The major web browsers are Firefox, Internet Explorer/Microsoft Edge, Google Chrome, Opera, and Safari.
Click on any of the following blue hyperlinks for more information about Web Browsers:
Web Search Engines including a List of Search Engines
YouTube Video: How Search Works (by Google)
For a tutorial on using search engines for researching Wikipedia articles, Click here: Wikipedia:Search engine test.
Pictured: Logos of Major Search Engines

Click here for a List of Search Engines
A web search engine is a software system that is designed to search for information on the World Wide Web.
The search results are generally presented in a line of results often referred to as search engine results pages (SERPs).
The information may be a mix of web pages, images, and other types of files. Some search engines also mine data available in databases or open directories.
Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler.
For further information about web search engines, click on any of the following blue hyperlinks:
A web search engine is a software system that is designed to search for information on the World Wide Web.
The search results are generally presented in a line of results often referred to as search engine results pages (SERPs).
The information may be a mix of web pages, images, and other types of files. Some search engines also mine data available in databases or open directories.
Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler.
For further information about web search engines, click on any of the following blue hyperlinks:
- History
- How web search engines work
- Market share
- Search engine bias
- Customized results and filter bubbles
- Christian, Islamic and Jewish search engines
- Search engine submission
- See also:
Search Engine Optimization (SEO) including Search Engine Results Page (SERP)
YouTube Video: What Is Search Engine Optimization / SEO
YouTube Video: 5 Hours of SEO | Zero-Click Searches, SERP Features, and Getting Traffic
Pictured: Illustration of the SEO Process
Search engine optimization (SEO) is the process of affecting the visibility of a website or a web page in a web search engine's unpaid results — often referred to as "natural," "organic," or "earned" results.
In general, the earlier (or higher ranked on the search results page), and more frequently a site appears in the search results list, the more visitors it will receive from the search engine's users, and these visitors can be converted into customers.
SEO may target different kinds of search, including image search, local search, video search, academic search, news search and industry-specific vertical search engines.
As an Internet marketing strategy, SEO considers how search engines work, what people search for, the actual search terms or keywords typed into search engines and which search engines are preferred by their targeted audience.
Optimizing a website may involve editing its content, HTML and associated coding to both increase its relevance to specific keywords and to remove barriers to the indexing activities of search engines.
Promoting a site to increase the number of backlinks, or inbound links, is another SEO tactic. As of May 2015, mobile search has finally surpassed desktop search, Google is developing and pushing mobile search as the future in all of its products and many brands are beginning to take a different approach on their internet strategies.
Google's Role in SEO:
In 1998, Graduate students at Stanford University, Larry Page and Sergey Brin, developed "Backrub," a search engine that relied on a mathematical algorithm to rate the prominence of web pages. The number calculated by the algorithm, PageRank, is a function of the quantity and strength of inbound links.
PageRank estimates the likelihood that a given page will be reached by a web user who randomly surfs the web, and follows links from one page to another. In effect, this means that some links are stronger than others, as a higher PageRank page is more likely to be reached by the random surfer.
Page and Brin founded Google in 1998. Google attracted a loyal following among the growing number of Internet users, who liked its simple design. Off-page factors (such as PageRank and hyperlink analysis) were considered as well as on-page factors (such as keyword frequency, meta tags, headings, links and site structure) to enable Google to avoid the kind of manipulation seen in search engines that only considered on-page factors for their rankings.
Although PageRank was more difficult to game, webmasters had already developed link building tools and schemes to influence the Inktomi search engine, and these methods proved similarly applicable to gaming PageRank. Many sites focused on exchanging, buying, and selling links, often on a massive scale. Some of these schemes, or link farms, involved the creation of thousands of sites for the sole purpose of link spamming.
By 2004, search engines had incorporated a wide range of undisclosed factors in their ranking algorithms to reduce the impact of link manipulation. In June 2007, The New York Times' Saul Hansell stated Google ranks sites using more than 200 different signals.The leading search engines, Google, Bing, and Yahoo, do not disclose the algorithms they use to rank pages.
Some SEO practitioners have studied different approaches to search engine optimization, and have shared their personal opinions. Patents related to search engines can provide information to better understand search engines.
In 2005, Google began personalizing search results for each user. Depending on their history of previous searches, Google crafted results for logged in users. In 2008, Bruce Clay said that "ranking is dead" because of personalized search. He opined that it would become meaningless to discuss how a website ranked, because its rank would potentially be different for each user and each search.
In 2007, Google announced a campaign against paid links that transfer PageRank. On June 15, 2009, Google disclosed that they had taken measures to mitigate the effects of PageRank sculpting by use of the no follow attribute on links. Matt Cutts, a well-known software engineer at Google, announced that Google Bot would no longer treat no-followed links in the same way, in order to prevent SEO service providers from using no-follow for PageRank sculpting.
As a result of this change the usage of nofollow leads to evaporation of pagerank. In order to avoid the above, SEO engineers developed alternative techniques that replace nofollowed tags with obfuscated Javascript and thus permit PageRank sculpting.
Additionally several solutions have been suggested that include the usage of iframes, Flash and Javascript.
In December 2009, Google announced it would be using the web search history of all its users in order to populate search results.
On June 8, 2010 a new web indexing system called Google Caffeine was announced. Designed to allow users to find news results, forum posts and other content much sooner after publishing than before, Google caffeine was a change to the way Google updated its index in order to make things show up quicker on Google than before. According to Carrie Grimes, the software engineer who announced Caffeine for Google, "Caffeine provides 50 percent fresher results for web searches than our last index..."
Google Instant, real-time-search, was introduced in late 2010 in an attempt to make search results more timely and relevant. Historically site administrators have spent months or even years optimizing a website to increase search rankings. With the growth in popularity of social media sites and blogs the leading engines made changes to their algorithms to allow fresh content to rank quickly within the search results.
In February 2011, Google announced the Panda update, which penalizes websites containing content duplicated from other websites and sources. Historically websites have copied content from one another and benefited in search engine rankings by engaging in this practice, however Google implemented a new system which punishes sites whose content is not unique.
The 2012 Google Penguin attempted to penalize websites that used manipulative techniques to improve their rankings on the search engine, and the 2013 Google Hummingbird update featured an algorithm change designed to improve Google's natural language processing and semantic understanding of web pages.
Methods
Getting indexed:
The leading search engines, such as Google, Bing and Yahoo!, use crawlers to find pages for their algorithmic search results. Pages that are linked from other search engine indexed pages do not need to be submitted because they are found automatically. Two major directories, the Yahoo Directory and DMOZ, both require manual submission and human editorial review.
Google offers Google Search Console, for which an XML Sitemap feed can be created and submitted for free to ensure that all pages are found, especially pages that are not discoverable by automatically following links in addition to their URL submission console. Yahoo! formerly operated a paid submission service that guaranteed crawling for a cost per click; this was discontinued in 2009.
Search engine crawlers may look at a number of different factors when crawling a site. Not every page is indexed by the search engines. Distance of pages from the root directory of a site may also be a factor in whether or not pages get crawled.
Preventing crawling:
Main article: Robots Exclusion Standard
To avoid undesirable content in the search indexes, webmasters can instruct spiders not to crawl certain files or directories through the standard robots.txt file in the root directory of the domain. Additionally, a page can be explicitly excluded from a search engine's database by using a meta tag specific to robots.
When a search engine visits a site, the robots.txt located in the root directory is the first file crawled. The robots.txt file is then parsed, and will instruct the robot as to which pages are not to be crawled. As a search engine crawler may keep a cached copy of this file, it may on occasion crawl pages a webmaster does not wish crawled.
Pages typically prevented from being crawled include login specific pages such as shopping carts and user-specific content such as search results from internal searches. In March 2007, Google warned webmasters that they should prevent indexing of internal search results because those pages are considered search spam.
Increasing prominence:
A variety of methods can increase the prominence of a webpage within the search results. Cross linking between pages of the same website to provide more links to important pages may improve its visibility.
Writing content that includes frequently searched keyword phrase, so as to be relevant to a wide variety of search queries will tend to increase traffic. Updating content so as to keep search engines crawling back frequently can give additional weight to a site.
Adding relevant keywords to a web page's meta data, including the title tag and meta description, will tend to improve the relevancy of a site's search listings, thus increasing traffic. URL normalization of web pages accessible via multiple urls, using the canonical link element or via 301 redirects can help make sure links to different versions of the URL all count towards the page's link popularity score.
White hat versus black hat techniques:
SEO techniques can be classified into two broad categories: techniques that search engines recommend as part of good design, and those techniques of which search engines do not approve. The search engines attempt to minimize the effect of the latter, among them spamdexing. Industry commentators have classified these methods, and the practitioners who employ them, as either white hat SEO, or black hat SEO.
White hats tend to produce results that last a long time, whereas black hats anticipate that their sites may eventually be banned either temporarily or permanently once the search engines discover what they are doing.
An SEO technique is considered white hat if it conforms to the search engines' guidelines and involves no deception. As the search engine guidelines are not written as a series of rules or commandments, this is an important distinction to note. White hat SEO is not just about following guidelines, but is about ensuring that the content a search engine indexes and subsequently ranks is the same content a user will see.
White hat advice is generally summed up as creating content for users, not for search engines, and then making that content easily accessible to the spiders, rather than attempting to trick the algorithm from its intended purpose. White hat SEO is in many ways similar to web development that promotes accessibility, although the two are not identical.
Black hat SEO attempts to improve rankings in ways that are disapproved of by the search engines, or involve deception. One black hat technique uses text that is hidden, either as text colored similar to the background, in an invisible div, or positioned off screen. Another method gives a different page depending on whether the page is being requested by a human visitor or a search engine, a technique known as cloaking.
Another category sometimes used is grey hat SEO. This is in between black hat and white hat approaches where the methods employed avoid the site being penalized however do not act in producing the best content for users, rather entirely focused on improving search engine rankings.
Search engines may penalize sites they discover using black hat methods, either by reducing their rankings or eliminating their listings from their databases altogether. Such penalties can be applied either automatically by the search engines' algorithms, or by a manual site review.
One example was the February 2006 Google removal of both BMW Germany and Ricoh Germany for use of deceptive practices. Both companies, however, quickly apologized, fixed the offending pages, and were restored to Google's list.
As a marketing strategy, SEO is not an appropriate strategy for every website, and other Internet marketing strategies can be more effective like paid advertising through pay per click (PPC) campaigns, depending on the site operator's goals.
A successful Internet marketing campaign may also depend upon building high quality web pages to engage and persuade, setting up analytics programs to enable site owners to measure results, and improving a site's conversion rate.
In November 2015, Google released a full 160 page version of its Search Quality Rating Guidelines to the public, which now shows a shift in their focus towards "usefulness" and mobile search.
SEO may generate an adequate return on investment. However, search engines are not paid for organic search traffic, their algorithms change, and there are no guarantees of continued referrals. Due to this lack of guarantees and certainty, a business that relies heavily on search engine traffic can suffer major losses if the search engines stop sending visitors. Search engines can change their algorithms, impacting a website's placement, possibly resulting in a serious loss of traffic.
According to Google's CEO, Eric Schmidt, in 2010, Google made over 500 algorithm changes – almost 1.5 per day. It is considered wise business practice for website operators to liberate themselves from dependence on search engine traffic.
In addition to accessibility in terms of web crawlers (addressed above), user web accessibility has become increasingly important for SEO.
International markets:
Optimization techniques are highly tuned to the dominant search engines in the target market. The search engines' market shares vary from market to market, as does competition. In 2003, Danny Sullivan stated that Google represented about 75% of all searches. In markets outside the United States, Google's share is often larger, and Google remains the dominant search engine worldwide as of 2007.
As of 2006, Google had an 85–90% market share in Germany. While there were hundreds of SEO firms in the US at that time, there were only about five in Germany. As of June 2008, the marketshare of Google in the UK was close to 90% according to Hitwise. That market share is achieved in a number of countries.
As of 2009, there are only a few large markets where Google is not the leading search engine. In most cases, when Google is not leading in a given market, it is lagging behind a local player. The most notable example markets are China, Japan, South Korea, Russia and the Czech Republic where respectively Baidu, Yahoo! Japan, Naver, Yandex and Seznam are market leaders.
Successful search optimization for international markets may require professional translation of web pages, registration of a domain name with a top level domain in the target market, and web hosting that provides a local IP address. Otherwise, the fundamental elements of search optimization are essentially the same, regardless of language.
Legal precedents:
On October 17, 2002, SearchKing filed suit in the United States District Court, Western District of Oklahoma, against the search engine Google. SearchKing's claim was that Google's tactics to prevent spamdexing constituted a tortious interference with contractual relations. On May 27, 2003, the court granted Google's motion to dismiss the complaint because SearchKing "failed to state a claim upon which relief may be granted."
In March 2006, KinderStart filed a lawsuit against Google over search engine rankings. Kinderstart's website was removed from Google's index prior to the lawsuit and the amount of traffic to the site dropped by 70%. On March 16, 2007 the United States District Court for the Northern District of California (San Jose Division) dismissed KinderStart's complaint without leave to amend, and partially granted Google's motion for Rule 11 sanctions against KinderStart's attorney, requiring him to pay part of Google's legal expenses.
See also: ___________________________________________________________________________
Search Engine Results Page (SERP)
A search engine results page (SERP) is the page displayed by a web search engine in response to a query by a searcher. The main component of the SERP is the listing of results that are returned by the search engine in response to a keyword query, although the page may also contain other results such as advertisements.
The results are of two general types, organic (i.e., retrieved by the search engine's algorithm) and sponsored (i.e., advertisements). The results are normally ranked by relevance to the query. Each result displayed on the SERP normally includes a title, a link that points to the actual page on the Web and a short description showing where the keywords have matched content within the page for organic results. For sponsored results, the advertiser chooses what to display.
Due to the huge number of items that are available or related to the query there usually are several SERPs in response to a single search query as the search engine or the user's preferences restrict viewing to a subset of results per page. Each succeeding page will tend to have lower ranking or lower relevancy results.
Just like the world of traditional print media and its advertising, this enables competitive pricing for page real estate, but compounded by the dynamics of consumer expectations and intent— unlike static print media where the content and the advertising on every page is the same all of the time for all viewers, despite such hard copy being localized to some degree, usually geographic, like state, metro-area, city, or neighborhoods.
Components:
There are basically four main components of SERP, which are
However, the SERPs of major search engines, like Google, Yahoo!, and Bing, may include many different types of enhanced results (organic search and sponsored) such as rich snippets, images, maps, definitions, answer boxes, videos or suggested search refinements. A recent study revealed that 97% of queries in Google returned at least one rich feature.
The major search engines visually differentiate specific content types such as images, news, and blogs. Many content types have specialized SERP templates and visual enhancements on the main search results page.
Search query:
Also known as 'user search string', this is the word or set of words that are typed by the user in the search bar of the search engine. The search box is located on all major search engines like Google, Yahoo, and Bing. Users indicate the topic desired based on the keywords they enter into the search box in the search engine.
In the competition between search engines to draw the attention of more users and advertisers, consumer satisfaction has been a driving force in the evolution of the search algorithm applied to better filter the results by relevancy.
Search queries are no longer successful based upon merely finding words that match purely by spelling. Intent and expectations have to be derived to determine whether the appropriate result is a match based upon the broader meanings drawn from context.
And that sense of context has grown from simple matching of words, and then of phrases, to the matching of ideas. And the meanings of those ideas change over time and context.
Successful matching can be crowd sourced, what are others currently searching for and clicking on, when one enters keywords related to those other searches. And the crowd sourcing may be focused based upon one's own social networking.
With the advent of portable devices, smartphones, and wearable devices, watches and various sensors, these provide ever more contextual dimensions for consumer and advertiser to refine and maximize relevancy using such additional factors that may be gleaned like:
Social context and crowd sourcing influences can also be pertinent factors.
The move away from keyboard input and the search box to voice access, aside from convenience, also makes other factors available to varying degrees of accuracy and pertinence, like: a person's character, intonation, mood, accent, ethnicity, and even elements overheard from nearby people and the background environment.
Searching is changing from explicit keywords: on TV show w, did x marry y or z, or election results for candidate x in county y for this date z, or final scores for team x in game y for this date z to vocalizing from a particular time and location: hey, so who won. And getting the results that one expects.
Organic results:
Main article: Web search query
Organic SERP listings are the natural listings generated by search engines based on a series of metrics that determines their relevance to the searched term. Webpages that score well on a search engine's algorithmic test show in this list.
These algorithms are generally based upon factors such as the content of a webpage, the trustworthiness of the website, and external factors such as backlinks, social media, news, advertising, etc.
People tend to view the SERP and the first results on each SERP. Each page of search engine results usually contains 10 organic listings (however some results pages may have fewer organic listings).
The listings, which are on the first page are the most important ones, because those get 91% of the click through rates (CTR) from a particular search. According to a 2013 study, the CTR's for the first page goes as:
Sponsored results:
Main article: Search engine marketing § Paid inclusion
Every major search engine with significant market share accepts paid listings. This unique form of search engine advertising guarantees that your site will appear in the top results for the keyword terms you target within a day or less. Paid search listings are also called sponsored listings and/or Pay Per Click (PPC) listings.
Rich snippets:
Rich snippets are displayed by Google in the search results page when a website contains content in structured data markup. Structured data markup helps the Google algorithm to index and understand the content better. Google supports rich snippets for the following data types:
Knowledge Graph:
Search engines like Google or Bing have started to expand their data into encyclopedias and other rich sources of information.
Google for example calls this sort of information "Knowledge Graph", if a search query matches it will display an additional sub-window on right hand side with information from its sources.
Information about hotels, events, flights, places, businesses, people, books and movies, countries, sport groups, architecture and more can be obtained that way.
Generation:
Major search engines like Google, Yahoo!, and Bing primarily use content contained within the page and fallback to metadata tags of a web page to generate the content that makes up a search snippet. Generally, the HTML title tag will be used as the title of the snippet while the most relevant or useful contents of the web page (description tag or page copy) will be used for the description.
Scraping and automated access:
Search engine result pages are protected from automated access by a range of defensive mechanisms and the terms of service. These result pages are the primary data source for SEO companies, the website placement for competitive keywords became an important field of business and interest. Google has even used twitter to warn users against this practice.
The sponsored (creative) results on Google can cost an large amount of money for advertisers, a few of which pay Google nearly 1000 USD for each sponsored click.
The process of harvesting search engine result page data is usually called "search engine scraping" or in a general form "web crawling" and generates the data SEO related companies need to evaluate website competitive organic and sponsored rankings. This data can be used to track the position of websites and show the effectiveness of SEO as well as keywords that may need more SEO investment to rank higher.
User intent:
User intent or query intent is the identification and categorization of what a user online intended or wanted when they typed their search terms into an online web search engine for the purpose of search engine optimization or conversion rate optimization. When a user goes online, the goal can be fact-checking, comparison shopping, filling downtime, or other activity.
Types:
Though there are various ways of classifying or naming the categories of the different types of user intent, overall they seem to follow the same clusters. In general and up until the rise and explosion of mobile search, there are and were three very broad categories: informational, transactional, and navigational. However over time and with the rise of mobile search, other categories have appeared or categories have segmented into more specific categorization.
See also:
In general, the earlier (or higher ranked on the search results page), and more frequently a site appears in the search results list, the more visitors it will receive from the search engine's users, and these visitors can be converted into customers.
SEO may target different kinds of search, including image search, local search, video search, academic search, news search and industry-specific vertical search engines.
As an Internet marketing strategy, SEO considers how search engines work, what people search for, the actual search terms or keywords typed into search engines and which search engines are preferred by their targeted audience.
Optimizing a website may involve editing its content, HTML and associated coding to both increase its relevance to specific keywords and to remove barriers to the indexing activities of search engines.
Promoting a site to increase the number of backlinks, or inbound links, is another SEO tactic. As of May 2015, mobile search has finally surpassed desktop search, Google is developing and pushing mobile search as the future in all of its products and many brands are beginning to take a different approach on their internet strategies.
Google's Role in SEO:
In 1998, Graduate students at Stanford University, Larry Page and Sergey Brin, developed "Backrub," a search engine that relied on a mathematical algorithm to rate the prominence of web pages. The number calculated by the algorithm, PageRank, is a function of the quantity and strength of inbound links.
PageRank estimates the likelihood that a given page will be reached by a web user who randomly surfs the web, and follows links from one page to another. In effect, this means that some links are stronger than others, as a higher PageRank page is more likely to be reached by the random surfer.
Page and Brin founded Google in 1998. Google attracted a loyal following among the growing number of Internet users, who liked its simple design. Off-page factors (such as PageRank and hyperlink analysis) were considered as well as on-page factors (such as keyword frequency, meta tags, headings, links and site structure) to enable Google to avoid the kind of manipulation seen in search engines that only considered on-page factors for their rankings.
Although PageRank was more difficult to game, webmasters had already developed link building tools and schemes to influence the Inktomi search engine, and these methods proved similarly applicable to gaming PageRank. Many sites focused on exchanging, buying, and selling links, often on a massive scale. Some of these schemes, or link farms, involved the creation of thousands of sites for the sole purpose of link spamming.
By 2004, search engines had incorporated a wide range of undisclosed factors in their ranking algorithms to reduce the impact of link manipulation. In June 2007, The New York Times' Saul Hansell stated Google ranks sites using more than 200 different signals.The leading search engines, Google, Bing, and Yahoo, do not disclose the algorithms they use to rank pages.
Some SEO practitioners have studied different approaches to search engine optimization, and have shared their personal opinions. Patents related to search engines can provide information to better understand search engines.
In 2005, Google began personalizing search results for each user. Depending on their history of previous searches, Google crafted results for logged in users. In 2008, Bruce Clay said that "ranking is dead" because of personalized search. He opined that it would become meaningless to discuss how a website ranked, because its rank would potentially be different for each user and each search.
In 2007, Google announced a campaign against paid links that transfer PageRank. On June 15, 2009, Google disclosed that they had taken measures to mitigate the effects of PageRank sculpting by use of the no follow attribute on links. Matt Cutts, a well-known software engineer at Google, announced that Google Bot would no longer treat no-followed links in the same way, in order to prevent SEO service providers from using no-follow for PageRank sculpting.
As a result of this change the usage of nofollow leads to evaporation of pagerank. In order to avoid the above, SEO engineers developed alternative techniques that replace nofollowed tags with obfuscated Javascript and thus permit PageRank sculpting.
Additionally several solutions have been suggested that include the usage of iframes, Flash and Javascript.
In December 2009, Google announced it would be using the web search history of all its users in order to populate search results.
On June 8, 2010 a new web indexing system called Google Caffeine was announced. Designed to allow users to find news results, forum posts and other content much sooner after publishing than before, Google caffeine was a change to the way Google updated its index in order to make things show up quicker on Google than before. According to Carrie Grimes, the software engineer who announced Caffeine for Google, "Caffeine provides 50 percent fresher results for web searches than our last index..."
Google Instant, real-time-search, was introduced in late 2010 in an attempt to make search results more timely and relevant. Historically site administrators have spent months or even years optimizing a website to increase search rankings. With the growth in popularity of social media sites and blogs the leading engines made changes to their algorithms to allow fresh content to rank quickly within the search results.
In February 2011, Google announced the Panda update, which penalizes websites containing content duplicated from other websites and sources. Historically websites have copied content from one another and benefited in search engine rankings by engaging in this practice, however Google implemented a new system which punishes sites whose content is not unique.
The 2012 Google Penguin attempted to penalize websites that used manipulative techniques to improve their rankings on the search engine, and the 2013 Google Hummingbird update featured an algorithm change designed to improve Google's natural language processing and semantic understanding of web pages.
Methods
Getting indexed:
The leading search engines, such as Google, Bing and Yahoo!, use crawlers to find pages for their algorithmic search results. Pages that are linked from other search engine indexed pages do not need to be submitted because they are found automatically. Two major directories, the Yahoo Directory and DMOZ, both require manual submission and human editorial review.
Google offers Google Search Console, for which an XML Sitemap feed can be created and submitted for free to ensure that all pages are found, especially pages that are not discoverable by automatically following links in addition to their URL submission console. Yahoo! formerly operated a paid submission service that guaranteed crawling for a cost per click; this was discontinued in 2009.
Search engine crawlers may look at a number of different factors when crawling a site. Not every page is indexed by the search engines. Distance of pages from the root directory of a site may also be a factor in whether or not pages get crawled.
Preventing crawling:
Main article: Robots Exclusion Standard
To avoid undesirable content in the search indexes, webmasters can instruct spiders not to crawl certain files or directories through the standard robots.txt file in the root directory of the domain. Additionally, a page can be explicitly excluded from a search engine's database by using a meta tag specific to robots.
When a search engine visits a site, the robots.txt located in the root directory is the first file crawled. The robots.txt file is then parsed, and will instruct the robot as to which pages are not to be crawled. As a search engine crawler may keep a cached copy of this file, it may on occasion crawl pages a webmaster does not wish crawled.
Pages typically prevented from being crawled include login specific pages such as shopping carts and user-specific content such as search results from internal searches. In March 2007, Google warned webmasters that they should prevent indexing of internal search results because those pages are considered search spam.
Increasing prominence:
A variety of methods can increase the prominence of a webpage within the search results. Cross linking between pages of the same website to provide more links to important pages may improve its visibility.
Writing content that includes frequently searched keyword phrase, so as to be relevant to a wide variety of search queries will tend to increase traffic. Updating content so as to keep search engines crawling back frequently can give additional weight to a site.
Adding relevant keywords to a web page's meta data, including the title tag and meta description, will tend to improve the relevancy of a site's search listings, thus increasing traffic. URL normalization of web pages accessible via multiple urls, using the canonical link element or via 301 redirects can help make sure links to different versions of the URL all count towards the page's link popularity score.
White hat versus black hat techniques:
SEO techniques can be classified into two broad categories: techniques that search engines recommend as part of good design, and those techniques of which search engines do not approve. The search engines attempt to minimize the effect of the latter, among them spamdexing. Industry commentators have classified these methods, and the practitioners who employ them, as either white hat SEO, or black hat SEO.
White hats tend to produce results that last a long time, whereas black hats anticipate that their sites may eventually be banned either temporarily or permanently once the search engines discover what they are doing.
An SEO technique is considered white hat if it conforms to the search engines' guidelines and involves no deception. As the search engine guidelines are not written as a series of rules or commandments, this is an important distinction to note. White hat SEO is not just about following guidelines, but is about ensuring that the content a search engine indexes and subsequently ranks is the same content a user will see.
White hat advice is generally summed up as creating content for users, not for search engines, and then making that content easily accessible to the spiders, rather than attempting to trick the algorithm from its intended purpose. White hat SEO is in many ways similar to web development that promotes accessibility, although the two are not identical.
Black hat SEO attempts to improve rankings in ways that are disapproved of by the search engines, or involve deception. One black hat technique uses text that is hidden, either as text colored similar to the background, in an invisible div, or positioned off screen. Another method gives a different page depending on whether the page is being requested by a human visitor or a search engine, a technique known as cloaking.
Another category sometimes used is grey hat SEO. This is in between black hat and white hat approaches where the methods employed avoid the site being penalized however do not act in producing the best content for users, rather entirely focused on improving search engine rankings.
Search engines may penalize sites they discover using black hat methods, either by reducing their rankings or eliminating their listings from their databases altogether. Such penalties can be applied either automatically by the search engines' algorithms, or by a manual site review.
One example was the February 2006 Google removal of both BMW Germany and Ricoh Germany for use of deceptive practices. Both companies, however, quickly apologized, fixed the offending pages, and were restored to Google's list.
As a marketing strategy, SEO is not an appropriate strategy for every website, and other Internet marketing strategies can be more effective like paid advertising through pay per click (PPC) campaigns, depending on the site operator's goals.
A successful Internet marketing campaign may also depend upon building high quality web pages to engage and persuade, setting up analytics programs to enable site owners to measure results, and improving a site's conversion rate.
In November 2015, Google released a full 160 page version of its Search Quality Rating Guidelines to the public, which now shows a shift in their focus towards "usefulness" and mobile search.
SEO may generate an adequate return on investment. However, search engines are not paid for organic search traffic, their algorithms change, and there are no guarantees of continued referrals. Due to this lack of guarantees and certainty, a business that relies heavily on search engine traffic can suffer major losses if the search engines stop sending visitors. Search engines can change their algorithms, impacting a website's placement, possibly resulting in a serious loss of traffic.
According to Google's CEO, Eric Schmidt, in 2010, Google made over 500 algorithm changes – almost 1.5 per day. It is considered wise business practice for website operators to liberate themselves from dependence on search engine traffic.
In addition to accessibility in terms of web crawlers (addressed above), user web accessibility has become increasingly important for SEO.
International markets:
Optimization techniques are highly tuned to the dominant search engines in the target market. The search engines' market shares vary from market to market, as does competition. In 2003, Danny Sullivan stated that Google represented about 75% of all searches. In markets outside the United States, Google's share is often larger, and Google remains the dominant search engine worldwide as of 2007.
As of 2006, Google had an 85–90% market share in Germany. While there were hundreds of SEO firms in the US at that time, there were only about five in Germany. As of June 2008, the marketshare of Google in the UK was close to 90% according to Hitwise. That market share is achieved in a number of countries.
As of 2009, there are only a few large markets where Google is not the leading search engine. In most cases, when Google is not leading in a given market, it is lagging behind a local player. The most notable example markets are China, Japan, South Korea, Russia and the Czech Republic where respectively Baidu, Yahoo! Japan, Naver, Yandex and Seznam are market leaders.
Successful search optimization for international markets may require professional translation of web pages, registration of a domain name with a top level domain in the target market, and web hosting that provides a local IP address. Otherwise, the fundamental elements of search optimization are essentially the same, regardless of language.
Legal precedents:
On October 17, 2002, SearchKing filed suit in the United States District Court, Western District of Oklahoma, against the search engine Google. SearchKing's claim was that Google's tactics to prevent spamdexing constituted a tortious interference with contractual relations. On May 27, 2003, the court granted Google's motion to dismiss the complaint because SearchKing "failed to state a claim upon which relief may be granted."
In March 2006, KinderStart filed a lawsuit against Google over search engine rankings. Kinderstart's website was removed from Google's index prior to the lawsuit and the amount of traffic to the site dropped by 70%. On March 16, 2007 the United States District Court for the Northern District of California (San Jose Division) dismissed KinderStart's complaint without leave to amend, and partially granted Google's motion for Rule 11 sanctions against KinderStart's attorney, requiring him to pay part of Google's legal expenses.
See also: ___________________________________________________________________________
Search Engine Results Page (SERP)
A search engine results page (SERP) is the page displayed by a web search engine in response to a query by a searcher. The main component of the SERP is the listing of results that are returned by the search engine in response to a keyword query, although the page may also contain other results such as advertisements.
The results are of two general types, organic (i.e., retrieved by the search engine's algorithm) and sponsored (i.e., advertisements). The results are normally ranked by relevance to the query. Each result displayed on the SERP normally includes a title, a link that points to the actual page on the Web and a short description showing where the keywords have matched content within the page for organic results. For sponsored results, the advertiser chooses what to display.
Due to the huge number of items that are available or related to the query there usually are several SERPs in response to a single search query as the search engine or the user's preferences restrict viewing to a subset of results per page. Each succeeding page will tend to have lower ranking or lower relevancy results.
Just like the world of traditional print media and its advertising, this enables competitive pricing for page real estate, but compounded by the dynamics of consumer expectations and intent— unlike static print media where the content and the advertising on every page is the same all of the time for all viewers, despite such hard copy being localized to some degree, usually geographic, like state, metro-area, city, or neighborhoods.
Components:
There are basically four main components of SERP, which are
- the search query contained within a query box
- the organic SERP results
- sponsored SERP results
However, the SERPs of major search engines, like Google, Yahoo!, and Bing, may include many different types of enhanced results (organic search and sponsored) such as rich snippets, images, maps, definitions, answer boxes, videos or suggested search refinements. A recent study revealed that 97% of queries in Google returned at least one rich feature.
The major search engines visually differentiate specific content types such as images, news, and blogs. Many content types have specialized SERP templates and visual enhancements on the main search results page.
Search query:
Also known as 'user search string', this is the word or set of words that are typed by the user in the search bar of the search engine. The search box is located on all major search engines like Google, Yahoo, and Bing. Users indicate the topic desired based on the keywords they enter into the search box in the search engine.
In the competition between search engines to draw the attention of more users and advertisers, consumer satisfaction has been a driving force in the evolution of the search algorithm applied to better filter the results by relevancy.
Search queries are no longer successful based upon merely finding words that match purely by spelling. Intent and expectations have to be derived to determine whether the appropriate result is a match based upon the broader meanings drawn from context.
And that sense of context has grown from simple matching of words, and then of phrases, to the matching of ideas. And the meanings of those ideas change over time and context.
Successful matching can be crowd sourced, what are others currently searching for and clicking on, when one enters keywords related to those other searches. And the crowd sourcing may be focused based upon one's own social networking.
With the advent of portable devices, smartphones, and wearable devices, watches and various sensors, these provide ever more contextual dimensions for consumer and advertiser to refine and maximize relevancy using such additional factors that may be gleaned like:
- a person's relative health,
- wealth,
- and various other status,
- time of day,
- personal habits,
- mobility,
- location,
- weather,
- and nearby services and opportunities, whether urban or suburban, like events, food, recreation, and business.
Social context and crowd sourcing influences can also be pertinent factors.
The move away from keyboard input and the search box to voice access, aside from convenience, also makes other factors available to varying degrees of accuracy and pertinence, like: a person's character, intonation, mood, accent, ethnicity, and even elements overheard from nearby people and the background environment.
Searching is changing from explicit keywords: on TV show w, did x marry y or z, or election results for candidate x in county y for this date z, or final scores for team x in game y for this date z to vocalizing from a particular time and location: hey, so who won. And getting the results that one expects.
Organic results:
Main article: Web search query
Organic SERP listings are the natural listings generated by search engines based on a series of metrics that determines their relevance to the searched term. Webpages that score well on a search engine's algorithmic test show in this list.
These algorithms are generally based upon factors such as the content of a webpage, the trustworthiness of the website, and external factors such as backlinks, social media, news, advertising, etc.
People tend to view the SERP and the first results on each SERP. Each page of search engine results usually contains 10 organic listings (however some results pages may have fewer organic listings).
The listings, which are on the first page are the most important ones, because those get 91% of the click through rates (CTR) from a particular search. According to a 2013 study, the CTR's for the first page goes as:
- TOP 1: 32.5%
- TOP 2: 17.6%
- TOP 3: 11.4%
- TOP 4: 8.1%
- TOP 5: 6.1%
- TOP 6: 4.4%
- TOP 7: 3.5%
- TOP 8: 3.1%
- TOP 9: 2.6%
- TOP 10: 2.4%
Sponsored results:
Main article: Search engine marketing § Paid inclusion
Every major search engine with significant market share accepts paid listings. This unique form of search engine advertising guarantees that your site will appear in the top results for the keyword terms you target within a day or less. Paid search listings are also called sponsored listings and/or Pay Per Click (PPC) listings.
Rich snippets:
Rich snippets are displayed by Google in the search results page when a website contains content in structured data markup. Structured data markup helps the Google algorithm to index and understand the content better. Google supports rich snippets for the following data types:
- Product – Information about a product, including price, availability, and review ratings.
- Recipe – Recipes that can be displayed in web searches and Recipe View.
- Review – A review of an item such as a restaurant, movie, or store.
- Event – An organized event, such as musical concerts or art festivals, that people may attend at a particular time and place.
- SoftwareApplication – Information about a software app, including its URL, review ratings, and price.
- Video – An online video, including a description and thumbnail.
- News article – A news article, including headline, images, and publisher info.
- Science datasets
Knowledge Graph:
Search engines like Google or Bing have started to expand their data into encyclopedias and other rich sources of information.
Google for example calls this sort of information "Knowledge Graph", if a search query matches it will display an additional sub-window on right hand side with information from its sources.
Information about hotels, events, flights, places, businesses, people, books and movies, countries, sport groups, architecture and more can be obtained that way.
Generation:
Major search engines like Google, Yahoo!, and Bing primarily use content contained within the page and fallback to metadata tags of a web page to generate the content that makes up a search snippet. Generally, the HTML title tag will be used as the title of the snippet while the most relevant or useful contents of the web page (description tag or page copy) will be used for the description.
Scraping and automated access:
Search engine result pages are protected from automated access by a range of defensive mechanisms and the terms of service. These result pages are the primary data source for SEO companies, the website placement for competitive keywords became an important field of business and interest. Google has even used twitter to warn users against this practice.
The sponsored (creative) results on Google can cost an large amount of money for advertisers, a few of which pay Google nearly 1000 USD for each sponsored click.
The process of harvesting search engine result page data is usually called "search engine scraping" or in a general form "web crawling" and generates the data SEO related companies need to evaluate website competitive organic and sponsored rankings. This data can be used to track the position of websites and show the effectiveness of SEO as well as keywords that may need more SEO investment to rank higher.
User intent:
User intent or query intent is the identification and categorization of what a user online intended or wanted when they typed their search terms into an online web search engine for the purpose of search engine optimization or conversion rate optimization. When a user goes online, the goal can be fact-checking, comparison shopping, filling downtime, or other activity.
Types:
Though there are various ways of classifying or naming the categories of the different types of user intent, overall they seem to follow the same clusters. In general and up until the rise and explosion of mobile search, there are and were three very broad categories: informational, transactional, and navigational. However over time and with the rise of mobile search, other categories have appeared or categories have segmented into more specific categorization.
See also:
CAPTCHA
YouTube Video: How Does CAPTCHA Work?
Pictured: Example of CAPTCHA phrase for website visitor to enter to ensure human (not robot) user.

A CAPTCHA (a backronym for "Completely Automated Public Turing test to tell Computers and Humans Apart") is a type of challenge-response test used in computing to determine whether or not the user is human.
The term was coined in 2003 by Luis von Ahn, Manuel Blum, Nicholas J. Hopper, and John Langford.
The most common type of CAPTCHA was first invented in 1997 by Mark D. Lillibridge, Martin Abadi, Krishna Bharat, and Andrei Z. Broder. This form of CAPTCHA requires that the user type the letters of a distorted image, sometimes with the addition of an obscured sequence of letters or digits that appears on the screen.
Because the test is administered by a computer, in contrast to the standard Turing test that is administered by a human, a CAPTCHA is sometimes described as a reverse Turing test. This term is ambiguous because it could also mean a Turing test in which the participants are both attempting to prove they are the computer.
This user identification procedure has received many criticisms, especially from disabled people, but also from other people who feel that their everyday work is slowed down by distorted words that are difficult to read. It takes the average person approximately 10 seconds to solve a typical CAPTCHA.
Click on any of the following blue hyperlinks for more about CAPTCHA:
The term was coined in 2003 by Luis von Ahn, Manuel Blum, Nicholas J. Hopper, and John Langford.
The most common type of CAPTCHA was first invented in 1997 by Mark D. Lillibridge, Martin Abadi, Krishna Bharat, and Andrei Z. Broder. This form of CAPTCHA requires that the user type the letters of a distorted image, sometimes with the addition of an obscured sequence of letters or digits that appears on the screen.
Because the test is administered by a computer, in contrast to the standard Turing test that is administered by a human, a CAPTCHA is sometimes described as a reverse Turing test. This term is ambiguous because it could also mean a Turing test in which the participants are both attempting to prove they are the computer.
This user identification procedure has received many criticisms, especially from disabled people, but also from other people who feel that their everyday work is slowed down by distorted words that are difficult to read. It takes the average person approximately 10 seconds to solve a typical CAPTCHA.
Click on any of the following blue hyperlinks for more about CAPTCHA:
- Origin and inventorship
- Relation to AI
- Accessibility
- Circumvention
- Alternative CAPTCHAs schemas
- See also:
Internet as a Global Phenomenon
Published by MIT Technology Review (by Manuel Castells September 8, 2014)
YouTube Video of Eric Schmidt* & Jared Cohen**: The Impact of Internet and Technology
* -- Eric Schimdt
** -- Jared Cohen
Pictured: The Future of Privacy Forum: "Almost every time we go online, using our computers or mobile devices, each of us produces data in some form. This data may contain only oblique information about who we are and what we are doing, but when enough of it is aggregated, facts about us which we believed were private has the potential to become known to and used by others." Click here to read more.
"The Internet is the decisive technology of the Information Age, and with the explosion of wireless communication in the early twenty-first century, we can say that humankind is now almost entirely connected, albeit with great levels of inequality in bandwidth, efficiency, and price.
People, companies, and institutions feel the depth of this technological change, but the speed and scope of the transformation has triggered all manner of utopian and dystopian perceptions that, when examined closely through methodologically rigorous empirical research, turn out not to be accurate. For instance, media often report that intense use of the Internet increases the risk of isolation, alienation, and withdrawal from society, but available evidence shows that the Internet neither isolates people nor reduces their sociability; it actually increases sociability, civic engagement, and the intensity of family and friendship relationships, in all cultures.
Our current “network society” is a product of the digital revolution and some major sociocultural changes. One of these is the rise of the “Me-centered society,” marked by an increased focus on individual growth and a decline in community understood in terms of space, work, family, and ascription in general. But individuation does not mean isolation, or the end of community. Instead, social relationships are being reconstructed on the basis of individual interests, values, and projects. Community is formed through individuals’ quests for like-minded people in a process that combines online interaction with offline interaction, cyberspace, and the local space.
Globally, time spent on social networking sites surpassed time spent on e-mail in November 2007, and the number of social networking users surpassed the number of e-mail users in July 2009. Today, social networking sites are the preferred platforms for all kinds of activities, both business and personal, and sociability has dramatically increased — but it is a different kind of sociability. Most Facebook users visit the site daily, and they connect on multiple dimensions, but only on the dimensions they choose. The virtual life is becoming more social than the physical life, but it is less a virtual reality than a real virtuality, facilitating real-life work and urban living.
Because people are increasingly at ease in the Web’s multidimensionality, marketers, government, and civil society are migrating massively to the networks people construct by themselves and for themselves. At root, social-networking entrepreneurs are really selling spaces in which people can freely and autonomously construct their lives. Sites that attempt to impede free communication are soon abandoned by many users in favor of friendlier and less restricted spaces.
Perhaps the most telling expression of this new freedom is the Internet’s transformation of sociopolitical practices. Messages no longer flow solely from the few to the many, with little interactivity. Now, messages also flow from the many to the many, multimodally and interactively. By disintermediating government and corporate control of communication, horizontal communication networks have created a new landscape of social and political change.
Networked social movements have been particularly active since 2010, notably in the Arab revolutions against dictatorships and the protests against the management of the financial crisis. Online and particularly wireless communication has helped social movements pose more of a challenge to state power.
The Internet and the Web constitute the technological infrastructure of the global network society, and the understanding of their logic is a key field of research. It is only scholarly research that will enable us to cut through the myths surrounding this digital communication technology that is already a second skin for young people, yet continues to feed the fears and the fantasies of those who are still in charge of a society that they barely understand....
Read the full article here.
People, companies, and institutions feel the depth of this technological change, but the speed and scope of the transformation has triggered all manner of utopian and dystopian perceptions that, when examined closely through methodologically rigorous empirical research, turn out not to be accurate. For instance, media often report that intense use of the Internet increases the risk of isolation, alienation, and withdrawal from society, but available evidence shows that the Internet neither isolates people nor reduces their sociability; it actually increases sociability, civic engagement, and the intensity of family and friendship relationships, in all cultures.
Our current “network society” is a product of the digital revolution and some major sociocultural changes. One of these is the rise of the “Me-centered society,” marked by an increased focus on individual growth and a decline in community understood in terms of space, work, family, and ascription in general. But individuation does not mean isolation, or the end of community. Instead, social relationships are being reconstructed on the basis of individual interests, values, and projects. Community is formed through individuals’ quests for like-minded people in a process that combines online interaction with offline interaction, cyberspace, and the local space.
Globally, time spent on social networking sites surpassed time spent on e-mail in November 2007, and the number of social networking users surpassed the number of e-mail users in July 2009. Today, social networking sites are the preferred platforms for all kinds of activities, both business and personal, and sociability has dramatically increased — but it is a different kind of sociability. Most Facebook users visit the site daily, and they connect on multiple dimensions, but only on the dimensions they choose. The virtual life is becoming more social than the physical life, but it is less a virtual reality than a real virtuality, facilitating real-life work and urban living.
Because people are increasingly at ease in the Web’s multidimensionality, marketers, government, and civil society are migrating massively to the networks people construct by themselves and for themselves. At root, social-networking entrepreneurs are really selling spaces in which people can freely and autonomously construct their lives. Sites that attempt to impede free communication are soon abandoned by many users in favor of friendlier and less restricted spaces.
Perhaps the most telling expression of this new freedom is the Internet’s transformation of sociopolitical practices. Messages no longer flow solely from the few to the many, with little interactivity. Now, messages also flow from the many to the many, multimodally and interactively. By disintermediating government and corporate control of communication, horizontal communication networks have created a new landscape of social and political change.
Networked social movements have been particularly active since 2010, notably in the Arab revolutions against dictatorships and the protests against the management of the financial crisis. Online and particularly wireless communication has helped social movements pose more of a challenge to state power.
The Internet and the Web constitute the technological infrastructure of the global network society, and the understanding of their logic is a key field of research. It is only scholarly research that will enable us to cut through the myths surrounding this digital communication technology that is already a second skin for young people, yet continues to feed the fears and the fantasies of those who are still in charge of a society that they barely understand....
Read the full article here.
Website Builders
YouTube Video: Free website builders: a comparison of the best ones
Pictured: Logos of three prominent website builders from L-R: Silex, WordPress, and Weebly

Website builders are tools that typically allow the construction of websites without manual code editing. They fall into two categories:
Click on any of the following hyperlinks to read more: note that the link "Website Builder Comparison" includes a comprehensive breakdown of website builder company capabilities/limitations.
- online proprietary tools provided by web hosting companies. These are typically intended for users to build their private site. Some companies allow the site owner to install alternative tools (commercial or open source) - the more complex of these may also be described as Content Management Systems;
- offline software which runs on a computer, creating pages and which can then publish these pages on any host. (These are often considered to be "website design software" rather than "website builders".)
Click on any of the following hyperlinks to read more: note that the link "Website Builder Comparison" includes a comprehensive breakdown of website builder company capabilities/limitations.
- History
- Online vs. offline
- List of notable online website builders
- Example for offline website builder software
- Website builder comparison
- HTML editor
- Comparison of HTML editors
- Web design
World Wide Web
YouTube Video: What is the world wide web? - Twila Camp (TED-Ed)
Pictured: Graphic representation of a minute fraction of the WWW, demonstrating hyperlinks
The World Wide Web (WWW) is an information space where documents and other web resources are identified by URLs, interlinked by hypertext links, and can be accessed via the Internet.
The World Wide Web was invented by English scientist Tim Berners-Lee in 1989. He wrote the first web browser in 1990 while employed at CERN in Switzerland.
It has become known simply as the Web. When used attributively (as in web page, web browser, website, web server, web traffic, web search, web user, web technology, etc.) it is invariably written in lower case. Otherwise the initial capital is often retained (‘the Web’), but lower case is becoming increasingly common (‘the web’).
The World Wide Web was central to the development of the Information Age and is the primary tool billions of people use to interact on the Internet.
Web pages are primarily text documents formatted and annotated with Hypertext Markup Language (HTML). In addition to formatted text, web pages may contain images, video, and software components that are rendered in the user's web browser as coherent pages of multimedia content.
Embedded hyperlinks permit users to navigate between web pages. Multiple web pages with a common theme, a common domain name, or both, may be called a website. Website content can largely be provided by the publisher, or interactive where users contribute content or the content depends upon the user or their actions. Websites may be mostly informative, primarily for entertainment, or largely for commercial purposes.
For amplification, click on any of the following:
The World Wide Web was invented by English scientist Tim Berners-Lee in 1989. He wrote the first web browser in 1990 while employed at CERN in Switzerland.
It has become known simply as the Web. When used attributively (as in web page, web browser, website, web server, web traffic, web search, web user, web technology, etc.) it is invariably written in lower case. Otherwise the initial capital is often retained (‘the Web’), but lower case is becoming increasingly common (‘the web’).
The World Wide Web was central to the development of the Information Age and is the primary tool billions of people use to interact on the Internet.
Web pages are primarily text documents formatted and annotated with Hypertext Markup Language (HTML). In addition to formatted text, web pages may contain images, video, and software components that are rendered in the user's web browser as coherent pages of multimedia content.
Embedded hyperlinks permit users to navigate between web pages. Multiple web pages with a common theme, a common domain name, or both, may be called a website. Website content can largely be provided by the publisher, or interactive where users contribute content or the content depends upon the user or their actions. Websites may be mostly informative, primarily for entertainment, or largely for commercial purposes.
For amplification, click on any of the following:
- History
- Function
- Web security
- Privacy
- Standards
- Accessibility
- Internationalization
- Statistics
- Speed issues
- Web caching
- See also:
Internet Radio including a List of Internet Radio Stations
YouTube Video: Demi Lovato & Brad Paisley - Stone Cold (Live At The 2016 iHeartRadio Music Awards)

Click here for a List of Internet Radio Stations
Internet radio (also web radio, net radio, streaming radio, e-radio, online radio, webcasting) is an audio service transmitted via the Internet. Broadcasting on the Internet is usually referred to as webcasting since it is not transmitted broadly through wireless means.
Internet radio involves streaming media, presenting listeners with a continuous stream of audio that typically cannot be paused or replayed, much like traditional broadcast media; in this respect, it is distinct from on-demand file serving. Internet radio is also distinct from podcasting, which involves downloading rather than streaming.
Internet radio services offer news, sports, talk, and various genres of music—every format that is available on traditional broadcast radio stations.
Many Internet radio services are associated with a corresponding traditional (terrestrial) radio station or radio network, although low start-up and ongoing costs have allowed a substantial proliferation of independent Internet-only radio stations.
Click on any of the following blue hyperlinks for additional information about Internet Radio:
Internet radio (also web radio, net radio, streaming radio, e-radio, online radio, webcasting) is an audio service transmitted via the Internet. Broadcasting on the Internet is usually referred to as webcasting since it is not transmitted broadly through wireless means.
Internet radio involves streaming media, presenting listeners with a continuous stream of audio that typically cannot be paused or replayed, much like traditional broadcast media; in this respect, it is distinct from on-demand file serving. Internet radio is also distinct from podcasting, which involves downloading rather than streaming.
Internet radio services offer news, sports, talk, and various genres of music—every format that is available on traditional broadcast radio stations.
Many Internet radio services are associated with a corresponding traditional (terrestrial) radio station or radio network, although low start-up and ongoing costs have allowed a substantial proliferation of independent Internet-only radio stations.
Click on any of the following blue hyperlinks for additional information about Internet Radio:
- Internet radio technology
- Popularity
- History including US royalty controversy
- See also:
Internet Troll and other Internet Slang
YouTube Video: Top 10 Types of Internet Trolls
Pictured: The advice to ignore rather than engage with a troll is sometimes phrased as "Please do not feed the trolls."

Click here for more about Internet Slang.
Below, we cover the topic "Internet Troll":
In Internet slang, a troll is a person who sows discord on the Internet by starting arguments or upsetting people, by posting inflammatory, extraneous, or off-topic messages in an online community (such as a newsgroup, forum, chat room, or blog) with the deliberate intent of provoking readers into an emotional response or of otherwise disrupting normal on-topic discussion, often for their own amusement.
This sense of the word "troll" and its associated verb trolling are associated with Internet discourse, but have been used more widely.
Media attention in recent years has equated trolling with online harassment. For example, mass media has used troll to describe "a person who defaces Internet tribute sites with the aim of causing grief to families."
In addition, depictions of trolling have been included in popular fictional works such as the HBO television program The Newsroom, in which a main character encounters harassing individuals online and tries to infiltrate their circles by posting negative sexual comments himself.
Click on any of the following blue hyperlinks for more about Internet Troll:
Below, we cover the topic "Internet Troll":
In Internet slang, a troll is a person who sows discord on the Internet by starting arguments or upsetting people, by posting inflammatory, extraneous, or off-topic messages in an online community (such as a newsgroup, forum, chat room, or blog) with the deliberate intent of provoking readers into an emotional response or of otherwise disrupting normal on-topic discussion, often for their own amusement.
This sense of the word "troll" and its associated verb trolling are associated with Internet discourse, but have been used more widely.
Media attention in recent years has equated trolling with online harassment. For example, mass media has used troll to describe "a person who defaces Internet tribute sites with the aim of causing grief to families."
In addition, depictions of trolling have been included in popular fictional works such as the HBO television program The Newsroom, in which a main character encounters harassing individuals online and tries to infiltrate their circles by posting negative sexual comments himself.
Click on any of the following blue hyperlinks for more about Internet Troll:
- Usage
- Origin and etymology including In other languages
- Trolling, identity, and anonymity
- Corporate, political, and special interest sponsored trolls
- Psychological characteristics
- Concern troll
- Troll sites
- Media coverage and controversy
- Examples
- See also:
Internet in the United States including a PewResearchCenter* Survey of Technology Device Ownership: 2015.
* -- PewResearchCenter
YouTube Video: How to Compare Internet Service Providers
Pictured: ISP choices available to Americans -- Reflecting a monopoly hold on U.S. Internet Users by licensed cable company providers by region
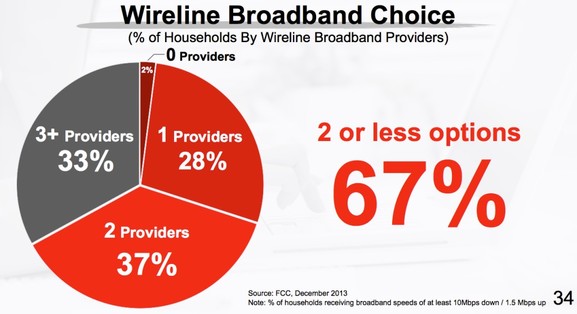
The Internet in the United States grew out of the ARPANET, a network sponsored by the Advanced Research Projects Agency of the U.S. Department of Defense during the 1960s. The Internet in the United States in turn provided the foundation for the world-wide Internet of today.
For more details on this topic, see History of the Internet. Internet access in the United States is largely provided by the private sector and is available in a variety of forms, using a variety of technologies, at a wide range of speeds and costs. In 2014, 87.4% of Americans were using the Internet, which ranks the U.S. 18th out of 211 countries in the world.
A large number of people in the US have little or no choice at all on who provides their internet access. The country suffers from a severe lack of competition in the broadband business. Nearly one-third of households in the United States have either no choice for home broadband Internet service, or no options at all.
Internet top-level domain names specific to the U.S. include:
Many U.S.-based organizations and individuals also use generic top-level domains (.com, .net, .org, .name, ...).
Click on any of the following blue hyperlinks for amplification:
For more details on this topic, see History of the Internet. Internet access in the United States is largely provided by the private sector and is available in a variety of forms, using a variety of technologies, at a wide range of speeds and costs. In 2014, 87.4% of Americans were using the Internet, which ranks the U.S. 18th out of 211 countries in the world.
A large number of people in the US have little or no choice at all on who provides their internet access. The country suffers from a severe lack of competition in the broadband business. Nearly one-third of households in the United States have either no choice for home broadband Internet service, or no options at all.
Internet top-level domain names specific to the U.S. include:
- .us,
- .edu,
- .gov,
- .mil,
- .as (American Samoa),
- .gu (Guam),
- .mp (Northern Mariana Islands),
- .pr (Puerto Rico),
- and
- .vi (U.S. Virgin Islands).
Many U.S.-based organizations and individuals also use generic top-level domains (.com, .net, .org, .name, ...).
Click on any of the following blue hyperlinks for amplification:
- Overview
- Broadband providers
- Government policy and programs
- See also:
- Satellite Internet access
- Broadband mapping in the United States
- Communications Assistance for Law Enforcement Act (CALEA)
- Communications in the United States
- Internet in American Samoa
- Internet in Guam
- Internet in Puerto Rico
- Internet in the United States Virgin Islands
- Mass surveillance in the United States
- Municipal broadband
- National broadband plans from around the world
Cyber Culture
YouTube: Cyberculture - what is it really? [HD]

Cyberculture or computer culture is the culture that has emerged, or is emerging, from the use of computer networks for communication, entertainment, and business.
Internet culture is also the study of various social phenomena associated with the Internet and other new forms of the network communication, such as :
Since the boundaries of cyberculture are difficult to define, the term is used flexibly, and its application to specific circumstances can be controversial. It generally refers at least to the cultures of virtual communities, but extends to a wide range of cultural issues relating to "cyber-topics", e.g. cybernetics, and the perceived or predicted cyborgization of the human body and human society itself. It can also embrace associated intellectual and cultural movements, such as cyborg theory and cyberpunk. The term often incorporates an implicit anticipation of the future.
The Oxford English Dictionary lists the earliest usage of the term "cyberculture" in 1963, when A.M. Hilton wrote the following, "In the era of cyberculture, all the plows pull themselves and the fried chickens fly right onto our plates."
This example, and all others, up through 1995 are used to support the definition of cyberculture as "the social conditions brought about by automation and computerization."
The American Heritage Dictionary broadens the sense in which "cyberculture" is used by defining it as, "The culture arising from the use of computer networks, as for communication, entertainment, work, and business".
However, what both the OED and the American Heritage Dictionary miss is that cyberculture is the culture within and among users of computer networks. This cyberculture may be purely an online culture or it may span both virtual and physical worlds.
This is to say, that cyberculture is a culture endemic to online communities; it is not just the culture that results from computer use, but culture that is directly mediated by the computer. Another way to envision cyberculture is as the electronically enabled linkage of like-minded, but potentially geographically disparate (or physically disabled and hence less mobile) persons.
Cyberculture is a wide social and cultural movement closely linked to advanced information science and information technology, their emergence, development and rise to social and cultural prominence between the 1960s and the 1990s.
Cyberculture was influenced at its genesis by those early users of the internet, frequently including the architects of the original project. These individuals were often guided in their actions by the hacker ethic. While early cyberculture was based on a small cultural sample, and its ideals, the modern cyberculture is a much more diverse group of users and the ideals that they espouse.
Numerous specific concepts of cyberculture have been formulated by such authors as Lev Manovich, Arturo Escobar and Fred Forest.
However, most of these concepts concentrate only on certain aspects, and they do not cover these in great detail. Some authors aim to achieve a more comprehensive understanding distinguished between early and contemporary cyberculture (Jakub Macek), or between cyberculture as the cultural context of information technology and cyberculture (more specifically cyberculture studies) as "a particular approach to the study of the 'culture + technology' complex" (David Lister et al.).
Manifestations of cyberculture include various human interactions mediated by computer networks. They can be activities, pursuits, games, places and metaphors, and include a diverse base of applications. Some are supported by specialized software and others work on commonly accepted web protocols. Examples include but are not limited to:
Click on any of the following blue hyperlinks to learn more about Cyberculture:
Internet culture is also the study of various social phenomena associated with the Internet and other new forms of the network communication, such as :
- online communities,
- online multi-player gaming,
- wearable computing,
- social gaming,
- social media,
- mobile apps,
- augmented reality,
- and texting,
- and includes issues related to identity, privacy, and network formation.
Since the boundaries of cyberculture are difficult to define, the term is used flexibly, and its application to specific circumstances can be controversial. It generally refers at least to the cultures of virtual communities, but extends to a wide range of cultural issues relating to "cyber-topics", e.g. cybernetics, and the perceived or predicted cyborgization of the human body and human society itself. It can also embrace associated intellectual and cultural movements, such as cyborg theory and cyberpunk. The term often incorporates an implicit anticipation of the future.
The Oxford English Dictionary lists the earliest usage of the term "cyberculture" in 1963, when A.M. Hilton wrote the following, "In the era of cyberculture, all the plows pull themselves and the fried chickens fly right onto our plates."
This example, and all others, up through 1995 are used to support the definition of cyberculture as "the social conditions brought about by automation and computerization."
The American Heritage Dictionary broadens the sense in which "cyberculture" is used by defining it as, "The culture arising from the use of computer networks, as for communication, entertainment, work, and business".
However, what both the OED and the American Heritage Dictionary miss is that cyberculture is the culture within and among users of computer networks. This cyberculture may be purely an online culture or it may span both virtual and physical worlds.
This is to say, that cyberculture is a culture endemic to online communities; it is not just the culture that results from computer use, but culture that is directly mediated by the computer. Another way to envision cyberculture is as the electronically enabled linkage of like-minded, but potentially geographically disparate (or physically disabled and hence less mobile) persons.
Cyberculture is a wide social and cultural movement closely linked to advanced information science and information technology, their emergence, development and rise to social and cultural prominence between the 1960s and the 1990s.
Cyberculture was influenced at its genesis by those early users of the internet, frequently including the architects of the original project. These individuals were often guided in their actions by the hacker ethic. While early cyberculture was based on a small cultural sample, and its ideals, the modern cyberculture is a much more diverse group of users and the ideals that they espouse.
Numerous specific concepts of cyberculture have been formulated by such authors as Lev Manovich, Arturo Escobar and Fred Forest.
However, most of these concepts concentrate only on certain aspects, and they do not cover these in great detail. Some authors aim to achieve a more comprehensive understanding distinguished between early and contemporary cyberculture (Jakub Macek), or between cyberculture as the cultural context of information technology and cyberculture (more specifically cyberculture studies) as "a particular approach to the study of the 'culture + technology' complex" (David Lister et al.).
Manifestations of cyberculture include various human interactions mediated by computer networks. They can be activities, pursuits, games, places and metaphors, and include a diverse base of applications. Some are supported by specialized software and others work on commonly accepted web protocols. Examples include but are not limited to:
Click on any of the following blue hyperlinks to learn more about Cyberculture:
Internet Television or (Online Television) including a List of Internet Television Providers
YouTube Video: CBS All Access For Roku demonstration Video
Pictured: Example of online television by Watch USA Online*
* -- "Watch online to United States TV stations including KCAL 9, WFAA-TV Channel 8,WWE ,USA NETWORK,STAR MOVIES,SYFY,SHOW TIME,NBA,MTV,HLN,NEWS,HBO,FOX SPORTS,FOX NEWS,DISCOVERY,AXN,ABC,AMC,A&E,ABC FAMILY, WBAL-TV 11, FOX 6, WSVN 7 and many more..."
Click here for a List of Internet Television Providers in the United States.
Internet television (or online television) is the digital distribution of television content, such as TV shows, via the public Internet (which also carries other types of data), as opposed to dedicated terrestrial television via an over the air aerial system, cable television, and/or satellite television systems. It is also sometimes called web television, though this phrase is also used to describe the genre of TV shows broadcast only online.
Internet television is a type of over-the-top content (OTT content). "Over-the-top" (OTT) is the delivery of audio, video, and other media over the Internet without the involvement of a multiple-system operator (such as a cable television provider) in the control or distribution of the content. It has several elements:
Content Provider:
Examples include:
Internet:
The public Internet, which is used for transmission from the streaming servers to the consumer end-user.
Receiver:
The receiver must have an Internet connection, typically by Wi-fi or Ethernet, and could be:
Not all receiver devices can access all content providers. Most have websites that allow viewing of content in a web browser, but sometimes this is not done due to digital rights management concerns or restrictions. While a web browser has access to any website, some consumers find it inconvenient to control and interact with content with a mouse and keyboard, inconvenient to connect a computer to their television, or confusing.
Many providers have mobile software applications ("apps") dedicated to receive only their own content. Manufacturers of SmartTVs, boxes, sticks, and players must decide which providers to support, typically based either on popularity, common corporate ownership, or receiving payment from the provider.
Display Device:
A display device, which could be:
Comparison with Internet Protocol television (IPTV)
As described above, "Internet television" is "over-the-top technology" (OTT). It is delivered through the open, unmanaged Internet, with the "last-mile" telecom company acting only as the Internet service provider. Both OTT and IPTV use the Internet protocol suite over a packet-switched network to transmit data, but IPTV operates in a closed system - a dedicated, managed network controlled by the local cable, satellite, telephone, or fiber company.
In its simplest form, IPTV simply replaces traditional circuit switched analog or digital television channels with digital channels which happen to use packet-switched transmission. In both the old and new systems, subscribers have set-top boxes or other customer-premises equipment that talks directly over company-owned or dedicated leased lines with central-office servers. Packets never travel over the public Internet, so the television provider can guarantee enough local bandwidth for each customer's needs.
The Internet Protocol is a cheap, standardized way to provide two-way communication and also provide different data (e.g., TV show files) to different customers. This supports DVR-like features for time shifting television, for example to catch up on a TV show that was broadcast hours or days ago, or to replay the current TV show from its beginning. It also supports video on demand - browsing a catalog of videos (such as movies or syndicated television shows) which might be unrelated to the company's scheduled broadcasts. IPTV has an ongoing standardization process (for example, at the European Telecommunications Standards Institute).
Click on any of the following for further amplification about Internet Television:
Internet television (or online television) is the digital distribution of television content, such as TV shows, via the public Internet (which also carries other types of data), as opposed to dedicated terrestrial television via an over the air aerial system, cable television, and/or satellite television systems. It is also sometimes called web television, though this phrase is also used to describe the genre of TV shows broadcast only online.
Internet television is a type of over-the-top content (OTT content). "Over-the-top" (OTT) is the delivery of audio, video, and other media over the Internet without the involvement of a multiple-system operator (such as a cable television provider) in the control or distribution of the content. It has several elements:
Content Provider:
Examples include:
- An independent service, such as:
- Netflix or
- Amazon Video,
- Hotstar,
- Google Play Movies,
- myTV (Arabic),
- Sling TV,
- Sony LIV,
- Viewster, or
- Qello (which specializes in concerts).
- A service owned by a traditional terrestrial, cable, or satellite provider, such as DittoTV (owned by Dish TV)
- An international movies brand, such as Eros International or Eros Now
- A service owned by a traditional film or television network, television channel, or content conglomerate, such as BBC Three since 17 Jan 2016, CBSN, CNNGo, HBO Now, Now TV (UK) (owned by Sky), PlayStation Vue (owned by Sony), or Hulu (a joint venture)
- A peer-to-peer video hosting service such as YouTube, Vimeo, or Crunchyroll
- Combination services like TV UOL which combines a Brazilian Internet-only TV station with user-uploaded content, or Crackle, which combines content owned by Sony Pictures with user uploaded content
- Audio-only services like Spotify, though not "Internet television" per se, are sometimes accessible through video-capable devices in the same way
Internet:
The public Internet, which is used for transmission from the streaming servers to the consumer end-user.
Receiver:
The receiver must have an Internet connection, typically by Wi-fi or Ethernet, and could be:
- A web browser running on a personal computer (typically controlled by computer mouse and keyboard) or mobile device, such as Firefox, Google Chrome, or Internet Explorer
- A mobile app running on a smartphone or tablet computer
- A dedicated digital media player, typically with remote control. These can take the form of a small box, or even a stick that plugs directly into an HDMI port. Examples include Roku, Amazon Fire, Apple TV, Google TV, Boxee, and WD TV. Sometimes these boxes allow streaming of content from the local network or storage drive, typically providing an indirect connection between a television and computer or USB stick
- A SmartTV which has Internet capability and built-in software accessed with the remote control
- A Video Game Console connected to the internet such as the Xbox One and PS4.
- A DVD player, Blu-ray player with Internet capabilities in addition to its primary function of playing content from physical discs
- A set-top box or digital video recorder provided by the cable or satellite company or an independent party like TiVo, which has Internet capabilities in addition to its primary function of receiving and recording programming from the non-Internet cable or satellite connection
Not all receiver devices can access all content providers. Most have websites that allow viewing of content in a web browser, but sometimes this is not done due to digital rights management concerns or restrictions. While a web browser has access to any website, some consumers find it inconvenient to control and interact with content with a mouse and keyboard, inconvenient to connect a computer to their television, or confusing.
Many providers have mobile software applications ("apps") dedicated to receive only their own content. Manufacturers of SmartTVs, boxes, sticks, and players must decide which providers to support, typically based either on popularity, common corporate ownership, or receiving payment from the provider.
Display Device:
A display device, which could be:
- A television set or video projector linked to the receiver with a video connector (typically HDMI)
- A smart TV screen
- A computer monitor
- The built-in display of a smartphone or tablet computer.
Comparison with Internet Protocol television (IPTV)
As described above, "Internet television" is "over-the-top technology" (OTT). It is delivered through the open, unmanaged Internet, with the "last-mile" telecom company acting only as the Internet service provider. Both OTT and IPTV use the Internet protocol suite over a packet-switched network to transmit data, but IPTV operates in a closed system - a dedicated, managed network controlled by the local cable, satellite, telephone, or fiber company.
In its simplest form, IPTV simply replaces traditional circuit switched analog or digital television channels with digital channels which happen to use packet-switched transmission. In both the old and new systems, subscribers have set-top boxes or other customer-premises equipment that talks directly over company-owned or dedicated leased lines with central-office servers. Packets never travel over the public Internet, so the television provider can guarantee enough local bandwidth for each customer's needs.
The Internet Protocol is a cheap, standardized way to provide two-way communication and also provide different data (e.g., TV show files) to different customers. This supports DVR-like features for time shifting television, for example to catch up on a TV show that was broadcast hours or days ago, or to replay the current TV show from its beginning. It also supports video on demand - browsing a catalog of videos (such as movies or syndicated television shows) which might be unrelated to the company's scheduled broadcasts. IPTV has an ongoing standardization process (for example, at the European Telecommunications Standards Institute).
Click on any of the following for further amplification about Internet Television:
- Comparison tables
- Technologies used
- Stream quality
- Usage
- Market competitors
- Control
- Archives
- Broadcasting rights
- Profits and costs
- Overview of platforms and availability
- See also:
- Comparison of streaming media systems
- Comparison of video hosting services
- Content delivery network
- Digital television
- Interactive television
- Internet radio
- Home theatre PC
- List of free television software
- List of Internet television providers
- List of streaming media systems
- Multicast
- P2PTV
- Protection of Broadcasts and Broadcasting Organizations Treaty
- Push technology
- Smart TV
- Software as a service
- Television network
- Video advertising
- Web-to-TV
- Media Psychology
- Webcast
- WPIX, Inc. v. ivi, Inc.
How Web 2.0 Has Changed the Way We Use the Internet
YouTube Video The importance of Web 2.0 for business by Cisco Technologies*
* -- Willie Oosthuysen, Director Technical Operations at Cisco Systems, discusses the importance of web2.0 technologies for businesses along with a view on the future of this technology.
Pictured: Some of the better known Websites using Web 2.0 Technology

Web 2.0 describes World Wide Web websites that emphasize user-generated content, usability (ease of use, even by non-experts), and interoperability (this means that a website can work well with other products, systems and devices) for end users.
The term was popularized by Tim O'Reilly and Dale Dougherty at the O'Reilly Media Web 2.0 Conference in late 2004, though it was coined by Darcy DiNucci in 1999.
Web 2.0 does not refer to an update to any technical specification, but to changes in the way Web pages are designed and used.
A Web 2.0 website may allow users to interact and collaborate with each other in a social media dialogue as creators of user-generated content in a virtual community, in contrast to the first generation of Web 1.0-era websites where people were limited to the passive viewing of content.
As well, in contrast to Web 1.0-era websites, in which the text was often unlinked, users of Web 2.0 websites can often "click" on words in the text to access additional content on the website or be linked to an external website.
Examples of Web 2.0 include social networking sites and social media sites (e.g., Facebook), blogs, wikis, folksonomies ("tagging" keywords on websites and links), video sharing sites (e.g., YouTube), hosted services, Web applications ("apps"), collaborative consumption platforms, and mashup applications, that allow users to blend the digital audio from multiple songs together to create new music.
Whether Web 2.0 is substantively different from prior Web technologies has been challenged by World Wide Web inventor Tim Berners-Lee, who describes the term as jargon. His original vision of the Web was "a collaborative medium, a place where we [could] all meet and read and write". On the other hand, the term Semantic Web (sometimes referred to as Web 3.0) was coined by Berners-Lee to refer to a web of data that can be processed by machines.
Click on any of the following blue hyperlinks for more about Web 2.0:
The term was popularized by Tim O'Reilly and Dale Dougherty at the O'Reilly Media Web 2.0 Conference in late 2004, though it was coined by Darcy DiNucci in 1999.
Web 2.0 does not refer to an update to any technical specification, but to changes in the way Web pages are designed and used.
A Web 2.0 website may allow users to interact and collaborate with each other in a social media dialogue as creators of user-generated content in a virtual community, in contrast to the first generation of Web 1.0-era websites where people were limited to the passive viewing of content.
As well, in contrast to Web 1.0-era websites, in which the text was often unlinked, users of Web 2.0 websites can often "click" on words in the text to access additional content on the website or be linked to an external website.
Examples of Web 2.0 include social networking sites and social media sites (e.g., Facebook), blogs, wikis, folksonomies ("tagging" keywords on websites and links), video sharing sites (e.g., YouTube), hosted services, Web applications ("apps"), collaborative consumption platforms, and mashup applications, that allow users to blend the digital audio from multiple songs together to create new music.
Whether Web 2.0 is substantively different from prior Web technologies has been challenged by World Wide Web inventor Tim Berners-Lee, who describes the term as jargon. His original vision of the Web was "a collaborative medium, a place where we [could] all meet and read and write". On the other hand, the term Semantic Web (sometimes referred to as Web 3.0) was coined by Berners-Lee to refer to a web of data that can be processed by machines.
Click on any of the following blue hyperlinks for more about Web 2.0:
- History
- "Web 1.0" including Characteristics
- Web 2.0
- Characteristics including Comparison with Web 1.0
- Technologies
- Concepts
- Usage and Marketing
- Education
- Web-based applications and desktops
- Distribution of media
- Criticism
- Trademark
- See also:
- Cloud computing
- Collective intelligence
- Connectivity of social media
- Crowd computing
- Enterprise social software
- Mass collaboration
- New media
- Office suite
- Open source governance
- Privacy issues of social networking sites
- Social commerce
- Social shopping
- Web 2.0 for development (web2fordev)
- You (Time Person of the Year)
- Libraries in Second Life
- List of free software for Web 2.0 Services
- Cute cat theory of digital activism
- OSW3
- Application domains:
- Sci-Mate
- Business 2.0
- E-learning 2.0
- e-Government (Government 2.0)
- Health 2.0
- Science 2.0
Social Media including a List of the Most Popular Social Media Websites
YouTube Video: The Best Way to Share Videos On Facebook
Pictured: Images of Logos for Some of the Most Popular Social Media Websites

Social media are computer-mediated technologies that allow the creating and sharing of information, ideas, career interests and other forms of expression via virtual communities and networks. The variety of stand-alone and built-in social media services currently available introduces challenges of definition. However, there are some common features.
Social media use web-based technologies, desktop computers and mobile technologies (e.g., smartphones and tablet computers) to create highly interactive platforms through which individuals, communities and organizations can share, co-create, discuss, and modify user-generated content or pre-made content posted online.
They introduce substantial and pervasive changes to communication between businesses, organizations, communities and individuals. Social media changes the way individuals and large organizations communicate.
These changes are the focus of the emerging field of technoself studies. In America, a survey reported that 84 percent of adolescents in America have a Facebook account. Over 60% of 13 to 17-year-olds have at least one profile on social media, with many spending more than two hours a day on social networking sites.
According to Nielsen, Internet users continue to spend more time on social media sites than on any other type of site. At the same time, the total time spent on social media sites in the U.S. across PCs as well as on mobile devices increased by 99 percent to 121 billion minutes in July 2012 compared to 66 billion minutes in July 2011.
For content contributors, the benefits of participating in social media have gone beyond simply social sharing to building reputation and bringing in career opportunities and monetary income.
Social media differ from paper-based or traditional electronic media such as TV broadcasting in many ways, including quality, reach, frequency, usability, immediacy, and permanence. Social media operate in a dialogic transmission system (many sources to many receivers).
This is in contrast to traditional media which operates under a monologic transmission model (one source to many receivers), such as a paper newspaper which is delivered to many subscribers. Some of the most popular social media websites are:
These social media websites have more than 100 million registered users.
Observers have noted a range of positive and negative impacts from social media use. Social media can help to improve individuals' sense of connectedness with real and/or online communities and social media can be an effective communications (or marketing) tool for corporations, entrepreneurs, nonprofit organizations, including advocacy groups and political parties and governments.
At the same time, concerns have been raised about possible links between heavy social media use and depression, and even the issues of cyberbullying, online harassment and "trolling".
Currently, about half of young adults have been cyberbullied and of those, 20 percent said that they have been cyberbullied on a regular basis. Another survey was carried out among 7th grade students in America which is known as the Precaution Process Adoption Model. According to this study 69 percent of 7th grade students claim to have experienced cyberbullying and they also said that it is worse than face to face bullying.
Click on any of the following blue hyperlinks to more information about Social Media Websites:
- Social media are interactive Web 2.0 Internet-based applications.
- User-generated content, such as text posts or comments, digital photos or videos, and data generated through all online interactions, are the lifeblood of social media.
- Users create service-specific profiles for the website or app that are designed and maintained by the social media organization.
- Social media facilitate the development of online social networks by connecting a user's profile with those of other individuals and/or groups.
Social media use web-based technologies, desktop computers and mobile technologies (e.g., smartphones and tablet computers) to create highly interactive platforms through which individuals, communities and organizations can share, co-create, discuss, and modify user-generated content or pre-made content posted online.
They introduce substantial and pervasive changes to communication between businesses, organizations, communities and individuals. Social media changes the way individuals and large organizations communicate.
These changes are the focus of the emerging field of technoself studies. In America, a survey reported that 84 percent of adolescents in America have a Facebook account. Over 60% of 13 to 17-year-olds have at least one profile on social media, with many spending more than two hours a day on social networking sites.
According to Nielsen, Internet users continue to spend more time on social media sites than on any other type of site. At the same time, the total time spent on social media sites in the U.S. across PCs as well as on mobile devices increased by 99 percent to 121 billion minutes in July 2012 compared to 66 billion minutes in July 2011.
For content contributors, the benefits of participating in social media have gone beyond simply social sharing to building reputation and bringing in career opportunities and monetary income.
Social media differ from paper-based or traditional electronic media such as TV broadcasting in many ways, including quality, reach, frequency, usability, immediacy, and permanence. Social media operate in a dialogic transmission system (many sources to many receivers).
This is in contrast to traditional media which operates under a monologic transmission model (one source to many receivers), such as a paper newspaper which is delivered to many subscribers. Some of the most popular social media websites are:
- Facebook (and its associated Facebook Messenger),
- WhatsApp,
- Tumblr,
- Instagram,
- Twitter,
- Baidu Tieba,
- Pinterest,
- LinkedIn,
- Gab,
- Google+,
- YouTube,
- Viber,
- Snapchat,
- and WeChat.
These social media websites have more than 100 million registered users.
Observers have noted a range of positive and negative impacts from social media use. Social media can help to improve individuals' sense of connectedness with real and/or online communities and social media can be an effective communications (or marketing) tool for corporations, entrepreneurs, nonprofit organizations, including advocacy groups and political parties and governments.
At the same time, concerns have been raised about possible links between heavy social media use and depression, and even the issues of cyberbullying, online harassment and "trolling".
Currently, about half of young adults have been cyberbullied and of those, 20 percent said that they have been cyberbullied on a regular basis. Another survey was carried out among 7th grade students in America which is known as the Precaution Process Adoption Model. According to this study 69 percent of 7th grade students claim to have experienced cyberbullying and they also said that it is worse than face to face bullying.
Click on any of the following blue hyperlinks to more information about Social Media Websites:
- Definition and classification
- Distinction from other media
- Monitoring, tracking and analysis
- Building "social authority" and vanity
- Data mining
- Global usage
- Criticisms
- Negative effects
- Positive effects
- Impact on job seeking
- College admission
- Political effects
- Patents
- In the classroom
- Advertising including Tweets containing advertising
- Censorship incidents
- Effects on youth communication
- See also:
- Arab Spring, where social media played a defining role
- Citizen media
- Coke Zero Facial Profiler
- Connectivism (learning theory)
- Connectivity of social media
- Culture jamming
- Human impact of Internet use
- Internet and political revolutions
- List of photo sharing websites
- List of video sharing websites
- List of social networking websites
- Media psychology
- Metcalfe's law
- MMORPG
- Networked learning
- New media
- Online presence management
- Online research community
- Participatory media
- Social media marketing
- Social media mining
- Social media optimization
- Social media surgery
Wikipedia including (1) Editorial Oversight and Control to Assure Accuracy and (2) List of Free Online Resources
YouTube Video: The History of Wikipedia (in two minutes)
YouTube Video: This is Wikipedia
Pictured: Wikipedia Android App on Google Play
Wikipedia is a free online encyclopedia that aims to allow anyone to edit articles. Wikipedia is the largest and most popular general reference work on the Internet and is ranked among the ten most popular websites. Wikipedia is owned by the nonprofit Wikimedia Foundation.
Wikipedia was launched on January 15, 2001, by Jimmy Wales and Larry Sanger. Sanger coined its name, a portmanteau of wiki and encyclopedia. There was only the English language version initially, but it quickly developed similar versions in other languages, which differ in content and in editing practices.
With 5,332,436 articles, the English Wikipedia is the largest of the more than 290 Wikipedia encyclopedias. Overall, Wikipedia consists of more than 40 million articles in more than 250 different languages and, as of February 2014, it had 18 billion page views and nearly 500 million unique visitors each month.
In 2005, Nature published a peer review comparing 42 science articles from Encyclopædia Britannica and Wikipedia, and found that Wikipedia's level of accuracy approached Encyclopædia Britannica's. Criticism of Wikipedia includes claims that it exhibits systemic bias, presents a mixture of "truths, half truths, and some falsehoods", and that, in controversial topics, it is subject to manipulation and spin.
Click on any of the following blue hyperlinks to learn more about about Wikipedia:
Wikipedia; Editorial Oversight and Control:
This page summarizes the various processes and structures by which Wikipedia articles and their editing are editorially controlled, and the processes which are built into that model to ensure quality of article content.
Rather than one sole form of control, Wikipedia relies upon multiple approaches, and these overlap to provide more robust coverage and resilience.
Click on any of the following blue hyperlinks for additional information about Wikipedia Editorial Oversight and Control:
For dealing with vandalism see Wikipedia:Vandalism.
For editing Wikipedia yourself to fix obvious vandalism and errors, see Wikipedia:Contributing to Wikipedia.
General editorial groups:
Specialized working groups:
Philosophy and broader structure: ___________________________________________________________________________
Click on any of the following blue hyperlinks for more about
Wikipedia's List of Free Online Resources:
Wikipedia was launched on January 15, 2001, by Jimmy Wales and Larry Sanger. Sanger coined its name, a portmanteau of wiki and encyclopedia. There was only the English language version initially, but it quickly developed similar versions in other languages, which differ in content and in editing practices.
With 5,332,436 articles, the English Wikipedia is the largest of the more than 290 Wikipedia encyclopedias. Overall, Wikipedia consists of more than 40 million articles in more than 250 different languages and, as of February 2014, it had 18 billion page views and nearly 500 million unique visitors each month.
In 2005, Nature published a peer review comparing 42 science articles from Encyclopædia Britannica and Wikipedia, and found that Wikipedia's level of accuracy approached Encyclopædia Britannica's. Criticism of Wikipedia includes claims that it exhibits systemic bias, presents a mixture of "truths, half truths, and some falsehoods", and that, in controversial topics, it is subject to manipulation and spin.
Click on any of the following blue hyperlinks to learn more about about Wikipedia:
- History
- Openness
- Policies and laws including Content policies and guidelines
- Governance
- Community including Diversity
- Language editions
- Critical reception
- Operation
- Access to content
- Cultural impact
- Related projects
- See also:
- Outline of Wikipedia – guide to the subject of Wikipedia presented as a tree structured list of its subtopics; for an outline of the contents of Wikipedia, see Portal: Contents/Outlines
- Conflict-of-interest editing on Wikipedia
- Democratization of knowledge
- Interpedia, an early proposal for a collaborative Internet encyclopedia
- List of Internet encyclopedias
- Network effect
- Print Wikipedia art project to visualize how big Wikipedia is. In cooperation with Wikimedia foundation.
- QRpedia – multilingual, mobile interface to Wikipedia
- Wikipedia Review
Wikipedia; Editorial Oversight and Control:
This page summarizes the various processes and structures by which Wikipedia articles and their editing are editorially controlled, and the processes which are built into that model to ensure quality of article content.
Rather than one sole form of control, Wikipedia relies upon multiple approaches, and these overlap to provide more robust coverage and resilience.
Click on any of the following blue hyperlinks for additional information about Wikipedia Editorial Oversight and Control:
- Overview of editorial structure
- Wikipedia's editorial control process
- Types of control
- Effects of control systems
- Types of access
- Individual editors' power to control and correct poor editorship
- Editorial quality review and article improvement
- Examples
For dealing with vandalism see Wikipedia:Vandalism.
For editing Wikipedia yourself to fix obvious vandalism and errors, see Wikipedia:Contributing to Wikipedia.
- About Wikipedia
- Wikipedia:Quality control
- Researching with Wikipedia and Reliability of Wikipedia
- Wikipedia:User access levels
General editorial groups:
- Category:Wikipedians in the Cleanup Taskforce
- Category:Wikipedian new page patrollers
- Category:Wikipedians in the Counter Vandalism Unit (c. 2,600 editors)
- Category:Wikipedian recent changes patrollers (c. 3,000 editors)
Specialized working groups:
- Category:WikiProjects - index of subject-based editorial taskforces ("WikiProjects") on Wikipedia
- Category:Wikipedians by WikiProject - members of the various specialist subject area taskforces
- Editorial assistance software coded for Wikipedia: Category:Wikipedia bots
Philosophy and broader structure: ___________________________________________________________________________
Click on any of the following blue hyperlinks for more about
Wikipedia's List of Free Online Resources:
- General resources and link lists
- Newspapers and news agencies
- Biographies
- Information and library science
- Philosophy
- Science, mathematics, medicine & nature
- Social sciences
- Sports
- See also:
- Wikipedia:Advanced source searching
- Wikipedia:Reliable sources/Noticeboard
- Wikipedia:Verifiability
- Wikipedia:WikiProject Resource Exchange - a project where Wikipedians offer to search in their resources for the reference that you are looking for
- Wiktionary:Wiktionary:Other dictionaries on the Web
Blogs including a List of Blogs and a Glossary of Blogging
YouTube Video: How to Make a Blog - Step by Step - 2015
YouTube Video by Andrew Sullivan* on quitting blogging: "It was killing me."
* -- Andrew Sullivan

For an alphanumerical List of Blogs, click here.
For a Glossary of Blogging Terms, click here.
A blog (a truncation of the expression weblog) is a discussion or informational website published on the World Wide Web consisting of discrete, often informal diary-style text entries ("posts").
Posts are typically displayed in reverse chronological order, so that the most recent post appears first, at the top of the web page. Until 2009, blogs were usually the work of a single individual, occasionally of a small group, and often covered a single subject or topic.
In the 2010s, "multi-author blogs" (MABs) have developed, with posts written by large numbers of authors and sometimes professionally edited. MABs from newspapers, other media outlets, universities, think tanks, advocacy groups, and similar institutions account for an increasing quantity of blog traffic. The rise of Twitter and other "microblogging" systems helps integrate MABs and single-author blogs into the news media. Blog can also be used as a verb, meaning to maintain or add content to a blog.
The emergence and growth of blogs in the late 1990s coincided with the advent of web publishing tools that facilitated the posting of content by non-technical users who did not have much experience with HTML or computer programming. Previously, a knowledge of such technologies as HTML and File Transfer Protocol had been required to publish content on the Web, and as such, early Web users tended to be hackers and computer enthusiasts.
In the 2010s, majority of blogs are interactive Web 2.0 websites, allowing visitors to leave online comments and even message each other via GUI widgets on the blogs, and it is this interactivity that distinguishes them from other static websites.
In that sense, blogging can be seen as a form of social networking service. Indeed, bloggers do not only produce content to post on their blogs, but also build social relations with their readers and other bloggers.
However, there are high-readership blogs which do not allow comments.
Many blogs provide commentary on a particular subject or topic, ranging from politics to sports. Others function as more personal online diaries, and others function more as online brand advertising of a particular individual or company. A typical blog combines text, digital images, and links to other blogs, web pages, and other media related to its topic.
The ability of readers to leave comments in an interactive format is an important contribution to the popularity of many blogs. However, blog owners or authors need to moderate and filter online comments to remove hate speech or other offensive content. Most blogs are primarily textual, although some focus on art (art blogs), photographs (photoblogs), videos (video blogs or "vlogs"), music (MP3 blogs), and audio (podcasts). Microblogging is another type of blogging, featuring very short posts.
In education, blogs can be used as instructional resources. These blogs are referred to as edublogs. On 16 February 2011, there were over 156 million public blogs in existence. On 20 February 2014, there were around 172 million Tumblr and 75.8 million WordPress blogs in existence worldwide.
According to critics and other bloggers, Blogger is the most popular blogging service used today. However, Blogger does not offer public statistics. Technorati has 1.3 million blogs as of February 22, 2014.
Click on any of the following bluehyperlinks for additional information about Blogs:
For a Glossary of Blogging Terms, click here.
A blog (a truncation of the expression weblog) is a discussion or informational website published on the World Wide Web consisting of discrete, often informal diary-style text entries ("posts").
Posts are typically displayed in reverse chronological order, so that the most recent post appears first, at the top of the web page. Until 2009, blogs were usually the work of a single individual, occasionally of a small group, and often covered a single subject or topic.
In the 2010s, "multi-author blogs" (MABs) have developed, with posts written by large numbers of authors and sometimes professionally edited. MABs from newspapers, other media outlets, universities, think tanks, advocacy groups, and similar institutions account for an increasing quantity of blog traffic. The rise of Twitter and other "microblogging" systems helps integrate MABs and single-author blogs into the news media. Blog can also be used as a verb, meaning to maintain or add content to a blog.
The emergence and growth of blogs in the late 1990s coincided with the advent of web publishing tools that facilitated the posting of content by non-technical users who did not have much experience with HTML or computer programming. Previously, a knowledge of such technologies as HTML and File Transfer Protocol had been required to publish content on the Web, and as such, early Web users tended to be hackers and computer enthusiasts.
In the 2010s, majority of blogs are interactive Web 2.0 websites, allowing visitors to leave online comments and even message each other via GUI widgets on the blogs, and it is this interactivity that distinguishes them from other static websites.
In that sense, blogging can be seen as a form of social networking service. Indeed, bloggers do not only produce content to post on their blogs, but also build social relations with their readers and other bloggers.
However, there are high-readership blogs which do not allow comments.
Many blogs provide commentary on a particular subject or topic, ranging from politics to sports. Others function as more personal online diaries, and others function more as online brand advertising of a particular individual or company. A typical blog combines text, digital images, and links to other blogs, web pages, and other media related to its topic.
The ability of readers to leave comments in an interactive format is an important contribution to the popularity of many blogs. However, blog owners or authors need to moderate and filter online comments to remove hate speech or other offensive content. Most blogs are primarily textual, although some focus on art (art blogs), photographs (photoblogs), videos (video blogs or "vlogs"), music (MP3 blogs), and audio (podcasts). Microblogging is another type of blogging, featuring very short posts.
In education, blogs can be used as instructional resources. These blogs are referred to as edublogs. On 16 February 2011, there were over 156 million public blogs in existence. On 20 February 2014, there were around 172 million Tumblr and 75.8 million WordPress blogs in existence worldwide.
According to critics and other bloggers, Blogger is the most popular blogging service used today. However, Blogger does not offer public statistics. Technorati has 1.3 million blogs as of February 22, 2014.
Click on any of the following bluehyperlinks for additional information about Blogs:
- History
- Types
- Community and cataloging
- Popularity
- Blurring with the mass media
- Consumer-generated advertising
- Legal and social consequences
- See also:
- Bitter Lawyer
- Blog award
- BROG
- Chat room
- Citizen journalism
- Collaborative blog
- Comparison of free blog hosting services
- Customer engagement
- Interactive journalism
- Internet think tank
- Israblog
- Bernando LaPallo
- List of family-and-homemaking blogs
- Mass collaboration
- Prison blogs
- Sideblog
- Social blogging
- Webmaster
- Web template system
- Web traffic
Voice over Internet Protocol (VoIP)
YouTube Video: Cell Phone Facts : How Does Vonage Phone Service Work?
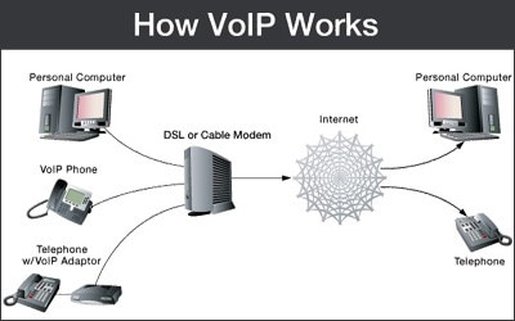
Voice over Internet Protocol (Voice over IP, VoIP and IP telephony) is a methodology and group of technologies for the delivery of voice communications and multimedia sessions over Internet Protocol (IP) networks, such as the Internet.
The terms Internet telephony, broadband telephony, and broadband phone service specifically refer to the provisioning of communications services (voice, fax, SMS, voice-messaging) over the public Internet, rather than via the public switched telephone network (PSTN).
The steps and principles involved in originating VoIP telephone calls are similar to traditional digital telephony and involve signaling, channel setup, digitization of the analog voice signals, and encoding. Instead of being transmitted over a circuit-switched network; however, the digital information is packetized, and transmission occurs as IP packets over a packet-switched network.
They transport audio streams using special media delivery protocols that encode audio and video with audio codecs, and video codecs. Various codecs exist that optimize the media stream based on application requirements and network bandwidth; some implementations rely on narrowband and compressed speech, while others support high fidelity stereo codecs.
Some popular codecs include μ-law and a-law versions of G.711, G.722, a popular open source voice codec known as iLBC, a codec that only uses 8 kbit/s each way called G.729, and many others.
Early providers of voice-over-IP services offered business models and technical solutions that mirrored the architecture of the legacy telephone network.
Second-generation providers, such as Skype, have built closed networks for private user bases, offering the benefit of free calls and convenience while potentially charging for access to other communication networks, such as the PSTN. This has limited the freedom of users to mix-and-match third-party hardware and software.
Third-generation providers, such as Google Talk, have adopted the concept of federated VoIP—which is a departure from the architecture of the legacy networks. These solutions typically allow dynamic interconnection between users on any two domains on the Internet when a user wishes to place a call.
In addition to VoIP phones, VoIP is available on many smartphones, personal computers, and on Internet access devices. Calls and SMS text messages may be sent over 3G/4G or Wi-Fi.
Click on any of the following blue hyperlinks for further information about Voice over Internet Protocol (VoIP):
The terms Internet telephony, broadband telephony, and broadband phone service specifically refer to the provisioning of communications services (voice, fax, SMS, voice-messaging) over the public Internet, rather than via the public switched telephone network (PSTN).
The steps and principles involved in originating VoIP telephone calls are similar to traditional digital telephony and involve signaling, channel setup, digitization of the analog voice signals, and encoding. Instead of being transmitted over a circuit-switched network; however, the digital information is packetized, and transmission occurs as IP packets over a packet-switched network.
They transport audio streams using special media delivery protocols that encode audio and video with audio codecs, and video codecs. Various codecs exist that optimize the media stream based on application requirements and network bandwidth; some implementations rely on narrowband and compressed speech, while others support high fidelity stereo codecs.
Some popular codecs include μ-law and a-law versions of G.711, G.722, a popular open source voice codec known as iLBC, a codec that only uses 8 kbit/s each way called G.729, and many others.
Early providers of voice-over-IP services offered business models and technical solutions that mirrored the architecture of the legacy telephone network.
Second-generation providers, such as Skype, have built closed networks for private user bases, offering the benefit of free calls and convenience while potentially charging for access to other communication networks, such as the PSTN. This has limited the freedom of users to mix-and-match third-party hardware and software.
Third-generation providers, such as Google Talk, have adopted the concept of federated VoIP—which is a departure from the architecture of the legacy networks. These solutions typically allow dynamic interconnection between users on any two domains on the Internet when a user wishes to place a call.
In addition to VoIP phones, VoIP is available on many smartphones, personal computers, and on Internet access devices. Calls and SMS text messages may be sent over 3G/4G or Wi-Fi.
Click on any of the following blue hyperlinks for further information about Voice over Internet Protocol (VoIP):
- Protocols
- Adoption
- Quality of service
- VoIP performance metrics
- PSTN integration
- Fax support
- Power requirements
- Security
- Caller ID
- Compatibility with traditional analog telephone sets
- Support for other telephony devices
- Operational cost
- Regulatory and legal issues in the United States
- History including Milestones
- See also:
- Audio over IP
- Communications Assistance For Law Enforcement Act
- Comparison of audio network protocols
- Comparison of VoIP software
- Differentiated services
- High bit rate audio video over Internet Protocol
- Integrated services
- Internet fax
- IP Multimedia Subsystem
- List of VoIP companies
- Mobile VoIP
- Network Voice Protocol
- RTP audio video profile
- SIP Trunking
- UNIStim
- Voice VPN
- VoiceXML
- VoIP recording
Online Dating Websites, including a Comparison (as well as a Report about Online Dating Sites by Consumer Reports, February, 2017 Issue.
YouTube Video about Online Dating - A Funny Online Dating Video

For a comparison of Online Dating Websites, click here.
Click here to read the magazine article "Match Me if You Can" in the February, 2017 Issue of Consumer Reports
Online dating or Internet dating is a personal introductory system where individuals can find and contact each other over the Internet to arrange a date, usually with the objective of developing a personal, romantic, or sexual relationship.
Online dating services usually provide non-moderated matchmaking over the Internet, through the use of personal computers or cell phones. Users of an online dating service would usually provide personal information, to enable them to search the service provider's database for other individuals. Members use criteria other members set, such as age range, gender and location.
Online dating sites use market metaphors to match people. Match metaphors are conceptual frameworks that allow individuals to make sense of new concepts by drawing upon familiar experiences and frame-works. This metaphor of the marketplace – a place where people go to "shop" for potential romantic partners and to "sell" themselves in hopes of creating a successful romantic relationship – is highlighted by the layout and functionality of online dating websites.
The marketplace metaphor may also resonate with participants' conceptual orientation towards the process of finding a romantic partner. Most sites allow members to upload photos or videos of themselves and browse the photos and videos of others. Sites may offer additional services, such as webcasts, online chat, telephone chat (VOIP), and message boards.
Some sites provide free registration, but may offer services which require a monthly fee. Other sites depend on advertising for their revenue. Some sites such as OkCupid.com, POF.com and Badoo.com are free and offer additional paid services in a freemium revenue model.
Some sites are broad-based, with members coming from a variety of backgrounds looking for different types of relationships. Other sites are more specific, based on the type of members, interests, location, or relationship desired.
A 2005 study of data collected by the Pew Internet & American Life Project found that individuals are more likely to use an online dating service if they use the internet for a greater amount of tasks and less likely to use such a service if they are trusting of others.
Click on any of the following blue hyperlinks for additional information about online dating services:
Click here to read the magazine article "Match Me if You Can" in the February, 2017 Issue of Consumer Reports
Online dating or Internet dating is a personal introductory system where individuals can find and contact each other over the Internet to arrange a date, usually with the objective of developing a personal, romantic, or sexual relationship.
Online dating services usually provide non-moderated matchmaking over the Internet, through the use of personal computers or cell phones. Users of an online dating service would usually provide personal information, to enable them to search the service provider's database for other individuals. Members use criteria other members set, such as age range, gender and location.
Online dating sites use market metaphors to match people. Match metaphors are conceptual frameworks that allow individuals to make sense of new concepts by drawing upon familiar experiences and frame-works. This metaphor of the marketplace – a place where people go to "shop" for potential romantic partners and to "sell" themselves in hopes of creating a successful romantic relationship – is highlighted by the layout and functionality of online dating websites.
The marketplace metaphor may also resonate with participants' conceptual orientation towards the process of finding a romantic partner. Most sites allow members to upload photos or videos of themselves and browse the photos and videos of others. Sites may offer additional services, such as webcasts, online chat, telephone chat (VOIP), and message boards.
Some sites provide free registration, but may offer services which require a monthly fee. Other sites depend on advertising for their revenue. Some sites such as OkCupid.com, POF.com and Badoo.com are free and offer additional paid services in a freemium revenue model.
Some sites are broad-based, with members coming from a variety of backgrounds looking for different types of relationships. Other sites are more specific, based on the type of members, interests, location, or relationship desired.
A 2005 study of data collected by the Pew Internet & American Life Project found that individuals are more likely to use an online dating service if they use the internet for a greater amount of tasks and less likely to use such a service if they are trusting of others.
Click on any of the following blue hyperlinks for additional information about online dating services:
- Trends
- Social networking
- Problems
- Comparisons in marriage health: traditional versus online first encounters
- Government regulation
- Online introduction services
- Free dating
- In popular culture
- See also:
Meetup Social Networking*
* -- Click here to visit Meetup.com
YouTube Video: Meetup.com Basics - Video Tutorial
YouTube Video: 10 Keys for Success If You're a Meetup.com Organizer
Pictured: Example Meetup groups

Meetup is an online social networking portal that facilitates offline group meetings in various localities around the world. Meetup allows members to find and join groups unified by a common interest, such as politics, books, games, movies, health, pets, careers or hobbies.
The company is based in New York City and was co-founded in 2002 by Scott Heiferman and Matt Meeker. Meetup was designed as a way for organizers to manage the many functions associated with in-person meetings and for individuals to find groups that fit their interests.
Users enter their city or their postal code and tag the topic they want to meet about. The website/app helps them locate a group to arrange a place and time to meet. Topic listings are also available for users who only enter a location.
The service is free of charge to individuals who log in as members. They have the ability to join different groups as defined by the rules of the individual groups themselves.
Meetup receives revenue by charging fees to organizers of groups. Currently US$9.99/month for their basic plan, which includes a maximum of 4 organizers and maximum of 50 members. The unlimited pricing starts at US$14.99/month or six months for $90, which gives the organizer up to three groups.
Organizers can customize the Meetup site by selecting from a variety of templates for the overall appearance of their site. They can also create customized pages within the group's Meetup site.
Site group functions include:
The website and associated app also allow users to contact meetup group members through a messaging platform and comments left on individual event listings. After each event and email is shared that allows users to click "Good to see you" and establish further connection with group members.
History:
Following the September 11 attacks in 2001, the site's co-founder Scott Heiferman publicly stated in 2011 that the manner in which people in New York City came together in the aftermath of that traumatic event inspired him to use the Internet to make it easier for people to connect with strangers in their community.
Launching on June 12, 2002, it quickly became an organizing tool for a variety of common interests including fan groups, outdoor enthusiasts, community activists, support groups, and more.
The Howard Dean campaign incorporated internet-based grassroots organization after learning Meetup members were outpacing traditional organization methods. Having changed the political landscape, it is still being used for political campaigns today.
On February 27 and March 1, 2014, a denial-of-service attack forced Meetup's website offline.
On July 10, 2015, Meetup announced a new pricing plan update. Smaller Meetups pay a little less and larger Meetups pay a little more.
As of August 2015 the company claimed to have 22.77 million members in 180 countries and 210,240 groups, although these figures may include inactive members and groups.
Other meeting exchange networks:
The company is based in New York City and was co-founded in 2002 by Scott Heiferman and Matt Meeker. Meetup was designed as a way for organizers to manage the many functions associated with in-person meetings and for individuals to find groups that fit their interests.
Users enter their city or their postal code and tag the topic they want to meet about. The website/app helps them locate a group to arrange a place and time to meet. Topic listings are also available for users who only enter a location.
The service is free of charge to individuals who log in as members. They have the ability to join different groups as defined by the rules of the individual groups themselves.
Meetup receives revenue by charging fees to organizers of groups. Currently US$9.99/month for their basic plan, which includes a maximum of 4 organizers and maximum of 50 members. The unlimited pricing starts at US$14.99/month or six months for $90, which gives the organizer up to three groups.
Organizers can customize the Meetup site by selecting from a variety of templates for the overall appearance of their site. They can also create customized pages within the group's Meetup site.
Site group functions include:
- Schedule meetings and automate notices to members for the same
- The ability to assign different leadership responsibilities and access to the group data
- The ability to accept RSVPs for an event
- The ability to monetize groups, accept and track membership and/or meeting payments through WePay
- Create a file repository for group access
- Post photo libraries of events
- Manage communications between group members
- Post group polls
The website and associated app also allow users to contact meetup group members through a messaging platform and comments left on individual event listings. After each event and email is shared that allows users to click "Good to see you" and establish further connection with group members.
History:
Following the September 11 attacks in 2001, the site's co-founder Scott Heiferman publicly stated in 2011 that the manner in which people in New York City came together in the aftermath of that traumatic event inspired him to use the Internet to make it easier for people to connect with strangers in their community.
Launching on June 12, 2002, it quickly became an organizing tool for a variety of common interests including fan groups, outdoor enthusiasts, community activists, support groups, and more.
The Howard Dean campaign incorporated internet-based grassroots organization after learning Meetup members were outpacing traditional organization methods. Having changed the political landscape, it is still being used for political campaigns today.
On February 27 and March 1, 2014, a denial-of-service attack forced Meetup's website offline.
On July 10, 2015, Meetup announced a new pricing plan update. Smaller Meetups pay a little less and larger Meetups pay a little more.
As of August 2015 the company claimed to have 22.77 million members in 180 countries and 210,240 groups, although these figures may include inactive members and groups.
Other meeting exchange networks:
Podcasts, including a List of Podcasting Companies
YouTube Video: Podcasting 101: How to Make a Podcast
Pictured: Illustration featuring the Podcasting Company "How Stuff Works": click here to visit website
Click here for a List of Podcasting Companies.
A podcast is an episodic series of digital media files which a user can set up so that new episodes are automatically downloaded via web syndication to the user's own local computer or portable media player.
The word arose as a portmanteau of "iPod" (a brand of media player) and "broadcast".
Thus, the files distributed are typically in audio or video formats, but may sometimes include other file formats such as PDF or ePub.
The distributor of a podcast maintains a central list of the files on a server as a web feed that can be accessed through the Internet. The listener or viewer uses special client application software on a computer or media player, known as a podcatcher, which accesses this web feed, checks it for updates, and downloads any new files in the series.
This process can be automated so that new files are downloaded automatically, which may seem to the user as though new episodes are broadcast or "pushed" to them. Files are stored locally on the user's device, ready for offline use.
Podcasting contrasts with webcasting or streaming which do not allow for offline listening, although most podcasts may also be streamed on demand as an alternative to download. Many podcast players (apps as well as dedicated devices) allow listeners to adjust the playback speed.
Some have labeled podcasting as a converged medium bringing together audio, the web, and portable media players, as well as a disruptive technology that has caused some people in the radio business to reconsider established practices and preconceptions about audiences, consumption, production, and distribution.
Podcasts are usually free of charge to listeners and can often be created for little to no cost, which sets them apart from the traditional model of "gate-kept" media and production tools. It is very much a horizontal media form: producers are consumers, consumers may become producers, and both can engage in conversations with each other.
Click on any of the following blue hyperlinks for additional information about Podcasts:
A podcast is an episodic series of digital media files which a user can set up so that new episodes are automatically downloaded via web syndication to the user's own local computer or portable media player.
The word arose as a portmanteau of "iPod" (a brand of media player) and "broadcast".
Thus, the files distributed are typically in audio or video formats, but may sometimes include other file formats such as PDF or ePub.
The distributor of a podcast maintains a central list of the files on a server as a web feed that can be accessed through the Internet. The listener or viewer uses special client application software on a computer or media player, known as a podcatcher, which accesses this web feed, checks it for updates, and downloads any new files in the series.
This process can be automated so that new files are downloaded automatically, which may seem to the user as though new episodes are broadcast or "pushed" to them. Files are stored locally on the user's device, ready for offline use.
Podcasting contrasts with webcasting or streaming which do not allow for offline listening, although most podcasts may also be streamed on demand as an alternative to download. Many podcast players (apps as well as dedicated devices) allow listeners to adjust the playback speed.
Some have labeled podcasting as a converged medium bringing together audio, the web, and portable media players, as well as a disruptive technology that has caused some people in the radio business to reconsider established practices and preconceptions about audiences, consumption, production, and distribution.
Podcasts are usually free of charge to listeners and can often be created for little to no cost, which sets them apart from the traditional model of "gate-kept" media and production tools. It is very much a horizontal media form: producers are consumers, consumers may become producers, and both can engage in conversations with each other.
Click on any of the following blue hyperlinks for additional information about Podcasts:
C/Net including its Website
YouTube Video of Top 5 Most Anticipated Products Presented by C/Net
Pictured: C/Net Logo
CNET (stylized as c|net) is an American media website that publishes reviews, news, articles, blogs, podcasts and videos on technology and consumer electronics globally.
Founded in 1994 by Halsey Minor and Shelby Bonnie, it was the flagship brand of CNET Networks and became a brand of CBS Interactive through CNET Networks' acquisition in 2008.
CNET originally produced content for radio and television in addition to its website and now uses new media distribution methods through its Internet television network, CNET Video, and its podcast and blog networks.
In addition CNET currently has region-specific and language-specific editions. These include the United Kingdom, Australia, China, Japan, French, German, Korean and Spanish.
According to third-party web analytics providers, Alexa and SimilarWeb, CNET is the highest-read technology news source on the Web, with over 200 million readers per month, being among the 200 most visited websites globally, as of 2015.
Click on any of the following blue hyperlinks for further information about C/Net:
Founded in 1994 by Halsey Minor and Shelby Bonnie, it was the flagship brand of CNET Networks and became a brand of CBS Interactive through CNET Networks' acquisition in 2008.
CNET originally produced content for radio and television in addition to its website and now uses new media distribution methods through its Internet television network, CNET Video, and its podcast and blog networks.
In addition CNET currently has region-specific and language-specific editions. These include the United Kingdom, Australia, China, Japan, French, German, Korean and Spanish.
According to third-party web analytics providers, Alexa and SimilarWeb, CNET is the highest-read technology news source on the Web, with over 200 million readers per month, being among the 200 most visited websites globally, as of 2015.
Click on any of the following blue hyperlinks for further information about C/Net:
- History
- Malware Infection in Downloads
- Dispute with Snap Technologies
- Hopper controversy
- Sections
- See also:
Online Shopping Websites
YouTube Video: Tips for safe and simple online shopping
Online shopping is a form of electronic commerce which allows consumers to directly buy goods or services from a seller over the Internet using a web browser.
Consumers find a product of interest by visiting the website of the retailer directly or by searching among alternative vendors using a shopping search engine, which displays the same product's availability and pricing at different e-retailers. As of 2016, customers can shop online using a range of different computers and devices, including desktop computers, laptops, tablet computers and smartphones.
An online shop evokes the physical analogy of buying products or services at a regular "bricks-and-mortar" retailer or shopping center; the process is called business-to-consumer (B2C) online shopping. When an online store is set up to enable businesses to buy from another businesses, the process is called business-to-business (B2B) online shopping. A typical online store enables the customer to browse the firm's range of products and services, view photos or images of the products, along with information about the product specifications, features and prices.
Online stores typically enable shoppers to use "search" features to find specific models, brands or items. Online customers must have access to the Internet and a valid method of payment in order to complete a transaction, such as a credit card, an Interac-enabled debit card, or a service such as PayPal.
For physical products (e.g., paperback books or clothes), the e-tailer ships the products to the customer; for digital products, such as digital audio files of songs or software, the e-tailer typically sends the file to the customer over the Internet.
The largest of these online retailing corporations are Alibaba, Amazon.com, and eBay.
Terminology:
Alternative names for the activity are "e-tailing", a shortened form of "electronic retail" or "e-shopping", a shortened form of "electronic shopping".
An online store may also be called an e-web-store, e-shop, e-store, Internet shop, web-shop, web-store, online store, online storefront and virtual store.
Mobile commerce (or m-commerce) describes purchasing from an online retailer's mobile device-optimized website or software application ("app"). These websites or apps are designed to enable customers to browse through a companies' products and services on tablet computers and smartphones.
Click on any of the following blue hyperlinks for additional information about Online Shopping:
Consumers find a product of interest by visiting the website of the retailer directly or by searching among alternative vendors using a shopping search engine, which displays the same product's availability and pricing at different e-retailers. As of 2016, customers can shop online using a range of different computers and devices, including desktop computers, laptops, tablet computers and smartphones.
An online shop evokes the physical analogy of buying products or services at a regular "bricks-and-mortar" retailer or shopping center; the process is called business-to-consumer (B2C) online shopping. When an online store is set up to enable businesses to buy from another businesses, the process is called business-to-business (B2B) online shopping. A typical online store enables the customer to browse the firm's range of products and services, view photos or images of the products, along with information about the product specifications, features and prices.
Online stores typically enable shoppers to use "search" features to find specific models, brands or items. Online customers must have access to the Internet and a valid method of payment in order to complete a transaction, such as a credit card, an Interac-enabled debit card, or a service such as PayPal.
For physical products (e.g., paperback books or clothes), the e-tailer ships the products to the customer; for digital products, such as digital audio files of songs or software, the e-tailer typically sends the file to the customer over the Internet.
The largest of these online retailing corporations are Alibaba, Amazon.com, and eBay.
Terminology:
Alternative names for the activity are "e-tailing", a shortened form of "electronic retail" or "e-shopping", a shortened form of "electronic shopping".
An online store may also be called an e-web-store, e-shop, e-store, Internet shop, web-shop, web-store, online store, online storefront and virtual store.
Mobile commerce (or m-commerce) describes purchasing from an online retailer's mobile device-optimized website or software application ("app"). These websites or apps are designed to enable customers to browse through a companies' products and services on tablet computers and smartphones.
Click on any of the following blue hyperlinks for additional information about Online Shopping:
- History
- International statistics
- Customers
- Product selection
- Payment
- Product delivery
- Shopping cart systems
- Design
- Market share
- Advantages
- Disadvantages
- Product suitability
- Aggregation
- Impact of reviews on consumer behaviour
- See also:
- Bricks and clicks business model
- Comparison of free software e-commerce web application frameworks
- Dark store
- Direct imports
- Digital distribution
- Electronic business
- Online auction business model
- Online music store
- Online pharmacy
- Online shopping malls
- Online shopping rewards
- Open catalogue
- Personal shopper
- Retail therapy
- Types of retail outlets
- Tourist trap
HowStuffWorks (Website)*
*-- Go to Website HowStuffWorks
YouTube Video about "How Stuff Works"
HowStuffWorks is an American commercial educational website founded by Marshall Brain to provide its target audience an insight into the way many things work. The site uses various media to explain complex concepts, terminology, and mechanisms—including photographs, diagrams, videos, animations, and articles.
A documentary television series with the same name also premiered in November 2008 on the Discovery Channel.
Click on any of the following blue hyperlinks for more about the website "HowStuffWorks":
A documentary television series with the same name also premiered in November 2008 on the Discovery Channel.
Click on any of the following blue hyperlinks for more about the website "HowStuffWorks":
Social and Cultural Phenomena Specific to the Internet, including a List
YouTube Video: Global Internet Phenomena Facts
Pictured: Telecommunications fraud is an oft-talked about, but little-understood issue facing communications service providers (CSPs). Telecommunications fraud by its industry definition is the use of voice, data, or other telecommunication services by a subscriber with no intention for payment of that usage. Industry studies have estimated that fraud costs operators billions of dollars each year, with the costs of that usage having to be absorbed by CSP as passed down to both residential and commercial subscribers.
An Internet Phenomenon is an activity, concept, catchphrase or piece of media which spreads, often as mimicry, from person to person via the Internet. Some examples include posting a photo of people lying down in public places (called "planking") and uploading a short video of people dancing to the Harlem Shake.
A meme is "an idea, behavior, or style that spreads from person to person within a culture".
An Internet meme may take the form of an image (typically an image macro), hyperlink, video, website, or hashtag. It may be just a word or phrase, including an intentional misspelling.
These small movements tend to spread from person to person via social networks, blogs, direct email, or news sources. They may relate to various existing Internet cultures or subcultures, often created or spread on various websites, or by Usenet boards and other such early-internet communications facilities. Fads and sensations tend to grow rapidly on the Internet, because the instant communication facilitates word-of-mouth transmission.
The word meme was coined by Richard Dawkins in his 1976 book The Selfish Gene, as an attempt to explain the way cultural information spreads; Internet memes are a subset of this general meme concept specific to the culture and environment of the Internet.
The concept of the Internet meme was first proposed by Mike Godwin in the June 1993 issue of Wired. In 2013 Dawkins characterized an Internet meme as being a meme deliberately altered by human creativity—distinguished from biological genes and Dawkins' pre-Internet concept of a meme which involved mutation by random change and spreading through accurate replication as in Darwinian selection.
Dawkins explained that Internet memes are thus a "hijacking of the original idea", the very idea of a meme having mutated and evolved in this new direction. Further, Internet memes carry an additional property that ordinary memes do not—Internet memes leave a footprint in the media through which they propagate (for example, social networks) that renders them traceable and analyzable.
Internet memes are a subset that Susan Blackmore called temes—memes which live in technological artifacts instead of the human mind.
Image macros are often confused with internet memes and are often miscited as such, usually by their creators. However, there is a key distinction between the two. Primarily this distinction lies within the subject's recognizability in internet pop-culture. While such an image may display an existing meme, or in fact a macro itself may even eventually become a meme, it does not qualify as one until it reaches approximately the same level of mass recognition as required for a person to be considered a celebrity.
Click on any of the below blue hyperlinks for examples of Internet Phenomena:
Click on any of the following blue hyperlinks to learn more about Internet Phenomena:
A meme is "an idea, behavior, or style that spreads from person to person within a culture".
An Internet meme may take the form of an image (typically an image macro), hyperlink, video, website, or hashtag. It may be just a word or phrase, including an intentional misspelling.
These small movements tend to spread from person to person via social networks, blogs, direct email, or news sources. They may relate to various existing Internet cultures or subcultures, often created or spread on various websites, or by Usenet boards and other such early-internet communications facilities. Fads and sensations tend to grow rapidly on the Internet, because the instant communication facilitates word-of-mouth transmission.
The word meme was coined by Richard Dawkins in his 1976 book The Selfish Gene, as an attempt to explain the way cultural information spreads; Internet memes are a subset of this general meme concept specific to the culture and environment of the Internet.
The concept of the Internet meme was first proposed by Mike Godwin in the June 1993 issue of Wired. In 2013 Dawkins characterized an Internet meme as being a meme deliberately altered by human creativity—distinguished from biological genes and Dawkins' pre-Internet concept of a meme which involved mutation by random change and spreading through accurate replication as in Darwinian selection.
Dawkins explained that Internet memes are thus a "hijacking of the original idea", the very idea of a meme having mutated and evolved in this new direction. Further, Internet memes carry an additional property that ordinary memes do not—Internet memes leave a footprint in the media through which they propagate (for example, social networks) that renders them traceable and analyzable.
Internet memes are a subset that Susan Blackmore called temes—memes which live in technological artifacts instead of the human mind.
Image macros are often confused with internet memes and are often miscited as such, usually by their creators. However, there is a key distinction between the two. Primarily this distinction lies within the subject's recognizability in internet pop-culture. While such an image may display an existing meme, or in fact a macro itself may even eventually become a meme, it does not qualify as one until it reaches approximately the same level of mass recognition as required for a person to be considered a celebrity.
Click on any of the below blue hyperlinks for examples of Internet Phenomena:
- Advertising and products
- Animation and comics
- Challenges
- Dance
- Film
- Gaming
- Images
- Music
- Politics
- Videos
- Other phenomena
Click on any of the following blue hyperlinks to learn more about Internet Phenomena:
How the Internet is Governed
YouTube Video: How It Works: Internet of Things
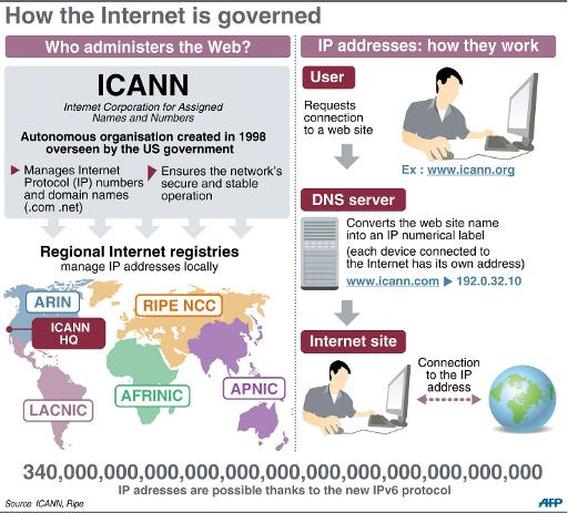
Internet governance is the development and application of shared principles, norms, rules, decision-making procedures, and programs that shape the evolution and use of the Internet.
This article describes how the Internet was and is currently governed, some of the controversies that occurred along the way, and the ongoing debates about how the Internet should or should not be governed in the future.
Internet governance should not be confused with E-Governance, which refers to governments' use of technology to carry out their governing duties.
Background:
No one person, company, organization or government runs the Internet. It is a globally distributed network comprising many voluntarily interconnected autonomous networks. It operates without a central governing body with each constituent network setting and enforcing its own policies.
The Internet's governance is conducted by a decentralized and international multi-stakeholder network of interconnected autonomous groups drawing from civil society, the private sector, governments, the academic and research communities and national and international organizations. They work cooperatively from their respective roles to create shared policies and standards that maintain the Internet's global interoperability for the public good.
However, to help ensure inter-operability, several key technical and policy aspects of the underlying core infrastructure and the principal namespaces are administered by the Internet Corporation for Assigned Names and Numbers (ICANN), which is headquartered in Los Angeles, California. ICANN oversees the assignment of globally unique identifiers on the Internet, including domain names, Internet protocol addresses, application port numbers in the transport protocols, and many other parameters. This seeks to create a globally unified namespace to ensure the global reach of the Internet.
ICANN is governed by an international board of directors drawn from across the Internet's technical, business, academic, and other non-commercial communities. However, the National Telecommunications and Information Administration, an agency of the U.S. Department of Commerce, continues to have final approval over changes to the DNS root zone. This authority over the root zone file makes ICANN one of a few bodies with global, centralized influence over the otherwise distributed Internet.
In the 30 September 2009 Affirmation of Commitments by the Department of Commerce and ICANN, the Department of Commerce finally affirmed that a "private coordinating process…is best able to flexibly meet the changing needs of the Internet and of Internet users" (para. 4).
While ICANN itself interpreted this as a declaration of its independence, scholars still point out that this is not yet the case. Considering that the U.S. Department of Commerce can unilaterally terminate the Affirmation of Commitments with ICANN, the authority of DNS administration is likewise seen as revocable and derived from a single State, namely the United States.
The technical underpinning and standardization of the Internet's core protocols (IPv4 and IPv6) is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise.
On 16 November 2005, the United Nations-sponsored World Summit on the Information Society (WSIS), held in Tunis, established the Internet Governance Forum (IGF) to open an ongoing, non-binding conversation among multiple stakeholders about the future of Internet governance. Since WSIS, the term "Internet governance" has been broadened beyond narrow technical concerns to include a wider range of Internet-related policy issues.
Definition of Internet Governance follows:
The definition of Internet governance has been contested by differing groups across political and ideological lines. One of the main debates concerns the authority and participation of certain actors, such as national governments, corporate entities and civil society, to play a role in the Internet's governance.
A working group established after a UN-initiated World Summit on the Information Society (WSIS) proposed the following definition of Internet governance as part of its June 2005 report: Internet governance is the development and application by Governments, the private sector and civil society, in their respective roles, of shared principles, norms, rules, decision-making procedures, and programs that shape the evolution and use of the Internet.
Law professor Yochai Benkler developed a conceptualization of Internet governance by the idea of three "layers" of governance:
Professors Jovan Kurbalija and Laura DeNardis also offer comprehensive definitions to "Internet Governance". According to Kurbalija, the broad approach to Internet Governance goes "beyond Internet infrastructural aspects and address other legal, economic, developmental, and sociocultural issues"; along similar lines, DeNardis argues that "Internet Governance generally refers to policy and technical coordination issues related to the exchange of information over the Internet".
One of the more policy-relevant questions today is exactly whether the regulatory responses are appropriate to police the content delivered through the Internet: it includes important rules for the improvement of Internet safety and for dealing with threats such as cyber-bullying, copyright infringement, data protection and other illegal or disruptive activities.
Click on any of the following blue hyperlinks for more about Internet Governance:
This article describes how the Internet was and is currently governed, some of the controversies that occurred along the way, and the ongoing debates about how the Internet should or should not be governed in the future.
Internet governance should not be confused with E-Governance, which refers to governments' use of technology to carry out their governing duties.
Background:
No one person, company, organization or government runs the Internet. It is a globally distributed network comprising many voluntarily interconnected autonomous networks. It operates without a central governing body with each constituent network setting and enforcing its own policies.
The Internet's governance is conducted by a decentralized and international multi-stakeholder network of interconnected autonomous groups drawing from civil society, the private sector, governments, the academic and research communities and national and international organizations. They work cooperatively from their respective roles to create shared policies and standards that maintain the Internet's global interoperability for the public good.
However, to help ensure inter-operability, several key technical and policy aspects of the underlying core infrastructure and the principal namespaces are administered by the Internet Corporation for Assigned Names and Numbers (ICANN), which is headquartered in Los Angeles, California. ICANN oversees the assignment of globally unique identifiers on the Internet, including domain names, Internet protocol addresses, application port numbers in the transport protocols, and many other parameters. This seeks to create a globally unified namespace to ensure the global reach of the Internet.
ICANN is governed by an international board of directors drawn from across the Internet's technical, business, academic, and other non-commercial communities. However, the National Telecommunications and Information Administration, an agency of the U.S. Department of Commerce, continues to have final approval over changes to the DNS root zone. This authority over the root zone file makes ICANN one of a few bodies with global, centralized influence over the otherwise distributed Internet.
In the 30 September 2009 Affirmation of Commitments by the Department of Commerce and ICANN, the Department of Commerce finally affirmed that a "private coordinating process…is best able to flexibly meet the changing needs of the Internet and of Internet users" (para. 4).
While ICANN itself interpreted this as a declaration of its independence, scholars still point out that this is not yet the case. Considering that the U.S. Department of Commerce can unilaterally terminate the Affirmation of Commitments with ICANN, the authority of DNS administration is likewise seen as revocable and derived from a single State, namely the United States.
The technical underpinning and standardization of the Internet's core protocols (IPv4 and IPv6) is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise.
On 16 November 2005, the United Nations-sponsored World Summit on the Information Society (WSIS), held in Tunis, established the Internet Governance Forum (IGF) to open an ongoing, non-binding conversation among multiple stakeholders about the future of Internet governance. Since WSIS, the term "Internet governance" has been broadened beyond narrow technical concerns to include a wider range of Internet-related policy issues.
Definition of Internet Governance follows:
The definition of Internet governance has been contested by differing groups across political and ideological lines. One of the main debates concerns the authority and participation of certain actors, such as national governments, corporate entities and civil society, to play a role in the Internet's governance.
A working group established after a UN-initiated World Summit on the Information Society (WSIS) proposed the following definition of Internet governance as part of its June 2005 report: Internet governance is the development and application by Governments, the private sector and civil society, in their respective roles, of shared principles, norms, rules, decision-making procedures, and programs that shape the evolution and use of the Internet.
Law professor Yochai Benkler developed a conceptualization of Internet governance by the idea of three "layers" of governance:
- Physical infrastructure layer (through which information travels)
- Code or logical layer (controls the infrastructure)
- Content layer (contains the information signaled through the network)
Professors Jovan Kurbalija and Laura DeNardis also offer comprehensive definitions to "Internet Governance". According to Kurbalija, the broad approach to Internet Governance goes "beyond Internet infrastructural aspects and address other legal, economic, developmental, and sociocultural issues"; along similar lines, DeNardis argues that "Internet Governance generally refers to policy and technical coordination issues related to the exchange of information over the Internet".
One of the more policy-relevant questions today is exactly whether the regulatory responses are appropriate to police the content delivered through the Internet: it includes important rules for the improvement of Internet safety and for dealing with threats such as cyber-bullying, copyright infringement, data protection and other illegal or disruptive activities.
Click on any of the following blue hyperlinks for more about Internet Governance:
Electronic governance (or E-governance)
YouTube Video 1: The eGovernment Revolution
YouTube Video 2: Jennifer Pahlka* (TED Talks**): "Coding a Better Government"
* -- Jennifer Pahlka
**-- TED Talks
Electronic governance or e-governance is the application of information and communication technology (ICT) for delivering the following:
Through e-governance, government services will be made available to citizens in a convenient, efficient and transparent manner. The three main target groups that can be distinguished in governance concepts are government, citizens and businesses/interest groups. In e-governance there are no distinct boundaries.
Generally four basic models are available:
Distinction from E-Government:
Both terms are treated to be the same; however, there is a difference between the two. "E-government" is the use of the ICTs in public administration – combined with organizational change and new skills – to improve public services and democratic processes and to strengthen support to public.
The problem in this definition to be congruence definition of e-governance is that there is no provision for governance of ICTs. As a matter of fact, the governance of ICTs requires most probably a substantial increase in regulation and policy-making capabilities, with all the expertise and opinion-shaping processes along the various social stakeholders of these concerns.
So, the perspective of the e-governance is "the use of the technologies that both help governing and have to be governed". The public–private partnership (PPP)-based e-governance projects are hugely successful in India.
Many countries are looking forward to a corruption-free government. E-government is one-way communication protocol whereas e-governance is two-way communication protocol.
The essence of e-governance is to reach the beneficiary and ensure that the services intended to reach the desired individual has been met with. There should be an auto-response to support the essence of e-governance, whereby the Government realizes the efficacy of its governance: E-governance is by the governed, for the governed and of the governed.
Establishing the identity of the end beneficiary is a challenge in all citizen-centric services. Statistical information published by governments and world bodies does not always reveal the facts.
The best form of e-governance cuts down on unwanted interference of too many layers while delivering governmental services. It depends on good infrastructural setup with the support of local processes and parameters for governments to reach their citizens or end beneficiaries. Budget for planning, development and growth can be derived from well laid out e-governance systems.
Government to Citizen:
The goal of government-to-customer (G2C) e-governance is to offer a variety of ICT services to citizens in an efficient and economical manner, and to strengthen the relationship between government and citizens using technology.
There are several methods of government-to-customer e-governance. Two-way communication allows citizens to instant message directly with public administrators, and cast remote electronic votes (electronic voting) and instant opinion voting. Transactions such as payment of services, such as city utilities, can be completed online or over the phone.
Mundane services such as name or address changes, applying for services or grants, or transferring existing services are more convenient and no longer have to be completed face to face.
The Federal Government of the United States has a broad framework of G2C technology to enhance citizen access to Government information and services. Benefits.Gov is an official US government website that informs citizens of benefits they are eligible for and provides information of how to apply assistance.
US State Governments also engage in G2C interaction through the following:
As with e-Governance on the global level, G2C services vary from state to state.
The Digital States Survey ranks states on social measures, digital democracy, e-commerce, taxation, and revenue. The 2012 report shows Michigan and Utah in the lead and Florida and Idaho with the lowest scores.
Municipal governments in the United States also use government-to-customer technology to complete transactions and inform the public.
Much like states, cities are awarded for innovative technology. Government Technology's "Best of the Web 2012" named Louissville, KY, Arvada, CO, Raleigh, NC, Riverside, CA, and Austin, TX the top five G2C city portals.
Click on any of the following blue hyperlinks more further amplification on E-Governance:
- government services,
- exchange of information,
- communication transactions,
- integration of various stand-alone systems and services between government-to-customer (G2C),
- government-to-business (G2B),
- government-to-government (G2G)
- as well as back office processes and interactions within the entire government framework.
Through e-governance, government services will be made available to citizens in a convenient, efficient and transparent manner. The three main target groups that can be distinguished in governance concepts are government, citizens and businesses/interest groups. In e-governance there are no distinct boundaries.
Generally four basic models are available:
- government-to-citizen (customer),
- government-to-employees,
- government-to-government
- and government-to-business.
Distinction from E-Government:
Both terms are treated to be the same; however, there is a difference between the two. "E-government" is the use of the ICTs in public administration – combined with organizational change and new skills – to improve public services and democratic processes and to strengthen support to public.
The problem in this definition to be congruence definition of e-governance is that there is no provision for governance of ICTs. As a matter of fact, the governance of ICTs requires most probably a substantial increase in regulation and policy-making capabilities, with all the expertise and opinion-shaping processes along the various social stakeholders of these concerns.
So, the perspective of the e-governance is "the use of the technologies that both help governing and have to be governed". The public–private partnership (PPP)-based e-governance projects are hugely successful in India.
Many countries are looking forward to a corruption-free government. E-government is one-way communication protocol whereas e-governance is two-way communication protocol.
The essence of e-governance is to reach the beneficiary and ensure that the services intended to reach the desired individual has been met with. There should be an auto-response to support the essence of e-governance, whereby the Government realizes the efficacy of its governance: E-governance is by the governed, for the governed and of the governed.
Establishing the identity of the end beneficiary is a challenge in all citizen-centric services. Statistical information published by governments and world bodies does not always reveal the facts.
The best form of e-governance cuts down on unwanted interference of too many layers while delivering governmental services. It depends on good infrastructural setup with the support of local processes and parameters for governments to reach their citizens or end beneficiaries. Budget for planning, development and growth can be derived from well laid out e-governance systems.
Government to Citizen:
The goal of government-to-customer (G2C) e-governance is to offer a variety of ICT services to citizens in an efficient and economical manner, and to strengthen the relationship between government and citizens using technology.
There are several methods of government-to-customer e-governance. Two-way communication allows citizens to instant message directly with public administrators, and cast remote electronic votes (electronic voting) and instant opinion voting. Transactions such as payment of services, such as city utilities, can be completed online or over the phone.
Mundane services such as name or address changes, applying for services or grants, or transferring existing services are more convenient and no longer have to be completed face to face.
The Federal Government of the United States has a broad framework of G2C technology to enhance citizen access to Government information and services. Benefits.Gov is an official US government website that informs citizens of benefits they are eligible for and provides information of how to apply assistance.
US State Governments also engage in G2C interaction through the following:
- Department of Transportation,
- Department of Public Safety,
- United States Department of Health and Human Services,
- United States Department of Education,
- and others.
As with e-Governance on the global level, G2C services vary from state to state.
The Digital States Survey ranks states on social measures, digital democracy, e-commerce, taxation, and revenue. The 2012 report shows Michigan and Utah in the lead and Florida and Idaho with the lowest scores.
Municipal governments in the United States also use government-to-customer technology to complete transactions and inform the public.
Much like states, cities are awarded for innovative technology. Government Technology's "Best of the Web 2012" named Louissville, KY, Arvada, CO, Raleigh, NC, Riverside, CA, and Austin, TX the top five G2C city portals.
Click on any of the following blue hyperlinks more further amplification on E-Governance:
- Concerns
- Government to employees
- Government to government
- Government to business
- Challenges – international position
- See also:
Internet Pioneers as recognized by: The Internet Hall of Fame, (as governed by the Internet Society), along with a List of Internet Pioneers; and The Webby Awards
YouTube Video: Tim Berners-Lee (TED 2009*) and "The Next Web"
* -- TED 2009.
Pictured: LEFT: Internet Pioneers Vint Cerf and Robert Kahn (both considered as “Fathers of the Internet”) being awarded the Presidential Medal Of Freedom by President George W. Bush; RIGHT: Tim Berners-Lee is recognized as the inventor of the World Wide Web

The Internet Society (ISOC) is an American, non-profit organization founded in 1992 to provide leadership in Internet-related standards, education, access, and policy. It states that its mission is "to promote the open development, evolution and use of the Internet for the benefit of all people throughout the world".
The Internet Society has its headquarters in Reston, Virginia, United States, (near Washington, D.C.), and offices in Geneva, Switzerland. It has a membership base of more than 140 organizations and more than 80,000 individual members. Members also form "chapters" based on either common geographical location or special interests. There are over 110 chapters around the world.
The Internet Hall of Fame is an honorary lifetime achievement award administered by the Internet Society (ISOC) in recognition of individuals who have made significant contributions to the development and advancement of the Internet.
Click here for a List of Internet Pioneers.
___________________________________________________________________________
A Webby Award is an award for excellence on the Internet presented annually by The International Academy of Digital Arts and Sciences, a judging body composed of over one thousand industry experts and technology innovators.
Categories include websites; advertising and media; online film and video; mobile sites and apps; and social.
Two winners are selected in each category, one by members of The International Academy of Digital Arts and Sciences, and one by the public who cast their votes during Webby People’s Voice voting. Each winner presents a five-word acceptance speech, a trademark of the annual awards show.
Hailed as the "Internet’s highest honor," the award is one of the older Internet-oriented awards, and is associated with the phrase "The Oscars of the Internet."
Click here for a List of Webby Award Winners.
The Internet Society has its headquarters in Reston, Virginia, United States, (near Washington, D.C.), and offices in Geneva, Switzerland. It has a membership base of more than 140 organizations and more than 80,000 individual members. Members also form "chapters" based on either common geographical location or special interests. There are over 110 chapters around the world.
The Internet Hall of Fame is an honorary lifetime achievement award administered by the Internet Society (ISOC) in recognition of individuals who have made significant contributions to the development and advancement of the Internet.
Click here for a List of Internet Pioneers.
___________________________________________________________________________
A Webby Award is an award for excellence on the Internet presented annually by The International Academy of Digital Arts and Sciences, a judging body composed of over one thousand industry experts and technology innovators.
Categories include websites; advertising and media; online film and video; mobile sites and apps; and social.
Two winners are selected in each category, one by members of The International Academy of Digital Arts and Sciences, and one by the public who cast their votes during Webby People’s Voice voting. Each winner presents a five-word acceptance speech, a trademark of the annual awards show.
Hailed as the "Internet’s highest honor," the award is one of the older Internet-oriented awards, and is associated with the phrase "The Oscars of the Internet."
Click here for a List of Webby Award Winners.
Internet censorship in the United States
YouTube Video: How Internet Censorshop Works*
* -- Berkman Klein Center
Picture: America's internet is incredibly free compared to most countries
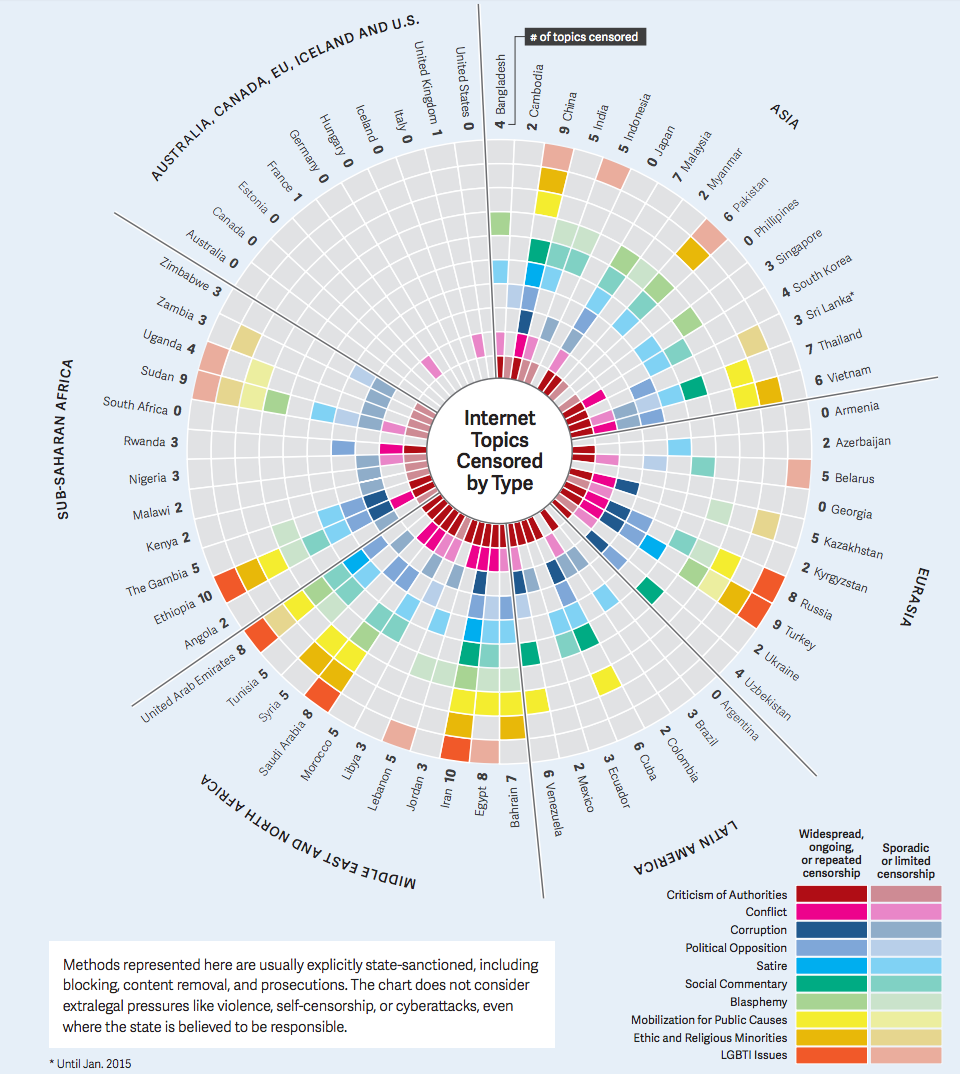
Internet censorship in the United States is the suppression of information published or viewed on the Internet in the United States. The U.S. possesses protection of freedom of speech and expression against federal, state, and local government censorship; a right protected by the First Amendment of the United States Constitution.
These protections extend to the Internet, however, the U.S. government has censored sites in the past and they are increasing in number to this day.However, in 2014, the United States was added to Reporters Without Borders (RWB)'s list of "Enemies of the Internet", a group of countries with the highest level of Internet censorship and surveillance.
RWB stated that the U.S. "… has undermined confidence in the Internet and its own standards of security" and that "U.S. surveillance practices and decryption activities are a direct threat to investigative journalists, especially those who work with sensitive sources for whom confidentiality is paramount and who are already under pressure."
In Freedom House's "Freedom of the Net" report from 2016, the United States was rated as the 4th most free internet on FreedomHouse's "65 Country Score Comparison".
Click on any of the following blue hyperlinks for more about Internet Censorship in the United States:
These protections extend to the Internet, however, the U.S. government has censored sites in the past and they are increasing in number to this day.However, in 2014, the United States was added to Reporters Without Borders (RWB)'s list of "Enemies of the Internet", a group of countries with the highest level of Internet censorship and surveillance.
RWB stated that the U.S. "… has undermined confidence in the Internet and its own standards of security" and that "U.S. surveillance practices and decryption activities are a direct threat to investigative journalists, especially those who work with sensitive sources for whom confidentiality is paramount and who are already under pressure."
In Freedom House's "Freedom of the Net" report from 2016, the United States was rated as the 4th most free internet on FreedomHouse's "65 Country Score Comparison".
Click on any of the following blue hyperlinks for more about Internet Censorship in the United States:
- Overview
- Federal laws
- Proposed federal legislation that has not become law
- Censorship by institutions
- See also:
- Internet censorship and surveillance by country
- Communications Assistance for Law Enforcement Act (CALEA)
- Mass surveillance in the United States
- Global Integrity: Internet Censorship, A Comparative Study; puts US online censorship in cross-country context.
Net Neutrality: Google and Facebook Join Net Neutrality Day to Protest FCC’s Proposed Rollback (by NBC News July 12, 2017)
Click on NBC Video: "FCC Chairman Announces Push to Target Net Neutrality Rules"
Picture Courtesy of Geneva Internet Platform

Net neutrality is the principle that Internet service providers and governments regulating the Internet should treat all data on the Internet the same, not discriminating or charging differentially by user, content, website, platform, application, type of attached equipment, or mode of communication.
The term was coined by Columbia University media law professor Tim Wu in 2003, as an extension of the longstanding concept of a common carrier, which was used to describe the role of telephone systems.
A widely-cited example of a violation of net neutrality principles was when the Internet service provider Comcast was secretly slowing (a.k.a. "throttling") uploads from peer-to-peer file sharing (P2P) applications by using forged packets. Comcast didn't stop blocking these protocols like BitTorrent until the FCC ordered them to do so.
In 2004, The Madison River Communications company was fined $15,000 by the FCC for restricting their customer’s access to Vonage which was rivaling their own services. AT&T was also caught limiting access to FaceTime, so only those users who paid for the new shared data plans could access the application.
In April 2017, an attempt to compromise net neutrality in the United States is being considered by the newly appointed FCC chairman, Ajit Varadaraj Pai. On May 16, 2017, a process began to roll back Open Internet rules, in place since 2015. This rule-making process includes a public comment period that lasts sixty days: thirty days for public comment and thirty days for the FCC to respond.
Research suggests that a combination of policy instruments will help realize the range of valued political and economic objectives central to the network neutrality debate. Combined with strong public opinion, this has led some governments to regulate broadband Internet services as a public utility, similar to the way electricity, gas and water supply is regulated, along with limiting providers and regulating the options those providers can offer.
NBC News July 12, 2017 Article: by Ben Popken
Tech companies are banding together to make a final push to stop a fait accompli.
Google, Facebook, Netflix, Twitter, and 80,000 other top websites and organizations have joined together for a "Day of Action" to protest a retreat from the concept of "net neutrality." They are angry that the Trump administration wants to roll back regulations requiring internet service providers to treat all data and customers equally online, and the companies are encouraging consumers to give their feedback on the Federal Communications Commission's website.
Banners, pop-ups, push notifications and videos will be seen across participating websites, urging visitors to tell the FCC what they think. Don't be surprised if you see your friends changing their social media avatars or profile pictures, too.
Google declined to share specifics about its involvement, but users searching "what is net neutrality" or "net neutrality day of action" will get a call-out box with information at the top of their results.
A discreet text banner on the top of Netflix.com directed users to a call-to-action page created by the Internet Association, an industry trade group.
Smaller websites published stories featured on their front page, or added an extra pop-up when users tried to submit standard comments.
"In true internet fashion, every site is participating in its own way," Evan Greer, campaign director of Fight for the Future, told NBC News. "Most are using our widgets that allow visitors to easily submit comments to the FCC and Congress without ever leaving the page that they're on. Many are getting creative and writing their own code or displaying their own banners in support of net neutrality that point to action tools."
What's It All About?The critical issue is whether the internet be an all-you-can-eat buffet of information, videos, and LOLCAT memes; or an à la carte menu. Should internet providers be allowed to strike deals to deliver some kinds of content, such as their own or those partners have paid them for, at a faster speed? Should the internet be more like cable, where you subscribe to a package of sports, entertainment, and news websites?
"No," said millions of consumers the last time the FCC took public comment. Over 4 million consumers lodged their comments.
Internet service providers and cable companies argue that Obama-era regulations enacted in 2015 intended to protect net neutrality are the wrong approach, and that a "light touch" is preferred.
"The internet has succeeded up until this point because it has been free to grow, innovate, and change largely free from government oversight," wrote the NCTA, the Internet & Television Association, the primary broadband and cable industry trade group, in its statement on net neutrality.
It proposes scrapping the regulations, which treat broadband like a "common carrier," required to transport "passengers" of data at the same rate, with a different set of rules. The NCTA said its proposal "empowers the internet industry to continue to innovate without putting handcuffs on its most pioneering companies."
A poll from Morning Consult and the NCTA found that 61 percent of consumers either strongly or somewhat support net neutrality rules.
The view of President Donald J. Trump's appointed FCC chair Ajit Pai is in line with that of the ISPs. He vowed earlier this year to roll back the new rules in order to protect consumers.
“It’s basic economics. The more heavily you regulate something, the less of it you’re likely to get,” he said in a speech at the Newseum in Washington in April.
FCC spokesman Mark Wigfield declined a NBC News request for comment on today's planned action.
As part of the day of protest, Silicon Valley companies and website operators are raising concerns over the rule change, fearful it will favor Goliaths over Davids.
With the FCC chair in favor of revising the rules, committee votes on his side, a thumbs-up from President Donald Trump, and a Republican-controlled Congress, today's actions aren't likely to sway the commission.
Instead the number of consumer comments flooding the FCC today will become a data point used by net neutrality proponents if the rule changes end up in court, as activists have vowed.
"Consumers hate buffering and slow-loading and will abandon videos and services if they're not getting a good viewing experience," said Michael Chea, general counsel for Vimeo, a video-sharing site favored by independent artists.
"[Companies] can throttle some websites over others, favor their own content," said Chea. "This is another thing that will reduce choice, increase costs, and reduce innovation."
Click on any of the following blue hyperlinks for more about Net Neutrality:
The term was coined by Columbia University media law professor Tim Wu in 2003, as an extension of the longstanding concept of a common carrier, which was used to describe the role of telephone systems.
A widely-cited example of a violation of net neutrality principles was when the Internet service provider Comcast was secretly slowing (a.k.a. "throttling") uploads from peer-to-peer file sharing (P2P) applications by using forged packets. Comcast didn't stop blocking these protocols like BitTorrent until the FCC ordered them to do so.
In 2004, The Madison River Communications company was fined $15,000 by the FCC for restricting their customer’s access to Vonage which was rivaling their own services. AT&T was also caught limiting access to FaceTime, so only those users who paid for the new shared data plans could access the application.
In April 2017, an attempt to compromise net neutrality in the United States is being considered by the newly appointed FCC chairman, Ajit Varadaraj Pai. On May 16, 2017, a process began to roll back Open Internet rules, in place since 2015. This rule-making process includes a public comment period that lasts sixty days: thirty days for public comment and thirty days for the FCC to respond.
Research suggests that a combination of policy instruments will help realize the range of valued political and economic objectives central to the network neutrality debate. Combined with strong public opinion, this has led some governments to regulate broadband Internet services as a public utility, similar to the way electricity, gas and water supply is regulated, along with limiting providers and regulating the options those providers can offer.
NBC News July 12, 2017 Article: by Ben Popken
Tech companies are banding together to make a final push to stop a fait accompli.
Google, Facebook, Netflix, Twitter, and 80,000 other top websites and organizations have joined together for a "Day of Action" to protest a retreat from the concept of "net neutrality." They are angry that the Trump administration wants to roll back regulations requiring internet service providers to treat all data and customers equally online, and the companies are encouraging consumers to give their feedback on the Federal Communications Commission's website.
Banners, pop-ups, push notifications and videos will be seen across participating websites, urging visitors to tell the FCC what they think. Don't be surprised if you see your friends changing their social media avatars or profile pictures, too.
Google declined to share specifics about its involvement, but users searching "what is net neutrality" or "net neutrality day of action" will get a call-out box with information at the top of their results.
A discreet text banner on the top of Netflix.com directed users to a call-to-action page created by the Internet Association, an industry trade group.
Smaller websites published stories featured on their front page, or added an extra pop-up when users tried to submit standard comments.
"In true internet fashion, every site is participating in its own way," Evan Greer, campaign director of Fight for the Future, told NBC News. "Most are using our widgets that allow visitors to easily submit comments to the FCC and Congress without ever leaving the page that they're on. Many are getting creative and writing their own code or displaying their own banners in support of net neutrality that point to action tools."
What's It All About?The critical issue is whether the internet be an all-you-can-eat buffet of information, videos, and LOLCAT memes; or an à la carte menu. Should internet providers be allowed to strike deals to deliver some kinds of content, such as their own or those partners have paid them for, at a faster speed? Should the internet be more like cable, where you subscribe to a package of sports, entertainment, and news websites?
"No," said millions of consumers the last time the FCC took public comment. Over 4 million consumers lodged their comments.
Internet service providers and cable companies argue that Obama-era regulations enacted in 2015 intended to protect net neutrality are the wrong approach, and that a "light touch" is preferred.
"The internet has succeeded up until this point because it has been free to grow, innovate, and change largely free from government oversight," wrote the NCTA, the Internet & Television Association, the primary broadband and cable industry trade group, in its statement on net neutrality.
It proposes scrapping the regulations, which treat broadband like a "common carrier," required to transport "passengers" of data at the same rate, with a different set of rules. The NCTA said its proposal "empowers the internet industry to continue to innovate without putting handcuffs on its most pioneering companies."
A poll from Morning Consult and the NCTA found that 61 percent of consumers either strongly or somewhat support net neutrality rules.
The view of President Donald J. Trump's appointed FCC chair Ajit Pai is in line with that of the ISPs. He vowed earlier this year to roll back the new rules in order to protect consumers.
“It’s basic economics. The more heavily you regulate something, the less of it you’re likely to get,” he said in a speech at the Newseum in Washington in April.
FCC spokesman Mark Wigfield declined a NBC News request for comment on today's planned action.
As part of the day of protest, Silicon Valley companies and website operators are raising concerns over the rule change, fearful it will favor Goliaths over Davids.
With the FCC chair in favor of revising the rules, committee votes on his side, a thumbs-up from President Donald Trump, and a Republican-controlled Congress, today's actions aren't likely to sway the commission.
Instead the number of consumer comments flooding the FCC today will become a data point used by net neutrality proponents if the rule changes end up in court, as activists have vowed.
"Consumers hate buffering and slow-loading and will abandon videos and services if they're not getting a good viewing experience," said Michael Chea, general counsel for Vimeo, a video-sharing site favored by independent artists.
"[Companies] can throttle some websites over others, favor their own content," said Chea. "This is another thing that will reduce choice, increase costs, and reduce innovation."
Click on any of the following blue hyperlinks for more about Net Neutrality:
- Definition and related principles
- By issue
- Legal aspects
- By country: United States
- Arguments in favor
- Arguments against
- Related issues
- Concentration of media ownership
- Digital rights
- Economic rent
- Industrial information economy
- Killswitch (film)
- Municipal broadband
- Search neutrality
- Switzerland (software)
- Wikipedia Zero
- Day of Action to Save Net Neutrality
- Technological Neutrality and Conceptual Singularity
- Why Consumers Should Be Worried About Net Neutrality
- The FCC on Net Neutrality: Be Careful What You Wish For
- Financial backers of pro neutrality groups
- Killerswitch - film advocating in favor of Net Neutrality
- Battle for the Net - website advocating net neutrality by Fight for the Future
- Don't Break The Net - website advocating against net neutrality by TechFreedom with monetary support from telcos (see answer to corresponding question on website's "About TechFreedom" section)
- La Quadrature du Net – complex dossier and links about net neutrality
- Net Neutrality – What it is and why you should care. – comic explaining net neutrality.
- Check Your Internet
Virtual Private Network including a List of United States mobile virtual network operators
YouTube Video: How a VPN Works and What It Does for You
Pictured: VPN connectivity overview
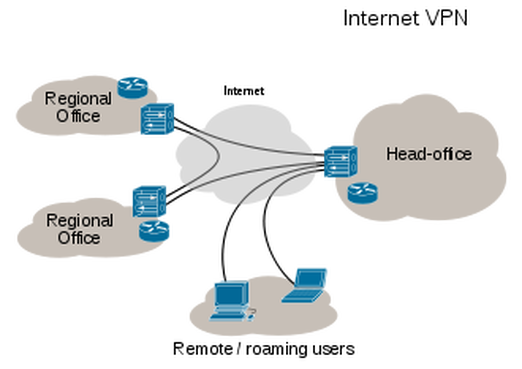
Click here for a List of United States mobile virtual network operators.
A virtual private network (VPN) extends a private network across a public network, and enables users to send and receive data across shared or public networks as if their computing devices were directly connected to the private network. ("In the simplest terms, it creates a secure, encrypted connection, which can be thought of as a tunnel, between your computer and a server operated by the VPN service.")
Applications running across the VPN may therefore benefit from the functionality, security, and management of the private network.
VPNs may allow employees to securely access a corporate intranet while located outside the office. They are used to securely connect geographically separated offices of an organization, creating one cohesive network. Individual Internet users may secure their wireless transactions with a VPN, to circumvent geo-restrictions and censorship, or to connect to proxy servers for the purpose of protecting personal identity and location.
However, some Internet sites block access to known VPN technology to prevent the circumvention of their geo-restrictions.
A VPN is created by establishing a virtual point-to-point connection through the use of dedicated connections, virtual tunneling protocols, or traffic encryption. A VPN available from the public Internet can provide some of the benefits of a wide area network (WAN).
From a user perspective, the resources available within the private network can be accessed remotely.
Traditional VPNs are characterized by a point-to-point topology, and they do not tend to support or connect broadcast domains, so services such as Microsoft Windows NetBIOS may not be fully supported or work as they would on a local area network (LAN). Designers have developed VPN variants, such as Virtual Private LAN Service (VPLS), and layer-2 tunneling protocols, to overcome this limitation.
Early data networks allowed VPN-style remote connectivity through dial-up modem or through leased line connections utilizing Frame Relay and Asynchronous Transfer Mode (ATM) virtual circuits, provisioned through a network owned and operated by telecommunication carriers.
These networks are not considered true VPNs because they passively secure the data being transmitted by the creation of logical data streams. They have been replaced by VPNs based on IP and IP/Multi-protocol Label Switching (MPLS) Networks, due to significant cost-reductions and increased bandwidth provided by new technologies such as Digital Subscriber Line (DSL) and fiber-optic networks.
VPNs can be either remote-access (connecting a computer to a network) or site-to-site (connecting two networks). In a corporate setting, remote-access VPNs allow employees to access their company's intranet from home or while travelling outside the office, and site-to-site VPNs allow employees in geographically disparate offices to share one cohesive virtual network.
A VPN can also be used to interconnect two similar networks over a dissimilar middle network; for example, two IPv6 networks over an IPv4 network.
VPN systems may be classified by:
Click here for a List of the 20 Biggest Hacking Attacks of All Time (Courtesy of VPN Mentor)
Click on any of the following blue hyperlinks for more about Virtual Private Networks:
A virtual private network (VPN) extends a private network across a public network, and enables users to send and receive data across shared or public networks as if their computing devices were directly connected to the private network. ("In the simplest terms, it creates a secure, encrypted connection, which can be thought of as a tunnel, between your computer and a server operated by the VPN service.")
Applications running across the VPN may therefore benefit from the functionality, security, and management of the private network.
VPNs may allow employees to securely access a corporate intranet while located outside the office. They are used to securely connect geographically separated offices of an organization, creating one cohesive network. Individual Internet users may secure their wireless transactions with a VPN, to circumvent geo-restrictions and censorship, or to connect to proxy servers for the purpose of protecting personal identity and location.
However, some Internet sites block access to known VPN technology to prevent the circumvention of their geo-restrictions.
A VPN is created by establishing a virtual point-to-point connection through the use of dedicated connections, virtual tunneling protocols, or traffic encryption. A VPN available from the public Internet can provide some of the benefits of a wide area network (WAN).
From a user perspective, the resources available within the private network can be accessed remotely.
Traditional VPNs are characterized by a point-to-point topology, and they do not tend to support or connect broadcast domains, so services such as Microsoft Windows NetBIOS may not be fully supported or work as they would on a local area network (LAN). Designers have developed VPN variants, such as Virtual Private LAN Service (VPLS), and layer-2 tunneling protocols, to overcome this limitation.
Early data networks allowed VPN-style remote connectivity through dial-up modem or through leased line connections utilizing Frame Relay and Asynchronous Transfer Mode (ATM) virtual circuits, provisioned through a network owned and operated by telecommunication carriers.
These networks are not considered true VPNs because they passively secure the data being transmitted by the creation of logical data streams. They have been replaced by VPNs based on IP and IP/Multi-protocol Label Switching (MPLS) Networks, due to significant cost-reductions and increased bandwidth provided by new technologies such as Digital Subscriber Line (DSL) and fiber-optic networks.
VPNs can be either remote-access (connecting a computer to a network) or site-to-site (connecting two networks). In a corporate setting, remote-access VPNs allow employees to access their company's intranet from home or while travelling outside the office, and site-to-site VPNs allow employees in geographically disparate offices to share one cohesive virtual network.
A VPN can also be used to interconnect two similar networks over a dissimilar middle network; for example, two IPv6 networks over an IPv4 network.
VPN systems may be classified by:
- The protocols used to tunnel the traffic
- The tunnel's termination point location, e.g., on the customer edge or network-provider edge
- The type of topology of connections, such as site-to-site or network-to-network
- The levels of security provided
- The OSI layer they present to the connecting network, such as Layer 2 circuits or Layer 3 network connectivity
- The number of simultaneous connections
Click here for a List of the 20 Biggest Hacking Attacks of All Time (Courtesy of VPN Mentor)
Click on any of the following blue hyperlinks for more about Virtual Private Networks:
- Security mechanisms
- Routing
- User-visible PPVPN services
- Trusted delivery networks
- VPNs in mobile environments
- VPN on routers
- Networking limitations
- See also:
WatchMojo.com
YouTube Video: Top 10 WatchMojo Top 10s of 2013
Pictured: WatchMojo.com Logo courtesy of Wikipedia.
WatchMojo.com is a Canadian-based privately held video content producer, publisher, and syndicator. With over 7.9 billion all-time video views and 14 million subscribers (making it the 37th most-subscribed channel), WatchMojo has one of the largest channels on YouTube. 60% of its viewers and subscribers are male, whereas 40% are female, and 50% hail from English speaking countries.
WatchMojo.com was founded in June 2005 by Ashkan Karbasfrooshan, Raphael Daigneault, and Christine Voulieris. Other early key employees include Kevin Havill and Derek Allen.
The WatchMojo.com website was launched on 14 June 2005 and its YouTube channel was launched on 25 January 2007. WatchMojo is an independent channel, it is neither a Multi-Channel Network (MCN) nor part of one.
According to the CEO Karbasfrooshan, WatchMojo employed 23 full-time employees and a team of 100-plus freelance writers and video editors by October 2014. By March 2017, that number jumped to 50-plus.
The videos it produces are typically suggestions supplied by visitors of the site on its suggestion tool or its YouTube, Facebook, and Twitter pages. It hit 1 million subscribers on 30 October 2013 and then 5 million subscribers on 29 August 2014.
In December 2014, on the day its YouTube channel surpassed 6 million subscribers, it announced a representation deal with talent agency William Morris Endeavor. It surpassed 10 million subscribers on 5 December 2015.
During the 2016–17 regular season of the NHL, WatchMojo sponsored the NY Islanders.
In October 2016, Karbasfrooshan published The 10-Year Overnight Success: An Entrepreneurship’s Manifesto - How WatchMojo Built the Most Successful Media Brand on YouTube on the company's new publishing imprint, as it ventured into digital books and guides.
Content:
WatchMojo.com does not feature user-generated content nor does it allow a mechanism for users to upload videos onto its site. The website produces daily "Top Ten" videos as well as videos summarizing the history of specific niche topics.
These topics can be one of the following categories:
Each day it publishes over 5 videos for 60–75 minutes of original content. In February 2016, it launched the MsMojo channel to better serve female viewers and fans. It also launched multiple non-English channels for the Spanish, French, German, Turkish and Polish markets.
On April 15, 2017, WatchMojo debuted The Lineup, a game show that combined ranking top 10 lists with elements of fantasy draft and sports talk radio banter. It won a Telly Award for Best Series in the Web Series category.
On May 31, 2017, WatchMojo live-streamed its first ever live show, called WatchMojo Live At YouTube Space at Chelsea Market. The show consisted of an afternoon industry track covering online media, advertising, and VR. It was then followed by an evening show featuring DJ Killa Jewel, DJ Dan Deacon, Puddles Pity Party and Caveman.
On July 12, 2017, it followed up with WatchMojo Live at YouTube Space in London at King's Cross Station, featuring musical acts by Llew Eyre, Bluey Robinson and Leif Erikson. Speakers at the industry track included Hussain Manawer, Ben Jones and Kim Snow.
Business Model:
WatchMojo.com lost money the first six years of operations, broke even in 2012, and has generated a profit since 2013.
Due to the 2007–2009 recession, WatchMojo.com had de-emphasized an ad-supported model in favor of licensing fees paid by other media companies to access and use their media. Later that year Beet.TV featured WatchMojo.com alongside Magnify.net as examples of companies which successfully switched from ad-based revenue models to licensing fee based revenue models.
In 2012, it shifted its focus to YouTube and as a result of its growth in subscribers and views, it became profitable.
WatchMojo.com was founded in June 2005 by Ashkan Karbasfrooshan, Raphael Daigneault, and Christine Voulieris. Other early key employees include Kevin Havill and Derek Allen.
The WatchMojo.com website was launched on 14 June 2005 and its YouTube channel was launched on 25 January 2007. WatchMojo is an independent channel, it is neither a Multi-Channel Network (MCN) nor part of one.
According to the CEO Karbasfrooshan, WatchMojo employed 23 full-time employees and a team of 100-plus freelance writers and video editors by October 2014. By March 2017, that number jumped to 50-plus.
The videos it produces are typically suggestions supplied by visitors of the site on its suggestion tool or its YouTube, Facebook, and Twitter pages. It hit 1 million subscribers on 30 October 2013 and then 5 million subscribers on 29 August 2014.
In December 2014, on the day its YouTube channel surpassed 6 million subscribers, it announced a representation deal with talent agency William Morris Endeavor. It surpassed 10 million subscribers on 5 December 2015.
During the 2016–17 regular season of the NHL, WatchMojo sponsored the NY Islanders.
In October 2016, Karbasfrooshan published The 10-Year Overnight Success: An Entrepreneurship’s Manifesto - How WatchMojo Built the Most Successful Media Brand on YouTube on the company's new publishing imprint, as it ventured into digital books and guides.
Content:
WatchMojo.com does not feature user-generated content nor does it allow a mechanism for users to upload videos onto its site. The website produces daily "Top Ten" videos as well as videos summarizing the history of specific niche topics.
These topics can be one of the following categories:
- automotive,
- business,
- comedy,
- education,
- fashion,
- film,
- anime,
- Hentai,
- health and fitness,
- lifestyle,
- music,
- parenting,
- politics and economy,
- space and science,
- sports,
- technology,
- travel,
- and video games.
Each day it publishes over 5 videos for 60–75 minutes of original content. In February 2016, it launched the MsMojo channel to better serve female viewers and fans. It also launched multiple non-English channels for the Spanish, French, German, Turkish and Polish markets.
On April 15, 2017, WatchMojo debuted The Lineup, a game show that combined ranking top 10 lists with elements of fantasy draft and sports talk radio banter. It won a Telly Award for Best Series in the Web Series category.
On May 31, 2017, WatchMojo live-streamed its first ever live show, called WatchMojo Live At YouTube Space at Chelsea Market. The show consisted of an afternoon industry track covering online media, advertising, and VR. It was then followed by an evening show featuring DJ Killa Jewel, DJ Dan Deacon, Puddles Pity Party and Caveman.
On July 12, 2017, it followed up with WatchMojo Live at YouTube Space in London at King's Cross Station, featuring musical acts by Llew Eyre, Bluey Robinson and Leif Erikson. Speakers at the industry track included Hussain Manawer, Ben Jones and Kim Snow.
Business Model:
WatchMojo.com lost money the first six years of operations, broke even in 2012, and has generated a profit since 2013.
Due to the 2007–2009 recession, WatchMojo.com had de-emphasized an ad-supported model in favor of licensing fees paid by other media companies to access and use their media. Later that year Beet.TV featured WatchMojo.com alongside Magnify.net as examples of companies which successfully switched from ad-based revenue models to licensing fee based revenue models.
In 2012, it shifted its focus to YouTube and as a result of its growth in subscribers and views, it became profitable.
Rotten Tomatoes
Rotten Tomatoes Video of the Movie Trailer for "War for the Planet of the Apes"
Pictured: part of the home page for the RottenTomatoes Website as of 7-16-17
Rotten Tomatoes is an American review aggregator website for film and television. The company was launched in August 1998 by Senh Duong and since January 2010 has been owned by Flixster, which was, in turn, acquired in 2011 by Warner Bros.
In February 2016, Rotten Tomatoes and its parent site Flixster were sold to Comcast's Fandango. Warner Bros. retained a minority stake in the merged entities, including Fandango. Since 2007, the website's editor-in-chief has been Matt Atchity. The name, Rotten Tomatoes, derives from the practice of audiences' throwing rotten tomatoes when disapproving of a poor stage performance.
From early 2008 to September 2010, Current Television aired the weekly The Rotten Tomatoes Show, featuring hosts and material from the website. A shorter segment was incorporated into the weekly show, InfoMania, which ended in 2011. In September 2013, the website introduced "TV Zone", a section for reviewing scripted TV shows.
Rotten Tomatoes was launched on August 12, 1998, as a spare-time project by Senh Duong. His goal in creating Rotten Tomatoes was "to create a site where people can get access to reviews from a variety of critics in the U.S." As a fan of Jackie Chan's, Duong was inspired to create the website after collecting all the reviews of Chan's movies as they were being published in the United States.
The first movie whose reviews were featured on Rotten Tomatoes was Your Friends & Neighbors (1998). The website was an immediate success, receiving mentions by Netscape, Yahoo!, and USA Today within the first week of its launch; it attracted "600–1000 daily unique visitors" as a result.
Duong teamed up with University of California, Berkeley classmates Patrick Y. Lee and Stephen Wang, his former partners at the Berkeley, California–based web design firm Design Reactor, to pursue Rotten Tomatoes on a full-time basis. They officially launched it on April 1, 2000.
In June 2004, IGN Entertainment acquired rottentomatoes.com for an undisclosed sum. In September 2005, IGN was bought by News Corp's Fox Interactive Media.
In January 2010, IGN sold the website to Flixster. The combined reach of both companies is 30 million unique visitors a month across all different platforms, according to the companies.
In May 2011, Flixster was acquired by Warner Bros.
In early 2009, Current Television launched the televised version of the web review site, The Rotten Tomatoes Show. It was hosted by Brett Erlich and Ellen Fox and written by Mark Ganek. The show aired every Thursday at 10:30 EST on the Current TV network. The last episode aired on September 16, 2010. It returned as a much shorter segment of InfoMania, a satirical news show that ended in 2011.
By late 2009, the website was designed to enable Rotten Tomatoes users to create and join groups to discuss various aspects of film. One group, "The Golden Oyster Awards", accepted votes of members for various awards, spoofing the better-known Oscars or Golden Globes. When Flixster bought the company, they disbanded the groups, announcing: "The Groups area has been discontinued to pave the way for new community features coming soon. In the meantime, please use the Forums to continue your conversations about your favorite movie topics."
As of February 2011, new community features have been added and others removed. For example, users can no longer sort films by Fresh Ratings from Rotten Ratings, and vice versa. On September 17, 2013, a section devoted to scripted television series, called "TV Zone", was created as a subsection of the website.
In February 2016, Rotten Tomatoes and its parent site Flixster were sold to Comcast's Fandango. Warner Bros retained a minority stake in the merged entities, including Fandango.
Click on any of the following blue hyperlinks for more about the Rotten Tomatoes Website:
In February 2016, Rotten Tomatoes and its parent site Flixster were sold to Comcast's Fandango. Warner Bros. retained a minority stake in the merged entities, including Fandango. Since 2007, the website's editor-in-chief has been Matt Atchity. The name, Rotten Tomatoes, derives from the practice of audiences' throwing rotten tomatoes when disapproving of a poor stage performance.
From early 2008 to September 2010, Current Television aired the weekly The Rotten Tomatoes Show, featuring hosts and material from the website. A shorter segment was incorporated into the weekly show, InfoMania, which ended in 2011. In September 2013, the website introduced "TV Zone", a section for reviewing scripted TV shows.
Rotten Tomatoes was launched on August 12, 1998, as a spare-time project by Senh Duong. His goal in creating Rotten Tomatoes was "to create a site where people can get access to reviews from a variety of critics in the U.S." As a fan of Jackie Chan's, Duong was inspired to create the website after collecting all the reviews of Chan's movies as they were being published in the United States.
The first movie whose reviews were featured on Rotten Tomatoes was Your Friends & Neighbors (1998). The website was an immediate success, receiving mentions by Netscape, Yahoo!, and USA Today within the first week of its launch; it attracted "600–1000 daily unique visitors" as a result.
Duong teamed up with University of California, Berkeley classmates Patrick Y. Lee and Stephen Wang, his former partners at the Berkeley, California–based web design firm Design Reactor, to pursue Rotten Tomatoes on a full-time basis. They officially launched it on April 1, 2000.
In June 2004, IGN Entertainment acquired rottentomatoes.com for an undisclosed sum. In September 2005, IGN was bought by News Corp's Fox Interactive Media.
In January 2010, IGN sold the website to Flixster. The combined reach of both companies is 30 million unique visitors a month across all different platforms, according to the companies.
In May 2011, Flixster was acquired by Warner Bros.
In early 2009, Current Television launched the televised version of the web review site, The Rotten Tomatoes Show. It was hosted by Brett Erlich and Ellen Fox and written by Mark Ganek. The show aired every Thursday at 10:30 EST on the Current TV network. The last episode aired on September 16, 2010. It returned as a much shorter segment of InfoMania, a satirical news show that ended in 2011.
By late 2009, the website was designed to enable Rotten Tomatoes users to create and join groups to discuss various aspects of film. One group, "The Golden Oyster Awards", accepted votes of members for various awards, spoofing the better-known Oscars or Golden Globes. When Flixster bought the company, they disbanded the groups, announcing: "The Groups area has been discontinued to pave the way for new community features coming soon. In the meantime, please use the Forums to continue your conversations about your favorite movie topics."
As of February 2011, new community features have been added and others removed. For example, users can no longer sort films by Fresh Ratings from Rotten Ratings, and vice versa. On September 17, 2013, a section devoted to scripted television series, called "TV Zone", was created as a subsection of the website.
In February 2016, Rotten Tomatoes and its parent site Flixster were sold to Comcast's Fandango. Warner Bros retained a minority stake in the merged entities, including Fandango.
Click on any of the following blue hyperlinks for more about the Rotten Tomatoes Website:
- Website
- Hollywood reaction
- Criticism
- See also:
Metacritic
YouTube Video: Bombshell for PC Review (click on movie trailer)
Pictured: Part of the home page for the Metacritic Website as of 7-16-17
Metacritic is a website that aggregates reviews of media products: music albums, video games, films, TV shows, and formerly, books. For each product, the scores from each review are averaged (a weighted average).
Metacritic was created by Jason Dietz, Marc Doyle, and Julie Doyle Roberts in 1999. The site provides an excerpt from each review and hyperlinks to its source. A color of Green, Yellow or Red summarizes the critics' recommendations. It has been described as the video game industry's "premier" review aggregator.
Metacritic's scoring converts each review into a percentage, either mathematically from the mark given, or which the site decides subjectively from a qualitative review. Before being averaged, the scores are weighted according to the critic's fame, stature, and volume of reviews.
Metacritic was launched in July 1999 by Marc Doyle, his sister Julie Doyle Roberts, and a classmate from the University of Southern California law school, Jason Dietz. Rotten Tomatoes was already compiling movie reviews, but Doyle, Roberts, and Dietz saw an opportunity to cover a broader range of media. They sold Metacritic to CNET in 2005.
CNET and Metacritic are now owned by the CBS Corporation.
Nick Wingfield of The Wall Street Journal wrote in September 2004: "Mr. Doyle, 36, is now a senior product manager at CNET but he also acts as games editor of Metacritic".
Speaking of video games, Doyle said: "A site like ours helps people cut through...unobjective promotional language". "By giving consumers, and web users specifically, early information on the objective quality of a game, not only are they more educated about their choices, but it forces publishers to demand more from their developers, license owners to demand more from their licensees, and eventually, hopefully, the games get better".
He added that the review process was not taken as seriously when unconnected magazines and websites provided reviews in isolation.
In August 2010, the website's appearance was revamped; reaction from users was overwhelmingly negative
Click on any of the following blue hyperlinks for more about Metacritic:
Metacritic was created by Jason Dietz, Marc Doyle, and Julie Doyle Roberts in 1999. The site provides an excerpt from each review and hyperlinks to its source. A color of Green, Yellow or Red summarizes the critics' recommendations. It has been described as the video game industry's "premier" review aggregator.
Metacritic's scoring converts each review into a percentage, either mathematically from the mark given, or which the site decides subjectively from a qualitative review. Before being averaged, the scores are weighted according to the critic's fame, stature, and volume of reviews.
Metacritic was launched in July 1999 by Marc Doyle, his sister Julie Doyle Roberts, and a classmate from the University of Southern California law school, Jason Dietz. Rotten Tomatoes was already compiling movie reviews, but Doyle, Roberts, and Dietz saw an opportunity to cover a broader range of media. They sold Metacritic to CNET in 2005.
CNET and Metacritic are now owned by the CBS Corporation.
Nick Wingfield of The Wall Street Journal wrote in September 2004: "Mr. Doyle, 36, is now a senior product manager at CNET but he also acts as games editor of Metacritic".
Speaking of video games, Doyle said: "A site like ours helps people cut through...unobjective promotional language". "By giving consumers, and web users specifically, early information on the objective quality of a game, not only are they more educated about their choices, but it forces publishers to demand more from their developers, license owners to demand more from their licensees, and eventually, hopefully, the games get better".
He added that the review process was not taken as seriously when unconnected magazines and websites provided reviews in isolation.
In August 2010, the website's appearance was revamped; reaction from users was overwhelmingly negative
Click on any of the following blue hyperlinks for more about Metacritic:
Cybernetics
YouTube Video: What is Cybernetics?
Pictured: ASIMO uses sensors and sophisticated algorithms to avoid obstacles and navigate stairs.

Cybernetics is a transdisciplinary approach for exploring regulatory systems, their structures, constraints, and possibilities. In the 21st century, the term is often used in a rather loose way to imply "control of any system using technology;" this has blunted its meaning to such an extent that many writers avoid using it.
Cybernetics is relevant to the study of systems, such as mechanical, physical, biological, cognitive, and social systems. Cybernetics is applicable when a system being analyzed incorporates a closed signaling loop; that is, where action by the system generates some change in its environment and that change is reflected in that system in some manner (feedback) that triggers a system change, originally referred to as a "circular causal" relationship.
System dynamics, a related field, originated with applications of electrical engineering control theory to other kinds of simulation models (especially business systems) by Jay Forrester at MIT in the 1950s.
Concepts studied by cyberneticists include, but are not limited to:
These concepts are studied by other subjects such as engineering and biology, but in cybernetics these are abstracted from the context of the individual organism or device.
Norbert Wiener defined cybernetics in 1948 as "the scientific study of control and communication in the animal and the machine." The word cybernetics comes from Greek κυβερνητική (kybernetike), meaning "governance", i.e., all that are pertinent to κυβερνάω (kybernao), the latter meaning "to steer, navigate or govern", hence κυβέρνησις (kybernesis), meaning "government", is the government while κυβερνήτης (kybernetes) is the governor or the captain.
Contemporary cybernetics began as an interdisciplinary study connecting the fields of control systems, electrical network theory, mechanical engineering, logic modeling, evolutionary biology, neuroscience, anthropology, and psychology in the 1940s, often attributed to the Macy Conferences.
During the second half of the 20th century cybernetics evolved in ways that distinguish first-order cybernetics (about observed systems) from second-order cybernetics (about observing systems).
More recently there is talk about a third-order cybernetics (doing in ways that embraces first and second-order).
Fields of study which have influenced or been influenced by cybernetics include,
Click on any of the following blue hyperlinks for further amplification:
Cybernetics is relevant to the study of systems, such as mechanical, physical, biological, cognitive, and social systems. Cybernetics is applicable when a system being analyzed incorporates a closed signaling loop; that is, where action by the system generates some change in its environment and that change is reflected in that system in some manner (feedback) that triggers a system change, originally referred to as a "circular causal" relationship.
System dynamics, a related field, originated with applications of electrical engineering control theory to other kinds of simulation models (especially business systems) by Jay Forrester at MIT in the 1950s.
Concepts studied by cyberneticists include, but are not limited to:
- learning,
- cognition,
- adaptation,
- social control,
- emergence,
- communication,
- efficiency,
- efficacy,
- and connectivity.
These concepts are studied by other subjects such as engineering and biology, but in cybernetics these are abstracted from the context of the individual organism or device.
Norbert Wiener defined cybernetics in 1948 as "the scientific study of control and communication in the animal and the machine." The word cybernetics comes from Greek κυβερνητική (kybernetike), meaning "governance", i.e., all that are pertinent to κυβερνάω (kybernao), the latter meaning "to steer, navigate or govern", hence κυβέρνησις (kybernesis), meaning "government", is the government while κυβερνήτης (kybernetes) is the governor or the captain.
Contemporary cybernetics began as an interdisciplinary study connecting the fields of control systems, electrical network theory, mechanical engineering, logic modeling, evolutionary biology, neuroscience, anthropology, and psychology in the 1940s, often attributed to the Macy Conferences.
During the second half of the 20th century cybernetics evolved in ways that distinguish first-order cybernetics (about observed systems) from second-order cybernetics (about observing systems).
More recently there is talk about a third-order cybernetics (doing in ways that embraces first and second-order).
Fields of study which have influenced or been influenced by cybernetics include,
- game theory,
- system theory (a mathematical counterpart to cybernetics),
- perceptual control theory,
- sociology,
- psychology (especially neuropsychology, behavioral psychology, cognitive psychology),
- philosophy,
- architecture,
- and organizational theory.
Click on any of the following blue hyperlinks for further amplification:
- Definitions
- Etymology
- History:
- Subdivisions of the field:
- Related fields:
- See also:
- Artificial life
- Automation
- Autonomous Agency Theory
- Brain–computer interface
- Chaos theory
- Connectionism
- Decision theory
- Gaia hypothesis
- Industrial ecology
- Intelligence amplification
- Management science
- Principia Cybernetica
- Semiotics
- Superorganisms
- Synergetics (Haken)
- Variety (cybernetics)
- Viable System Theory
- Viable systems approach
Video on Demand including websites that offer VoD
YouTube Video: What is VIDEO ON DEMAND? What does VIDEO ON DEMAND mean?
Video on demand (display) (VOD) are systems which allow users to select and watch/listen to video or audio content such as movies and TV shows when they choose to, rather than having to watch at a specific broadcast time, which was the prevalent approach with over-the-air broadcasting during much of the 20th century. IPTV technology is often used to bring video on demand to televisions and personal computers.
Television VOD systems can either "stream" content through a set-top box, a computer or other device, allowing viewing in real time, or download it to a device such as a computer, digital video recorder (also called a personal video recorder) or portable media player for viewing at any time.
The majority of cable- and telephone company-based television providers offer both VOD streaming, including pay-per-view and free content, whereby a user buys or selects a movie or television program and it begins to play on the television set almost instantaneously, or downloading to a digital video recorder (DVR) rented or purchased from the provider, or downloaded onto a PC or to a portable device, for viewing in the future.
Internet television, using the Internet, is an increasingly popular form of video on demand. VOD can also be accessed via desktop client applications such as the Apple iTunes online content store.
Some airlines offer VOD as in-flight entertainment to passengers through individually controlled video screens embedded in seatback so or armrests or offered via portable media players. Some video on demand services, such as Netflix, use a subscription model that requires users to pay a monthly fee to access a bundled set of content, which is mainly movies and TV shows. Other services use an advertising-based model, where access is free for Internet users, and the platforms rely on selling advertisements as their main revenue stream.
Functionality:
Downloading and streaming video on demand systems provide the user with all of the features of Portable media players and DVD players. Some VOD systems that store and stream programs from hard disk drives use a memory buffer to allow the user to fast forward and rewind digital videos. It is possible to put video servers on local area networks, in which case they can provide very rapid response to users.
Streaming video servers can also serve a wider community via a WAN, in which case the responsiveness may be reduced. Download VOD services are practical to homes equipped with cable modems or DSL connections. Servers for traditional cable and telco VOD services are usually placed at the cable head-end serving a particular market as well as cable hubs in larger markets. In the telco world, they are placed in either the central office, or a newly created location called a Video Head-End Office (VHO).
Types of Video on Demand:
Transactional video on demand (TVOD) is a distribution method by which customers pay for each individual piece of video on demand content. For example, a customer would pay a fee for each individual movie or TV show that they watch. TVOD has two sub-categories: electronic sell-through (EST), by which customers can permanently access a piece of content once purchased via Internet; and download to rent (DTR), by which customers can access the content for a limited time upon renting. Examples of TVOD services include Apple's iTunes online store and Google's Google Play service.
Catch Up TV:
A growing number of TV stations offer "catch-up TV" as a way for viewers to watch TV shows though their VOD service hours or even days after the original television broadcast.
This enables viewers to watch a program when they have free time, even if this is not when the program was originally aired. Some studies show that catch up TV is starting to represent a large amount of the views and hours watched, and that users tend to watch catch up TV programs for longer, when compared to live TV (e.g., regular scheduled broadcast TV).
Subscription VOD (SVOD) services use a subscription business model, where subscribers are charged a monthly fee to access unlimited programs. These services include the following:
Near video on demand (NVOD) is a pay-per-view consumer video technique used by multi-channel broadcasters using high-bandwidth distribution mechanisms such as satellite and cable television. Multiple copies of a program are broadcast at short time intervals (typically 10–20 minutes) providing convenience for viewers, who can watch the program without needing to tune in at only scheduled point in time.
A viewer may only have to wait a few minutes before the next time a movie will be programmed. This form is very bandwidth-intensive and is generally provided only by large operators with a great deal of redundant capacity and has been reduced in popularity as video on demand is implemented.
Only the satellite services Dish Network and DirecTV continue to provide NVOD experiences. These satellite services provide NVOD because many of their customers have no access to the services' broadband VOD services.
Before the rise of video on demand, the pay-per-view provider In Demand provided up to 40 channels in 2002, with several films receiving up to four channels on the staggered schedule to provide the NVOD experience for viewers.
As of 2014, only four channels (two in high definition, two in standard definition) are provided to facilitate live and event coverage, along with existing league out-of-market sports coverage channels (varied by provider) by the service. In Australia, pay TV broadcaster Foxtel offers NVOD for new release movies.
Push video on demand is so-named because the provider "pushes" the content out to the viewer's set-top box without the viewer having requested the content. This technique used by a number of broadcasters on systems that lack the connectivity and bandwidth to provide true "streaming" video on demand.
Push VOD is also used by broadcasters who want to optimize their video streaming infrastructure by pre-loading the most popular contents (e.g., that week's top ten films or shows) to the consumers' set-top device. In this way, the most popular content is already loaded onto a consumer's set-top DVR. That way, if the consumer requests one of these films, it is already loaded on her/his DVR.
A push VOD system uses a personal video recorder (PVR) to store a selection of content, often transmitted in spare capacity overnight or all day long at low bandwidth. Users can watch the downloaded content at the time they desire, immediately and without any buffering issues. Push VOD depends on the viewer recording content, so choices can be limited.
As content occupies space on the PVR hard drive, downloaded content is usually deleted after a week to make way for newer programs or movies. The limited space on a PVR hard drive means that the selection of programs is usually restricted to the most popular content. A new generation of Push VOD solution recently appeared on the market which, by using efficient error correction mechanisms, can free significant amount of bandwidth and that can deliver more than video e.g. digital version of magazines and interactive applications.
Advertising video on demand is a VOD model which uses an advertising-based revenue model. This allows companies that advertise on broadcast and cable channels to reach people who watch shows using VOD. As well, this model allows people to watch programs without paying subscription fees.
Hulu has been one of the major AVOD companies, though the company ended free service in August 2016. Ads still run on the subscription service.
Yahoo View continues to offer a free AVOD model. Advertisers may find that people watching on VOD services do not want the same ads to appear multiple times.
Crackle has introduced the concept of a series of ads for the same company that tie in to what is being watched.
Click on any of the following blue hyperlinks for more about Video On Demand:
Television VOD systems can either "stream" content through a set-top box, a computer or other device, allowing viewing in real time, or download it to a device such as a computer, digital video recorder (also called a personal video recorder) or portable media player for viewing at any time.
The majority of cable- and telephone company-based television providers offer both VOD streaming, including pay-per-view and free content, whereby a user buys or selects a movie or television program and it begins to play on the television set almost instantaneously, or downloading to a digital video recorder (DVR) rented or purchased from the provider, or downloaded onto a PC or to a portable device, for viewing in the future.
Internet television, using the Internet, is an increasingly popular form of video on demand. VOD can also be accessed via desktop client applications such as the Apple iTunes online content store.
Some airlines offer VOD as in-flight entertainment to passengers through individually controlled video screens embedded in seatback so or armrests or offered via portable media players. Some video on demand services, such as Netflix, use a subscription model that requires users to pay a monthly fee to access a bundled set of content, which is mainly movies and TV shows. Other services use an advertising-based model, where access is free for Internet users, and the platforms rely on selling advertisements as their main revenue stream.
Functionality:
Downloading and streaming video on demand systems provide the user with all of the features of Portable media players and DVD players. Some VOD systems that store and stream programs from hard disk drives use a memory buffer to allow the user to fast forward and rewind digital videos. It is possible to put video servers on local area networks, in which case they can provide very rapid response to users.
Streaming video servers can also serve a wider community via a WAN, in which case the responsiveness may be reduced. Download VOD services are practical to homes equipped with cable modems or DSL connections. Servers for traditional cable and telco VOD services are usually placed at the cable head-end serving a particular market as well as cable hubs in larger markets. In the telco world, they are placed in either the central office, or a newly created location called a Video Head-End Office (VHO).
Types of Video on Demand:
Transactional video on demand (TVOD) is a distribution method by which customers pay for each individual piece of video on demand content. For example, a customer would pay a fee for each individual movie or TV show that they watch. TVOD has two sub-categories: electronic sell-through (EST), by which customers can permanently access a piece of content once purchased via Internet; and download to rent (DTR), by which customers can access the content for a limited time upon renting. Examples of TVOD services include Apple's iTunes online store and Google's Google Play service.
Catch Up TV:
A growing number of TV stations offer "catch-up TV" as a way for viewers to watch TV shows though their VOD service hours or even days after the original television broadcast.
This enables viewers to watch a program when they have free time, even if this is not when the program was originally aired. Some studies show that catch up TV is starting to represent a large amount of the views and hours watched, and that users tend to watch catch up TV programs for longer, when compared to live TV (e.g., regular scheduled broadcast TV).
Subscription VOD (SVOD) services use a subscription business model, where subscribers are charged a monthly fee to access unlimited programs. These services include the following:
Near video on demand (NVOD) is a pay-per-view consumer video technique used by multi-channel broadcasters using high-bandwidth distribution mechanisms such as satellite and cable television. Multiple copies of a program are broadcast at short time intervals (typically 10–20 minutes) providing convenience for viewers, who can watch the program without needing to tune in at only scheduled point in time.
A viewer may only have to wait a few minutes before the next time a movie will be programmed. This form is very bandwidth-intensive and is generally provided only by large operators with a great deal of redundant capacity and has been reduced in popularity as video on demand is implemented.
Only the satellite services Dish Network and DirecTV continue to provide NVOD experiences. These satellite services provide NVOD because many of their customers have no access to the services' broadband VOD services.
Before the rise of video on demand, the pay-per-view provider In Demand provided up to 40 channels in 2002, with several films receiving up to four channels on the staggered schedule to provide the NVOD experience for viewers.
As of 2014, only four channels (two in high definition, two in standard definition) are provided to facilitate live and event coverage, along with existing league out-of-market sports coverage channels (varied by provider) by the service. In Australia, pay TV broadcaster Foxtel offers NVOD for new release movies.
Push video on demand is so-named because the provider "pushes" the content out to the viewer's set-top box without the viewer having requested the content. This technique used by a number of broadcasters on systems that lack the connectivity and bandwidth to provide true "streaming" video on demand.
Push VOD is also used by broadcasters who want to optimize their video streaming infrastructure by pre-loading the most popular contents (e.g., that week's top ten films or shows) to the consumers' set-top device. In this way, the most popular content is already loaded onto a consumer's set-top DVR. That way, if the consumer requests one of these films, it is already loaded on her/his DVR.
A push VOD system uses a personal video recorder (PVR) to store a selection of content, often transmitted in spare capacity overnight or all day long at low bandwidth. Users can watch the downloaded content at the time they desire, immediately and without any buffering issues. Push VOD depends on the viewer recording content, so choices can be limited.
As content occupies space on the PVR hard drive, downloaded content is usually deleted after a week to make way for newer programs or movies. The limited space on a PVR hard drive means that the selection of programs is usually restricted to the most popular content. A new generation of Push VOD solution recently appeared on the market which, by using efficient error correction mechanisms, can free significant amount of bandwidth and that can deliver more than video e.g. digital version of magazines and interactive applications.
Advertising video on demand is a VOD model which uses an advertising-based revenue model. This allows companies that advertise on broadcast and cable channels to reach people who watch shows using VOD. As well, this model allows people to watch programs without paying subscription fees.
Hulu has been one of the major AVOD companies, though the company ended free service in August 2016. Ads still run on the subscription service.
Yahoo View continues to offer a free AVOD model. Advertisers may find that people watching on VOD services do not want the same ads to appear multiple times.
Crackle has introduced the concept of a series of ads for the same company that tie in to what is being watched.
Click on any of the following blue hyperlinks for more about Video On Demand:
Internet Movie Database (IMDB)
YouTube Video: IMDB Top 250 in 2 1/2 Minutes
The Internet Movie Database (abbreviated IMDb) is an online database of information related to films, television programs and video games, including cast, production crew, fictional characters, biographies, plot summaries, trivia and reviews, operated by IMDb.com, Inc., a subsidiary of Amazon. As of June 2017, IMDb has approximately 4.4 million titles (including episodes), 8 million personalities in its database, as well as 75 million registered users.
The site enables registered users to submit new material and edits to existing entries. Although all data is checked before going live, the system has been open to abuse and occasional errors are acknowledged. Users are also invited to rate any film on a scale of 1 to 10, and the totals are converted into a weighted mean-rating that is displayed beside each title, with online filters employed to deter ballot-stuffing.
The site also featured message boards for authenticated users which IMDb shutdown permanently on February 20, 2017.
Anyone with an internet connection can view the movie and talent pages of IMDb. A registration process is necessary however, to contribute info to the site. A registered user chooses a site name for themselves, and is given a profile page.
This profile page also shows how long a registered user has been a member, as well as personal movie ratings (should the user decide to display them), and is also awarded badges representing how many contributions any particular registered user has submitted.
These badges range from total contributions made, to independent categories such as photos, trivia, bios, etc. If a registered user or visitor happens to be in the entertainment industry, and has an IMDb page, that user/visitor can add photos to that page by enrolling in IMDbPRO.
Click on any of the following blue hyperlinks for more about IMDb:
The site enables registered users to submit new material and edits to existing entries. Although all data is checked before going live, the system has been open to abuse and occasional errors are acknowledged. Users are also invited to rate any film on a scale of 1 to 10, and the totals are converted into a weighted mean-rating that is displayed beside each title, with online filters employed to deter ballot-stuffing.
The site also featured message boards for authenticated users which IMDb shutdown permanently on February 20, 2017.
Anyone with an internet connection can view the movie and talent pages of IMDb. A registration process is necessary however, to contribute info to the site. A registered user chooses a site name for themselves, and is given a profile page.
This profile page also shows how long a registered user has been a member, as well as personal movie ratings (should the user decide to display them), and is also awarded badges representing how many contributions any particular registered user has submitted.
These badges range from total contributions made, to independent categories such as photos, trivia, bios, etc. If a registered user or visitor happens to be in the entertainment industry, and has an IMDb page, that user/visitor can add photos to that page by enrolling in IMDbPRO.
Click on any of the following blue hyperlinks for more about IMDb:
- History
- IMDbPRO
- Television episodes
- Characters' filmography
- Instant viewing
- Content and format
- Ancillary features
- Litigation
- See also:
- AllMovie
- AllMusic – a similar database, but for music
- All Media Network – a commercial database launched by the Rovi Corporation that compiles information from the former services AllMovie and AllMusic
- Animator.ru
- Big Cartoon DataBase
- DBCult Film Institute
- Discogs
- Filmweb
- FindAnyFilm.com
- Flickchart
- Goodreads
- Internet Adult Film Database
- Internet Movie Cars Database (IMCDb)
- Internet Movie Firearms Database (IMFDb)
- Internet Book Database (IBookDb)
- Internet Broadway Database (IBDb)
- Internet Off-Broadway Database (IOBDb)
- Internet Speculative Fiction Database (ISFDb)
- Internet Theatre Database (ITDb)
- Letterboxd
- List of films considered the best
- List of films considered the worst
- TheTVDB
Travel Websites, including a List
YouTube Video: How to Book Your Own Flight

Click here for a List of Online Travel Websites.
A travel website is a website on the world wide web that is dedicated to travel. The site may be focused on travel reviews, trip fares, or a combination of both. Approximately seventy million consumers researched travel plans online in July 2006. Travel bookings are the single largest component of e-commerce, according to Forrester Research.
Many travel websites are online travelogues or travel journals, usually created by individual travelers and hosted by companies that generally provide their information to consumers for free. These companies generate revenue through advertising or by providing services to other businesses. This medium produces a wide variety of styles, often incorporating graphics, photography, maps, and other unique content.
Some examples of websites that use a combination of travel reviews and the booking of travel are TripAdvisor, Priceline, Liberty Holidays, and Expedia.
Service Providers:
Individual airlines, hotels, bed and breakfasts, cruise lines, automobile rental companies, and other travel-related service providers often maintain their own web sites providing retail sales. Many with complex offerings include some sort of search engine technology to look for bookings within a certain time frame, service class, geographic location, or price range.
Online Travel Agencies:
An online travel agency (OTA) specializes in offering planning sources and booking capabilities. Major OTAs include:
Fare aggregators and metasearch engines:
The average consumer visits 3.6 sites when shopping for an airline ticket online, according to PhoCusWright, a Sherman, CT-based travel technology firm.
Yahoo claims 76% of all online travel purchases are preceded by some sort of search function, according to Malcolmson, director of product development for Yahoo Travel.
The 2004 Travel Consumer Survey published by Jupiter Research reported that "nearly two in five online travel consumers say they believe that no one site has the lowest rates or fares.
Thus a niche has existed for aggregate travel search to find the lowest rates from multiple travel sites, obviating the need for consumers to cross-shop from site to site, with traveling searching occurring quite frequently.
Metasearch engines are so named as they conduct searches across multiple independent search engines. Metasearch engines often make use of "screen scraping" to get live availability of flights. Screen scraping is a way of crawling through the airline websites, getting content from those sites by extracting data from the same HTML feed used by consumers for browsing (rather than using a Semantic Web or database feed designed to be machine-readable).
Metasearch engines usually process incoming data to eliminate duplicate entries, but may not expose "advanced search" options in the underlying databases (because not all databases support the same options).
Fare aggregators redirect the users to an airline, cruise, hotel, or car rental site or Online Travel Agent for the final purchase of a ticket. Aggregators' business models include getting feeds from major OTAs, then displaying to the users all of the results on one screen. The OTA then fulfills the ticket. Aggregators generate revenues through advertising and charging OTAs for referring clients.
Examples of aggregate sites include:
Kayak.com is unusual in linking to online travel agencies and hotel web sites alike, allowing the customer to choose whether to book directly on the hotel web site or through an online travel agency. Google Hotel Finder is an experiment that allows to find hotel prices with Google, however it does not offer to book hotels, merely to compare rates.
The difference between a "fare aggregator" and "metasearch engine" is unclear, though different terms may imply different levels of cooperation between the companies involved.
In 2008, Ryanair threatened to cancel all bookings made on Ryanair flights made through metasearch engines, but later allowed the sites to operate as long as they did not resell tickets or overload Ryanair's servers.
In 2015, Lufthansa Group (including Lufthansa, Austrian Airlines, Brussels Airlines and Swiss) announced adding surcharge for flights booked on other sites.
Bargain Websites:
Travel bargain websites collect and publish bargain rates by advising consumers where to find them online (sometimes but not always through a direct link). Rather than providing detailed search tools, these sites generally focus on offering advertised specials, such as last-minute sales from travel suppliers eager to deplete unused inventory; therefore, these sites often work best for consumers who are flexible about destinations and other key itinerary components.
Travel and tourism guides:
Many websites take the form of a digital version of a traditional guide book, aiming to provide advice on which destinations, attractions, accommodations, and so on, are worth a visit and providing information on how to access them.
Most states, provinces and countries have their own convention and visitor bureaus, which usually sponsor a website dedicated to promoting tourism in their respective regions. Cities that rely on tourism also operate websites promoting their destinations, such as VEGAS.com for Las Vegas, Nevada.
Student travel agencies:
Some travel websites cater specifically to the college student audience and list exclusive airfare deals and travel products. Significant sites in this area include StudentUniverse and STA Travel.
Social travel website:
A social travel website is a type of travel website that will look at where the user is going and pair them with other places they want to go based on where other people have gone. This can help the traveler gain insight of the destination, people, culture before travel and become aware of the places the user is willing to visit.
Copyleft travel websites:
There are two travel websites where the rationale of the crowdsourcing is clear for the contributor as all edits to these are under copyleft license (CC-BY-SA): the ad-free Wikivoyage operated by Wikimedia Foundation and Wikitravel by a for-profit entity.
See also:
A travel website is a website on the world wide web that is dedicated to travel. The site may be focused on travel reviews, trip fares, or a combination of both. Approximately seventy million consumers researched travel plans online in July 2006. Travel bookings are the single largest component of e-commerce, according to Forrester Research.
Many travel websites are online travelogues or travel journals, usually created by individual travelers and hosted by companies that generally provide their information to consumers for free. These companies generate revenue through advertising or by providing services to other businesses. This medium produces a wide variety of styles, often incorporating graphics, photography, maps, and other unique content.
Some examples of websites that use a combination of travel reviews and the booking of travel are TripAdvisor, Priceline, Liberty Holidays, and Expedia.
Service Providers:
Individual airlines, hotels, bed and breakfasts, cruise lines, automobile rental companies, and other travel-related service providers often maintain their own web sites providing retail sales. Many with complex offerings include some sort of search engine technology to look for bookings within a certain time frame, service class, geographic location, or price range.
Online Travel Agencies:
An online travel agency (OTA) specializes in offering planning sources and booking capabilities. Major OTAs include:
- Voyages-sncf.com – revenue €2.23 billion (2008)
- Expedia, Inc., including:
- Expedia.com,
- Hotels.com,
- Hotwire.com,
- Travelocity and others – revenue US$2.937 billion (2008),
- later expanded to include Orbitz Worldwide, Inc., including:
- Orbitz,
- CheapTickets,
- ebookers,
- and others –
- revenue US$870 million (2008)
- Sabre Holdings, including lastminute.com and others – revenue US$2.9 billion (2008)
- Opodo – revenue €1.3 billion (2008)
- The Priceline Group, including:
- Priceline.com,
- Booking.com,
- Agoda.com,
- Kayak.com,
- OpenTable
- and others
- revenue US$1.9 billion (2008)
- Travelgenio – revenue €344 million (2014)
- Wotif.com – revenue A$145 million (2012)
- Webjet – revenue A$59.3 million (2012)
Fare aggregators and metasearch engines:
The average consumer visits 3.6 sites when shopping for an airline ticket online, according to PhoCusWright, a Sherman, CT-based travel technology firm.
Yahoo claims 76% of all online travel purchases are preceded by some sort of search function, according to Malcolmson, director of product development for Yahoo Travel.
The 2004 Travel Consumer Survey published by Jupiter Research reported that "nearly two in five online travel consumers say they believe that no one site has the lowest rates or fares.
Thus a niche has existed for aggregate travel search to find the lowest rates from multiple travel sites, obviating the need for consumers to cross-shop from site to site, with traveling searching occurring quite frequently.
Metasearch engines are so named as they conduct searches across multiple independent search engines. Metasearch engines often make use of "screen scraping" to get live availability of flights. Screen scraping is a way of crawling through the airline websites, getting content from those sites by extracting data from the same HTML feed used by consumers for browsing (rather than using a Semantic Web or database feed designed to be machine-readable).
Metasearch engines usually process incoming data to eliminate duplicate entries, but may not expose "advanced search" options in the underlying databases (because not all databases support the same options).
Fare aggregators redirect the users to an airline, cruise, hotel, or car rental site or Online Travel Agent for the final purchase of a ticket. Aggregators' business models include getting feeds from major OTAs, then displaying to the users all of the results on one screen. The OTA then fulfills the ticket. Aggregators generate revenues through advertising and charging OTAs for referring clients.
Examples of aggregate sites include:
- Bravofly,
- Cheapflights,
- Priceline,
- Expedia,
- Reservations.com,
- Kayak.com,
- Momondo,
- LowEndTicket,
- FareBuzz,
- and CheapOair.
Kayak.com is unusual in linking to online travel agencies and hotel web sites alike, allowing the customer to choose whether to book directly on the hotel web site or through an online travel agency. Google Hotel Finder is an experiment that allows to find hotel prices with Google, however it does not offer to book hotels, merely to compare rates.
The difference between a "fare aggregator" and "metasearch engine" is unclear, though different terms may imply different levels of cooperation between the companies involved.
In 2008, Ryanair threatened to cancel all bookings made on Ryanair flights made through metasearch engines, but later allowed the sites to operate as long as they did not resell tickets or overload Ryanair's servers.
In 2015, Lufthansa Group (including Lufthansa, Austrian Airlines, Brussels Airlines and Swiss) announced adding surcharge for flights booked on other sites.
Bargain Websites:
Travel bargain websites collect and publish bargain rates by advising consumers where to find them online (sometimes but not always through a direct link). Rather than providing detailed search tools, these sites generally focus on offering advertised specials, such as last-minute sales from travel suppliers eager to deplete unused inventory; therefore, these sites often work best for consumers who are flexible about destinations and other key itinerary components.
Travel and tourism guides:
Many websites take the form of a digital version of a traditional guide book, aiming to provide advice on which destinations, attractions, accommodations, and so on, are worth a visit and providing information on how to access them.
Most states, provinces and countries have their own convention and visitor bureaus, which usually sponsor a website dedicated to promoting tourism in their respective regions. Cities that rely on tourism also operate websites promoting their destinations, such as VEGAS.com for Las Vegas, Nevada.
Student travel agencies:
Some travel websites cater specifically to the college student audience and list exclusive airfare deals and travel products. Significant sites in this area include StudentUniverse and STA Travel.
Social travel website:
A social travel website is a type of travel website that will look at where the user is going and pair them with other places they want to go based on where other people have gone. This can help the traveler gain insight of the destination, people, culture before travel and become aware of the places the user is willing to visit.
Copyleft travel websites:
There are two travel websites where the rationale of the crowdsourcing is clear for the contributor as all edits to these are under copyleft license (CC-BY-SA): the ad-free Wikivoyage operated by Wikimedia Foundation and Wikitravel by a for-profit entity.
See also:
Employment Websites, including a List
YouTube Video: Is Applying for Jobs Online an Effective Way to Find Work?
by PBS News Hour

Click here for an alphabetical List of Employment Websites.
An employment website is a website that deals specifically with employment or careers.
Many employment websites are designed to allow employers to post job requirements for a position to be filled and are commonly known as job boards. Other employment sites offer employer reviews, career and job-search advice, and describe different job descriptions or employers. Through a job website a prospective employee can locate and fill out a job application or submit resumes over the Internet for the advertised position.
The Online Career Center was developed as a non-profit organization backed by forty major corporations to allow job hunters to post their resumes and for recruiters to post job openings.
In 1994 Robert J. McGovern began NetStart Inc. as software sold to companies for listing job openings on their websites and manage the incoming e-mails those listings generated. After an influx of two million dollars in investment capital, he then transported this software to its own web address, at first listing the job openings from the companies who utilized the software.
NetStart Inc. changed its name in 1998 to operate under the name of their software, CareerBuilder. The company received a further influx of seven million dollars from investment firms such as New Enterprise Associates to expand their operations.
Six major newspapers joined forces in 1995 to list their classified sections online. The service was called CareerPath.com and featured help-wanted listings from the Los Angeles Times, the Boston Globe, Chicago Tribune, the New York Times, San Jose Mercury News and the Washington Post.
The industry attempted to reach a broader, less tech-savvy base in 1998 when Hotjobs.com attempted to buy a Super Bowl spot, but Fox rejected the ad for being in poor taste. The ad featured a janitor at a zoo sweeping out the elephant cage completely unbeknownst to the animal. The elephant sits down briefly and when it stands back up, the janitor has disappeared. The ad meant to illustrate a need for those stuck in jobs they hate, and offer a solution through their Web site.
In 1999, Monster.com ran on three 30 second Super Bowl ads for four million dollars. One ad which featured children speaking like adults, drolly intoning their dream of working at various dead-end jobs to humorous effect were far more popular than rival Hotjobs.com ad about a security guard who transitions from a low paying security job to the same job at a fancier building.
Soon thereafter, Monster.com was elevated to the top spot of online employment sites. Hotjobs.com's ad wasn't as successful, but it gave the company enough of a boost for its IPO in August.
After being purchased in a joint venture by Knight Ridder and Tribune Company in July, CareerBuilder absorbed competitor boards CareerPath.com and then Headhunter.net which had already acquired CareerMosaic.
Even with these aggressive mergers CareerBuilder still trailed behind the number one employment site Jobsonline.com, number two Monster.com and number three Hotjobs.com.
Monster.com made a move in 2001 to purchase Hotjobs.com for $374 million in stock, but were unsuccessful due to Yahoo's unsolicited cash and stock bid of $430 million late in the year. Yahoo had previously announced plans to enter the job board business, but decided to jump start that venture by purchasing the established brand.
In February 2010, Monster acquired HotJobs from Yahoo for $225 million.
Features and Types:
The success of jobs search engines in bridging the gap between job-seekers and employers has spawned thousands of job sites, many of which list job opportunities in a specific sector, such as education, health care, hospital management, academics and even in the non-governmental sector. These sites range from broad all-purpose generalist job boards to niche sites that serve various audiences, geographies, and industries. Many industry experts are encouraging job-seekers to concentrate on industry specific sector sites.
Job Postings:
A job board is a website that facilitates job hunting and range from large scale generalist sites to niche job boards for job categories such as engineering, legal, insurance, social work, teaching, mobile app development as well as cross-sector categories such as green jobs, ethical jobs and seasonal jobs. Users can typically deposit their résumés and submit them to potential employers and recruiters for review, while employers and recruiters can post job ads and search for potential employees.
The term job search engine might refer to a job board with a search engine style interface, or to a web site that actually indexes and searches other web sites.
Niche job boards are starting to play a bigger role in providing more targeted job vacancies and employees to the candidate and the employer respectively. Job boards such as airport jobs and federal jobs among others provide a very focused way of eliminating and reducing time to applying to the most appropriate role. USAJobs.gov is the United States' official website for jobs. It gathers job listings from over 500 federal agencies.
Metasearch and vertical search engines
Some web sites are simply search engines that collect results from multiple independent job boards. This is an example of both metasearch (since these are search engines which search other search engines) and vertical search (since the searches are limited to a specific topic - job listings).
Some of these new search engines primarily index traditional job boards. These sites aim to provide a "one-stop shop" for job-seekers who don't need to search the underlying job boards.
In 2006, tensions developed between the job boards and several scraper sites, with Craigslist banning scrapers from its job classifieds and Monster.com specifically banning scrapers through its adoption of a robots exclusion standard on all its pages while others have embraced them.
Indeed.com, a "job aggregator", collects job postings from employer websites, job boards, online classifieds, and association websites. Simply Hired is another large aggregator collecting job postings from many sources.
LinkUp (website) is a job search engine ("job aggregator") that indexes pages only from employers' websites choosing to bypass traditional job boards entirely. These vertical search engines allow jobseekers to find new positions that may not be advertised on the traditional job boards.
Industry specific posting boards are also appearing. These consolidate all the vacancies in a very specific industry. The largest "niche" job board is Dice.com which focuses on the IT industry. Many industry and professional associations offer members a job posting capability on the association website.
Employer review website:
An employer review website is a type of employment website where past and current employees post comments about their experiences working for a company or organization. An employer review website usually takes the form of an internet forum.
Typical comments are about management, working conditions, and pay. Although employer review websites may produce links to potential employers, they do not necessarily list vacancies.
Pay For Performance (PFP):
The most recent second generation of employment websites, often referred to as pay for performance (PFP) involves charging for membership services rendered to job seekers.
Websites providing information and advice for employees, employers and job seekers:
Although many sites that provide access to job advertisements include pages with advice about writing resumes and CVs, performing well in interviews, and other topics of interest to job seekers there are sites that specialize in providing information of this kind, rather than job opportunities.
One such is Working in Canada. It does provide links to the Canadian Job Bank. However, most of its content is information about local labor markets (in Canada), requirements for working in various occupations, information about relevant laws and regulations, government services and grants, and so on. Most items could be of interest to people in various roles and conditions including those considering career options, job seekers, employers and employees.
Risks:
Many jobs search engines and jobs boards encourage users to post their resume and contact details. While this is attractive for the site operators (who sell access to the resume bank to headhunters and recruiters), job-seekers exercise caution in uploading personal information, since they have no control over where their resume will eventually be seen.
Their resume may be viewed by a current employer or, worse, by criminals who may use information from it to amass and sell personal contact information, or even perpetrate identity theft.
See Also:
An employment website is a website that deals specifically with employment or careers.
Many employment websites are designed to allow employers to post job requirements for a position to be filled and are commonly known as job boards. Other employment sites offer employer reviews, career and job-search advice, and describe different job descriptions or employers. Through a job website a prospective employee can locate and fill out a job application or submit resumes over the Internet for the advertised position.
The Online Career Center was developed as a non-profit organization backed by forty major corporations to allow job hunters to post their resumes and for recruiters to post job openings.
In 1994 Robert J. McGovern began NetStart Inc. as software sold to companies for listing job openings on their websites and manage the incoming e-mails those listings generated. After an influx of two million dollars in investment capital, he then transported this software to its own web address, at first listing the job openings from the companies who utilized the software.
NetStart Inc. changed its name in 1998 to operate under the name of their software, CareerBuilder. The company received a further influx of seven million dollars from investment firms such as New Enterprise Associates to expand their operations.
Six major newspapers joined forces in 1995 to list their classified sections online. The service was called CareerPath.com and featured help-wanted listings from the Los Angeles Times, the Boston Globe, Chicago Tribune, the New York Times, San Jose Mercury News and the Washington Post.
The industry attempted to reach a broader, less tech-savvy base in 1998 when Hotjobs.com attempted to buy a Super Bowl spot, but Fox rejected the ad for being in poor taste. The ad featured a janitor at a zoo sweeping out the elephant cage completely unbeknownst to the animal. The elephant sits down briefly and when it stands back up, the janitor has disappeared. The ad meant to illustrate a need for those stuck in jobs they hate, and offer a solution through their Web site.
In 1999, Monster.com ran on three 30 second Super Bowl ads for four million dollars. One ad which featured children speaking like adults, drolly intoning their dream of working at various dead-end jobs to humorous effect were far more popular than rival Hotjobs.com ad about a security guard who transitions from a low paying security job to the same job at a fancier building.
Soon thereafter, Monster.com was elevated to the top spot of online employment sites. Hotjobs.com's ad wasn't as successful, but it gave the company enough of a boost for its IPO in August.
After being purchased in a joint venture by Knight Ridder and Tribune Company in July, CareerBuilder absorbed competitor boards CareerPath.com and then Headhunter.net which had already acquired CareerMosaic.
Even with these aggressive mergers CareerBuilder still trailed behind the number one employment site Jobsonline.com, number two Monster.com and number three Hotjobs.com.
Monster.com made a move in 2001 to purchase Hotjobs.com for $374 million in stock, but were unsuccessful due to Yahoo's unsolicited cash and stock bid of $430 million late in the year. Yahoo had previously announced plans to enter the job board business, but decided to jump start that venture by purchasing the established brand.
In February 2010, Monster acquired HotJobs from Yahoo for $225 million.
Features and Types:
The success of jobs search engines in bridging the gap between job-seekers and employers has spawned thousands of job sites, many of which list job opportunities in a specific sector, such as education, health care, hospital management, academics and even in the non-governmental sector. These sites range from broad all-purpose generalist job boards to niche sites that serve various audiences, geographies, and industries. Many industry experts are encouraging job-seekers to concentrate on industry specific sector sites.
Job Postings:
A job board is a website that facilitates job hunting and range from large scale generalist sites to niche job boards for job categories such as engineering, legal, insurance, social work, teaching, mobile app development as well as cross-sector categories such as green jobs, ethical jobs and seasonal jobs. Users can typically deposit their résumés and submit them to potential employers and recruiters for review, while employers and recruiters can post job ads and search for potential employees.
The term job search engine might refer to a job board with a search engine style interface, or to a web site that actually indexes and searches other web sites.
Niche job boards are starting to play a bigger role in providing more targeted job vacancies and employees to the candidate and the employer respectively. Job boards such as airport jobs and federal jobs among others provide a very focused way of eliminating and reducing time to applying to the most appropriate role. USAJobs.gov is the United States' official website for jobs. It gathers job listings from over 500 federal agencies.
Metasearch and vertical search engines
Some web sites are simply search engines that collect results from multiple independent job boards. This is an example of both metasearch (since these are search engines which search other search engines) and vertical search (since the searches are limited to a specific topic - job listings).
Some of these new search engines primarily index traditional job boards. These sites aim to provide a "one-stop shop" for job-seekers who don't need to search the underlying job boards.
In 2006, tensions developed between the job boards and several scraper sites, with Craigslist banning scrapers from its job classifieds and Monster.com specifically banning scrapers through its adoption of a robots exclusion standard on all its pages while others have embraced them.
Indeed.com, a "job aggregator", collects job postings from employer websites, job boards, online classifieds, and association websites. Simply Hired is another large aggregator collecting job postings from many sources.
LinkUp (website) is a job search engine ("job aggregator") that indexes pages only from employers' websites choosing to bypass traditional job boards entirely. These vertical search engines allow jobseekers to find new positions that may not be advertised on the traditional job boards.
Industry specific posting boards are also appearing. These consolidate all the vacancies in a very specific industry. The largest "niche" job board is Dice.com which focuses on the IT industry. Many industry and professional associations offer members a job posting capability on the association website.
Employer review website:
An employer review website is a type of employment website where past and current employees post comments about their experiences working for a company or organization. An employer review website usually takes the form of an internet forum.
Typical comments are about management, working conditions, and pay. Although employer review websites may produce links to potential employers, they do not necessarily list vacancies.
Pay For Performance (PFP):
The most recent second generation of employment websites, often referred to as pay for performance (PFP) involves charging for membership services rendered to job seekers.
Websites providing information and advice for employees, employers and job seekers:
Although many sites that provide access to job advertisements include pages with advice about writing resumes and CVs, performing well in interviews, and other topics of interest to job seekers there are sites that specialize in providing information of this kind, rather than job opportunities.
One such is Working in Canada. It does provide links to the Canadian Job Bank. However, most of its content is information about local labor markets (in Canada), requirements for working in various occupations, information about relevant laws and regulations, government services and grants, and so on. Most items could be of interest to people in various roles and conditions including those considering career options, job seekers, employers and employees.
Risks:
Many jobs search engines and jobs boards encourage users to post their resume and contact details. While this is attractive for the site operators (who sell access to the resume bank to headhunters and recruiters), job-seekers exercise caution in uploading personal information, since they have no control over where their resume will eventually be seen.
Their resume may be viewed by a current employer or, worse, by criminals who may use information from it to amass and sell personal contact information, or even perpetrate identity theft.
See Also:
Websites, including a List
YouTube Video: How To Make a WordPress Website - 2017 - Create Almost Any Website!
Pictured: NASA Website Home Page, courtesy of NASA, Page Editor: Jim Wilson, NASA Official: Brian Dunbar - /, Public Domain
Click Here for a List of Websites by Type, Subject, and Other.
A website, or simply site, is a collection of related web pages, including multimedia content, typically identified with a common domain name, and published on at least one web server. A website may be accessible via a public Internet Protocol (IP) network, such as the Internet, or a private local area network (LAN), by referencing a uniform resource locator (URL) that identifies the site.
Websites have many functions and can be used in various fashions; a website can be a personal website, a commercial website for a company, a government website or a non-profit organization website. Websites are typically dedicated to a particular topic or purpose, ranging from entertainment and social networking to providing news and education.
All publicly accessible websites collectively constitute the World Wide Web, while private websites, such as a company's website for its employees, are typically a part of an intranet.
Web pages, which are the building blocks of websites, are documents, typically composed in plain text interspersed with formatting instructions of Hypertext Markup Language (HTML, XHTML). They may incorporate elements from other websites with suitable markup anchors.
Web pages are accessed and transported with the Hypertext Transfer Protocol (HTTP), which may optionally employ encryption (HTTP Secure, HTTPS) to provide security and privacy for the user. The user's application, often a web browser, renders the page content according to its HTML markup instructions onto a display terminal.
Hyperlinking between web pages conveys to the reader the site structure and guides the navigation of the site, which often starts with a home page containing a directory of the site web content.
Some websites require user registration or subscription to access content. Examples of subscription websites include many business sites, news websites, academic journal websites, gaming websites, file-sharing websites, message boards, web-based email, social networking websites, websites providing real-time stock market data, as well as sites providing various other services. As of 2016 end users can access websites on a range of devices, including desktop and laptop computers, tablet computers, smartphones and smart TVs.
History: Main article: History of the World Wide Web
The World Wide Web (WWW) was created in 1990 by the British CERN physicist Tim Berners-Lee. On 30 April 1993, CERN announced that the World Wide Web would be free to use for anyone. Before the introduction of HTML and HTTP, other protocols such as File Transfer Protocol and the gopher protocol were used to retrieve individual files from a server. These protocols offer a simple directory structure which the user navigates and chooses files to download. Documents were most often presented as plain text files without formatting, or were encoded in word processor formats.
Overview:
Websites have many functions and can be used in various fashions; a website can be a personal website, a commercial website, a government website or a non-profit organization website. Websites can be the work of an individual, a business or other organization, and are typically dedicated to a particular topic or purpose.
Any website can contain a hyperlink to any other website, so the distinction between individual sites, as perceived by the user, can be blurred. Websites are written in, or converted to, HTML (Hyper Text Markup Language) and are accessed using a software interface classified as a user agent.
Web pages can be viewed or otherwise accessed from a range of computer-based and Internet-enabled devices of various sizes, including desktop computers, laptops, PDAs and cell phones. A website is hosted on a computer system known as a web server, also called an HTTP (Hyper Text Transfer Protocol) server.
These terms can also refer to the software that runs on these systems which retrieves and delivers the web pages in response to requests from the website's users. Apache is the most commonly used web server software (according to Netcraft statistics) and Microsoft's IIS is also commonly used. Some alternatives, such as Nginx, Lighttpd, Hiawatha or Cherokee, are fully functional and lightweight.
Static Website: Main article: Static web page
A static website is one that has web pages stored on the server in the format that is sent to a client web browser. It is primarily coded in Hypertext Markup Language (HTML); Cascading Style Sheets (CSS) are used to control appearance beyond basic HTML. Images are commonly used to effect the desired appearance and as part of the main content. Audio or video might also be considered "static" content if it plays automatically or is generally non-interactive.
This type of website usually displays the same information to all visitors. Similar to handing out a printed brochure to customers or clients, a static website will generally provide consistent, standard information for an extended period of time. Although the website owner may make updates periodically, it is a manual process to edit the text, photos and other content and may require basic website design skills and software.
Simple forms or marketing examples of websites, such as classic website, a five-page website or a brochure website are often static websites, because they present pre-defined, static information to the user. This may include information about a company and its products and services through text, photos, animations, audio/video, and navigation menus.
Static websites can be edited using four broad categories of software:
Static websites may still use server side includes (SSI) as an editing convenience, such as sharing a common menu bar across many pages. As the site's behaviour to the reader is still static, this is not considered a dynamic site.
Dynamic Website: Main articles: Dynamic web page and Web application
A dynamic website is one that changes or customizes itself frequently and automatically. Server-side dynamic pages are generated "on the fly" by computer code that produces the HTML (CSS are responsible for appearance and thus, are static files).
There are a wide range of software systems, such as CGI, Java Servlets and Java Server Pages (JSP), Active Server Pages and ColdFusion (CFML) that are available to generate dynamic web systems and dynamic sites. Various web application frameworks and web template systems are available for general-use programming languages like Perl, PHP, Python and Ruby to make it faster and easier to create complex dynamic websites.
A site can display the current state of a dialogue between users, monitor a changing situation, or provide information in some way personalized to the requirements of the individual user. For example, when the front page of a news site is requested, the code running on the web server might combine stored HTML fragments with news stories retrieved from a database or another website via RSS to produce a page that includes the latest information.
Dynamic sites can be interactive by using HTML forms, storing and reading back browser cookies, or by creating a series of pages that reflect the previous history of clicks. Another example of dynamic content is when a retail website with a database of media products allows a user to input a search request, e.g. for the keyword Beatles.
In response, the content of the web page will spontaneously change the way it looked before, and will then display a list of Beatles products like CDs, DVDs and books. Dynamic HTML uses JavaScript code to instruct the web browser how to interactively modify the page contents. One way to simulate a certain type of dynamic website while avoiding the performance loss of initiating the dynamic engine on a per-user or per-connection basis, is to periodically automatically regenerate a large series of static pages.
Click on any of the following blue hyperlinks for more about a Website:
A website, or simply site, is a collection of related web pages, including multimedia content, typically identified with a common domain name, and published on at least one web server. A website may be accessible via a public Internet Protocol (IP) network, such as the Internet, or a private local area network (LAN), by referencing a uniform resource locator (URL) that identifies the site.
Websites have many functions and can be used in various fashions; a website can be a personal website, a commercial website for a company, a government website or a non-profit organization website. Websites are typically dedicated to a particular topic or purpose, ranging from entertainment and social networking to providing news and education.
All publicly accessible websites collectively constitute the World Wide Web, while private websites, such as a company's website for its employees, are typically a part of an intranet.
Web pages, which are the building blocks of websites, are documents, typically composed in plain text interspersed with formatting instructions of Hypertext Markup Language (HTML, XHTML). They may incorporate elements from other websites with suitable markup anchors.
Web pages are accessed and transported with the Hypertext Transfer Protocol (HTTP), which may optionally employ encryption (HTTP Secure, HTTPS) to provide security and privacy for the user. The user's application, often a web browser, renders the page content according to its HTML markup instructions onto a display terminal.
Hyperlinking between web pages conveys to the reader the site structure and guides the navigation of the site, which often starts with a home page containing a directory of the site web content.
Some websites require user registration or subscription to access content. Examples of subscription websites include many business sites, news websites, academic journal websites, gaming websites, file-sharing websites, message boards, web-based email, social networking websites, websites providing real-time stock market data, as well as sites providing various other services. As of 2016 end users can access websites on a range of devices, including desktop and laptop computers, tablet computers, smartphones and smart TVs.
History: Main article: History of the World Wide Web
The World Wide Web (WWW) was created in 1990 by the British CERN physicist Tim Berners-Lee. On 30 April 1993, CERN announced that the World Wide Web would be free to use for anyone. Before the introduction of HTML and HTTP, other protocols such as File Transfer Protocol and the gopher protocol were used to retrieve individual files from a server. These protocols offer a simple directory structure which the user navigates and chooses files to download. Documents were most often presented as plain text files without formatting, or were encoded in word processor formats.
Overview:
Websites have many functions and can be used in various fashions; a website can be a personal website, a commercial website, a government website or a non-profit organization website. Websites can be the work of an individual, a business or other organization, and are typically dedicated to a particular topic or purpose.
Any website can contain a hyperlink to any other website, so the distinction between individual sites, as perceived by the user, can be blurred. Websites are written in, or converted to, HTML (Hyper Text Markup Language) and are accessed using a software interface classified as a user agent.
Web pages can be viewed or otherwise accessed from a range of computer-based and Internet-enabled devices of various sizes, including desktop computers, laptops, PDAs and cell phones. A website is hosted on a computer system known as a web server, also called an HTTP (Hyper Text Transfer Protocol) server.
These terms can also refer to the software that runs on these systems which retrieves and delivers the web pages in response to requests from the website's users. Apache is the most commonly used web server software (according to Netcraft statistics) and Microsoft's IIS is also commonly used. Some alternatives, such as Nginx, Lighttpd, Hiawatha or Cherokee, are fully functional and lightweight.
Static Website: Main article: Static web page
A static website is one that has web pages stored on the server in the format that is sent to a client web browser. It is primarily coded in Hypertext Markup Language (HTML); Cascading Style Sheets (CSS) are used to control appearance beyond basic HTML. Images are commonly used to effect the desired appearance and as part of the main content. Audio or video might also be considered "static" content if it plays automatically or is generally non-interactive.
This type of website usually displays the same information to all visitors. Similar to handing out a printed brochure to customers or clients, a static website will generally provide consistent, standard information for an extended period of time. Although the website owner may make updates periodically, it is a manual process to edit the text, photos and other content and may require basic website design skills and software.
Simple forms or marketing examples of websites, such as classic website, a five-page website or a brochure website are often static websites, because they present pre-defined, static information to the user. This may include information about a company and its products and services through text, photos, animations, audio/video, and navigation menus.
Static websites can be edited using four broad categories of software:
- Text editors, such as Notepad or TextEdit, where content and HTML markup are manipulated directly within the editor program
- WYSIWYG offline editors, such as Microsoft FrontPage and Adobe Dreamweaver (previously Macromedia Dreamweaver), with which the site is edited using a GUI and the final HTML markup is generated automatically by the editor software
- WYSIWYG online editors which create media rich online presentation like web pages, widgets, intro, blogs, and other documents.
- Template-based editors such as iWeb allow users to create and upload web pages to a web server without detailed HTML knowledge, as they pick a suitable template from a palette and add pictures and text to it in a desktop publishing fashion without direct manipulation of HTML code.
Static websites may still use server side includes (SSI) as an editing convenience, such as sharing a common menu bar across many pages. As the site's behaviour to the reader is still static, this is not considered a dynamic site.
Dynamic Website: Main articles: Dynamic web page and Web application
A dynamic website is one that changes or customizes itself frequently and automatically. Server-side dynamic pages are generated "on the fly" by computer code that produces the HTML (CSS are responsible for appearance and thus, are static files).
There are a wide range of software systems, such as CGI, Java Servlets and Java Server Pages (JSP), Active Server Pages and ColdFusion (CFML) that are available to generate dynamic web systems and dynamic sites. Various web application frameworks and web template systems are available for general-use programming languages like Perl, PHP, Python and Ruby to make it faster and easier to create complex dynamic websites.
A site can display the current state of a dialogue between users, monitor a changing situation, or provide information in some way personalized to the requirements of the individual user. For example, when the front page of a news site is requested, the code running on the web server might combine stored HTML fragments with news stories retrieved from a database or another website via RSS to produce a page that includes the latest information.
Dynamic sites can be interactive by using HTML forms, storing and reading back browser cookies, or by creating a series of pages that reflect the previous history of clicks. Another example of dynamic content is when a retail website with a database of media products allows a user to input a search request, e.g. for the keyword Beatles.
In response, the content of the web page will spontaneously change the way it looked before, and will then display a list of Beatles products like CDs, DVDs and books. Dynamic HTML uses JavaScript code to instruct the web browser how to interactively modify the page contents. One way to simulate a certain type of dynamic website while avoiding the performance loss of initiating the dynamic engine on a per-user or per-connection basis, is to periodically automatically regenerate a large series of static pages.
Click on any of the following blue hyperlinks for more about a Website:
- Multimedia and interactive content
- Spelling
- Types
- See also:
- Link rot
- Nanosite, a mini website
- Site map
- Web content management system
- Web design
- Web development
- Web development tools
- Web hosting service
- Web template
- Website governance
- Website monetization
- World Wide Web Consortium (Web standards)
- Internet Corporation For Assigned Names and Numbers (ICANN)
- World Wide Web Consortium (W3C)
- The Internet Society (ISOC)
Real Estate Websites including Online real estate databases
YouTube Video: Find Homes For SALE - Find EVERY Open House - RedFin, Zillow, Realtor.com - Real Estate Investing

Click here for a List of Online Real Estate Databases.
An electronic version of the real estate industry, internet real estate is the concept of publishing housing estates for sale or rent, and for consumers seeking to buy or rent a property. Often, internet real estates are operated by landlords themselves.
However, there are few exceptions where an online real estate agent would exist, still dealing via the web and often stating a flat-fee and not a commission based on percentage of total sales. Internet real estate surfaced around 1999 when technology advanced and statistics prove that more than 1 million homes were sold by the owners themselves in just America, in 2000. Some of the prime internet real estate platforms include:
According to Realtor, 90% of home buyers searched online during the process of seeking for a property and the percentage of consumers searching for information relating to real estate on Google has increased by 253% over the last 4 years. With an increase of 5.5% from just 0% of people using the internet to carry our house sales within the last decade in UK, figures show that there will be a huge increase to percentage of 50 by 2018. Figures will hit 70% by 2020, with only a third of the UK population seeking help through traditional methods of real estate agents.
The process of the concept of internet real estate usually begins with owners listing their homes with its quoted price on online platforms such as Trulia, Yahoo! Real Estate, cyberhomes, The New York Times and even eBay. The greater number of platforms owners list their properties, the greater the diffusion of information.
As buyers who are seeking for a piece of property, search engines are usually their first pit-stop. "69% of home shoppers who take action on real estate brand website begin their research with a local term, i.e "Houston homes for sale" on a search engine", reports Realtor.
Once a potential buyer contacts the seller, they would go through the details of the property – sizing, amenities, condition, and pricing, if not stated. After which, an appointment for the viewing of the property would usually be scheduled and in some cases, potential buyers may request for a refurnish of certain amenities or parts of the property.
If terms and conditions are met between both parties, the buyer would usually negotiate for the best offer if interested and a deposit may be requested by the owner. Finally, both parties will agree on a date for full payment, signing on official payment, and the handover of keys to the property.
Click on any of the following blue hyperlinks for more about Online Real Estate:
An electronic version of the real estate industry, internet real estate is the concept of publishing housing estates for sale or rent, and for consumers seeking to buy or rent a property. Often, internet real estates are operated by landlords themselves.
However, there are few exceptions where an online real estate agent would exist, still dealing via the web and often stating a flat-fee and not a commission based on percentage of total sales. Internet real estate surfaced around 1999 when technology advanced and statistics prove that more than 1 million homes were sold by the owners themselves in just America, in 2000. Some of the prime internet real estate platforms include:
- Zillow,
- Trulia,
- Yahoo! Real Estate,
- Redfin
- and Realtor.com.
According to Realtor, 90% of home buyers searched online during the process of seeking for a property and the percentage of consumers searching for information relating to real estate on Google has increased by 253% over the last 4 years. With an increase of 5.5% from just 0% of people using the internet to carry our house sales within the last decade in UK, figures show that there will be a huge increase to percentage of 50 by 2018. Figures will hit 70% by 2020, with only a third of the UK population seeking help through traditional methods of real estate agents.
The process of the concept of internet real estate usually begins with owners listing their homes with its quoted price on online platforms such as Trulia, Yahoo! Real Estate, cyberhomes, The New York Times and even eBay. The greater number of platforms owners list their properties, the greater the diffusion of information.
As buyers who are seeking for a piece of property, search engines are usually their first pit-stop. "69% of home shoppers who take action on real estate brand website begin their research with a local term, i.e "Houston homes for sale" on a search engine", reports Realtor.
Once a potential buyer contacts the seller, they would go through the details of the property – sizing, amenities, condition, and pricing, if not stated. After which, an appointment for the viewing of the property would usually be scheduled and in some cases, potential buyers may request for a refurnish of certain amenities or parts of the property.
If terms and conditions are met between both parties, the buyer would usually negotiate for the best offer if interested and a deposit may be requested by the owner. Finally, both parties will agree on a date for full payment, signing on official payment, and the handover of keys to the property.
Click on any of the following blue hyperlinks for more about Online Real Estate:
- Design
- Advantages
- Convenience
Information load and reviews
Direct communications and transactions
- Convenience
- Disadvantages
- Insufficient and inaccurate information
Copyright
Target audience
Human interaction
- Insufficient and inaccurate information
- Sustainability
- Impacts
Peer-to-Peer Lending Websites including a List of Lending Companies
YouTube Video #1: Lending Club Review - Is it a Good Investment? (by GoodFinancialCents.com)
YouTube Video #2: Is peer to peer lending safe?
Pictured: Comparing Peer-to-Peer Lending Companies by Dyer News

Click here for a List of Peer-to-Peer Lending Companies.
Peer-to-peer lending, sometimes abbreviated P2P lending, is the practice of lending money to individuals or businesses through online services that match lenders with borrowers. Since peer-to-peer lending companies offering these services generally operate online, they can run with lower overhead and provide the service more cheaply than traditional financial institutions.
As a result, lenders can earn higher returns compared to savings and investment products offered by banks, while borrowers can borrow money at lower interest rates, even after the P2P lending company has taken a fee for providing the match-making platform and credit checking the borrower.
There is the risk of the borrower defaulting on the loans taken out from peer-lending websites.
Also known as crowdlending, many peer-to-peer loans are unsecured personal loans, though some of the largest amounts are lent to businesses. Secured loans are sometimes offered by using luxury assets such as jewelry, watches, vintage cars, fine art, buildings, aircraft and other business assets as collateral. They are made to an individual, company or charity. Other forms of peer-to-peer lending include student loans, commercial and real estate loans, payday loans, as well as secured business loans, leasing, and factoring.
The interest rates can be set by lenders who compete for the lowest rate on the reverse auction model or fixed by the intermediary company on the basis of an analysis of the borrower's credit.
The lender's investment in the loan is not normally protected by any government guarantee.
On some services, lenders mitigate the risk of bad debt by choosing which borrowers to lend to, and mitigate total risk by diversifying their investments among different borrowers. Other models involve the P2P lending company maintaining a separate, ringfenced fund, such as RateSetter's Provision Fund, which pays lenders back in the event the borrower defaults, but the value of such provision funds for lenders is subject to debate.
The lending intermediaries are for-profit businesses; they generate revenue by collecting a one-time fee on funded loans from borrowers and by assessing a loan servicing fee to investors (tax-disadvantaged in the UK vs charging borrowers) or borrowers (either a fixed amount annually or a percentage of the loan amount). Compared to stock markets, peer-to-peer lending tends to have both less volatility and less liquidity.
Click on any of the following blue hyperlinks for more about Peer-to-Peer Lending:
Peer-to-peer lending, sometimes abbreviated P2P lending, is the practice of lending money to individuals or businesses through online services that match lenders with borrowers. Since peer-to-peer lending companies offering these services generally operate online, they can run with lower overhead and provide the service more cheaply than traditional financial institutions.
As a result, lenders can earn higher returns compared to savings and investment products offered by banks, while borrowers can borrow money at lower interest rates, even after the P2P lending company has taken a fee for providing the match-making platform and credit checking the borrower.
There is the risk of the borrower defaulting on the loans taken out from peer-lending websites.
Also known as crowdlending, many peer-to-peer loans are unsecured personal loans, though some of the largest amounts are lent to businesses. Secured loans are sometimes offered by using luxury assets such as jewelry, watches, vintage cars, fine art, buildings, aircraft and other business assets as collateral. They are made to an individual, company or charity. Other forms of peer-to-peer lending include student loans, commercial and real estate loans, payday loans, as well as secured business loans, leasing, and factoring.
The interest rates can be set by lenders who compete for the lowest rate on the reverse auction model or fixed by the intermediary company on the basis of an analysis of the borrower's credit.
The lender's investment in the loan is not normally protected by any government guarantee.
On some services, lenders mitigate the risk of bad debt by choosing which borrowers to lend to, and mitigate total risk by diversifying their investments among different borrowers. Other models involve the P2P lending company maintaining a separate, ringfenced fund, such as RateSetter's Provision Fund, which pays lenders back in the event the borrower defaults, but the value of such provision funds for lenders is subject to debate.
The lending intermediaries are for-profit businesses; they generate revenue by collecting a one-time fee on funded loans from borrowers and by assessing a loan servicing fee to investors (tax-disadvantaged in the UK vs charging borrowers) or borrowers (either a fixed amount annually or a percentage of the loan amount). Compared to stock markets, peer-to-peer lending tends to have both less volatility and less liquidity.
Click on any of the following blue hyperlinks for more about Peer-to-Peer Lending:
Spotify.Com
YouTube Video: How to Use Spotify by C/Net
Logo Pictured Below
Spotify is a music, podcast, and video streaming service, officially launched on 7 October 2008. It is developed by startup Spotify AB in Stockholm, Sweden. It provides digital rights management-protected content from record labels and media companies.
Spotify is a freemium service, meaning that basic features are free with advertisements, while additional features, including improved streaming quality and offline music downloads, are offered via paid subscriptions.
Spotify is available in most of Europe, most of the Americas, Australia, New Zealand and parts of Asia. I
Spotify is available for most modern devices, including Windows, macOS, and Linux computers, as well as iOS and Android smartphones and tablets.
Music can be browsed or searched for via various parameters, such as artist, album, genre, playlist, or record label. Users can create, edit and share playlists, share tracks on social media, and make playlists with other users. Spotify provides access to over 30 million songs. As of June 2017, it has over 140 million monthly active users, and as of July 2017, it has over 60 million paying subscribers.
Unlike physical or download sales, which pay artists a fixed price per song or album sold, Spotify pays royalties based on the number of artists' streams as a proportion of total songs streamed on the service. They distribute approximately 70% of total revenue to rights holders, who then pay artists based on their individual agreements.
Spotify has faced criticism from artists and producers including Taylor Swift and Radiohead singer Thom Yorke, who feel it does not fairly compensate music creators as music sales decline and streaming increases. In April 2017, as part of its efforts to renegotiate new license deals with record labels for a reported interest in going public,
Spotify announced that artists who are part of Universal Music Group and Merlin Network will have the ability to make their new album releases exclusively available on the service's Premium service tier for a maximum of two weeks.
For more about Spotify, click on any of the following blue hyperlinks:
Spotify is a freemium service, meaning that basic features are free with advertisements, while additional features, including improved streaming quality and offline music downloads, are offered via paid subscriptions.
Spotify is available in most of Europe, most of the Americas, Australia, New Zealand and parts of Asia. I
Spotify is available for most modern devices, including Windows, macOS, and Linux computers, as well as iOS and Android smartphones and tablets.
Music can be browsed or searched for via various parameters, such as artist, album, genre, playlist, or record label. Users can create, edit and share playlists, share tracks on social media, and make playlists with other users. Spotify provides access to over 30 million songs. As of June 2017, it has over 140 million monthly active users, and as of July 2017, it has over 60 million paying subscribers.
Unlike physical or download sales, which pay artists a fixed price per song or album sold, Spotify pays royalties based on the number of artists' streams as a proportion of total songs streamed on the service. They distribute approximately 70% of total revenue to rights holders, who then pay artists based on their individual agreements.
Spotify has faced criticism from artists and producers including Taylor Swift and Radiohead singer Thom Yorke, who feel it does not fairly compensate music creators as music sales decline and streaming increases. In April 2017, as part of its efforts to renegotiate new license deals with record labels for a reported interest in going public,
Spotify announced that artists who are part of Universal Music Group and Merlin Network will have the ability to make their new album releases exclusively available on the service's Premium service tier for a maximum of two weeks.
For more about Spotify, click on any of the following blue hyperlinks:
- Business model
- History
- 2017
- 2013–2016
- 2011–2012
- 2009–2010
- 2011–2012
- 2013–2016
- 2017
- Accounts and subscriptions
- Monetization
- Funding
- Advertisements
- Downloads
- Spotify for Artists
- Platforms
- Features
- Playlists
- Listening limitations
- Technical information
- Geographic availability
- History of expansiopm
- Early development
- Criticism
- D. A. Wallach
- Artist withdrawals
- Content withdrawals and delays
- Other criticism
Yelp(.com)
YouTube Video: Yelp CEO on site’s popularity and pitfalls
Yelp is an American multinational corporation headquartered in San Francisco, California. It develops, hosts and markets Yelp.com and the Yelp mobile app, which publish crowd-sourced reviews about local businesses, as well as the online reservation service Yelp Reservations and online food-delivery service Eat24.
The company also trains small businesses in how to respond to reviews, hosts social events for reviewers, and provides data about businesses, including health inspection scores.
Yelp was founded in 2004 by former PayPal employees Russel Simmons and Jeremy Stoppelman. Yelp grew quickly and raised several rounds of funding.
By 2010 it had $30 million in revenues and the website had published more than 4.5 million crowd-sourced reviews. From 2009 to 2012, Yelp expanded throughout Europe and Asia.
In 2009 Yelp entered several negotiations with Google for a potential acquisition. Yelp became a public company in March 2012 and became profitable for the first time two years later. As of 2016, Yelp.com has 135 million monthly visitors and 95 million reviews. The company's revenues come from businesses advertising.
According to BusinessWeek, Yelp has a complicated relationship with small businesses. Criticism of Yelp focuses on the legitimacy of reviews, public statements of Yelp manipulating and blocking reviews in order to increase ad spending, as well as concerns regarding the privacy of reviewers.
Click on any of the following blue hyperlinks for more about Yelp:
The company also trains small businesses in how to respond to reviews, hosts social events for reviewers, and provides data about businesses, including health inspection scores.
Yelp was founded in 2004 by former PayPal employees Russel Simmons and Jeremy Stoppelman. Yelp grew quickly and raised several rounds of funding.
By 2010 it had $30 million in revenues and the website had published more than 4.5 million crowd-sourced reviews. From 2009 to 2012, Yelp expanded throughout Europe and Asia.
In 2009 Yelp entered several negotiations with Google for a potential acquisition. Yelp became a public company in March 2012 and became profitable for the first time two years later. As of 2016, Yelp.com has 135 million monthly visitors and 95 million reviews. The company's revenues come from businesses advertising.
According to BusinessWeek, Yelp has a complicated relationship with small businesses. Criticism of Yelp focuses on the legitimacy of reviews, public statements of Yelp manipulating and blocking reviews in order to increase ad spending, as well as concerns regarding the privacy of reviewers.
Click on any of the following blue hyperlinks for more about Yelp:
- Company history (2004–2016)
- Origins (2004–2009)
2Private company (2009–2012)
Public entity (2012–present)
- Origins (2004–2009)
- Features
- Relationship with businesses
- Community
- See also:
Angie's List
YouTube Video: Introducing Angi | Your Home For Everything Home
Pictured: "Newly Free Angie’s List Will Increase Appeal of Small Biz Listings" by Small Business Trends

Angie's List is an American home services website. Founded in 1995, it is an online directory that allows users to read and publish crowd-sourced reviews of local businesses and contractors. Formerly a subscription-only service, Angie's List added a free membership tier in July 2016.
For the quarter ending on June 30, 2016, Angie's List reported total revenue of US$83,000,000 and a net income of US$4,797,000.
On May 1, 2017, the Wall Street Journal reported that IAC planned to buy Angie's List. The new publicly traded company would be called ANGI Homeservices Inc.
Click on any of the following blue hyperlinks for more about "Angie's List":
For the quarter ending on June 30, 2016, Angie's List reported total revenue of US$83,000,000 and a net income of US$4,797,000.
On May 1, 2017, the Wall Street Journal reported that IAC planned to buy Angie's List. The new publicly traded company would be called ANGI Homeservices Inc.
Click on any of the following blue hyperlinks for more about "Angie's List":
Pandora Radio
YouTube Video: How to Use Pandora Radio to Find the Best Music
Pictured: Pandora Website
Pandora Internet Radio (also known as Pandora Radio or simply Pandora) is a music streaming and automated music recommendation service powered by the Music Genome Project.
As of 1 August 2017, the service, operated by Pandora Media, Inc., is available only in the United States.
The service plays songs that have similar musical traits. The user then provides positive or negative feedback (as "thumbs up" or "thumbs down") for songs chosen by the service, and the feedback is taken into account in the subsequent selection of other songs to play.
The service can be accessed either through a web browser or by downloading and installing application software on the user's device such as a personal computer or mobile phone.
Click on any of the following blue hyperlinks for more about Pandora Radio:
As of 1 August 2017, the service, operated by Pandora Media, Inc., is available only in the United States.
The service plays songs that have similar musical traits. The user then provides positive or negative feedback (as "thumbs up" or "thumbs down") for songs chosen by the service, and the feedback is taken into account in the subsequent selection of other songs to play.
The service can be accessed either through a web browser or by downloading and installing application software on the user's device such as a personal computer or mobile phone.
Click on any of the following blue hyperlinks for more about Pandora Radio:
- History
- Features
- Streaming
Limitations
Mobile devices
- Streaming
- Technical information
- Business model
- Royalties
- Reception
- Advertising
- Revenue
Pitch to advertisers
Methods of advertising
Market segments
- Revenue
- Internet radio competitors
- Owned and operated stations
- See also:
- List of Internet radio stations
- List of online music databases
- Official website
- Pandora featured in Fast Company
- The Flux podcast interview with Tim Westergren, founder of Pandora
- Pandora feature on WNBC-TV
- Closing Pandora's Box: The End of Internet Radio?, May 3, 2007 interview with Tim Westergren
- Pandora adds classical music
- Interview with Tim Westergren about the Music Genome Project and Pandora
- Dave Dederer & nuTsie Challenge Pandora
- Inc. Magazine profile of Tim Westergren
- New York Times article on Tim Westergren and Pandora
- Pink Floyd: Pandora's Internet radio royalty ripoff USA TODAY, 2013
iHeartRadio
YouTube Video about iHeartRadio: Unlimited Music & Free Radio in One App

iHeartRadio is a radio network and Internet radio platform owned by iHeartMedia, Inc.
Founded in April 2008 as the website iheartmusic.com, as of 2015 iHeartRadio functions both as a music recommender system and as a radio network that aggregates audio content from over 800 local iHeartMedia radio stations across the United States, as well as from hundreds of other stations and from various other media (with companies such as Cumulus Media, Cox Radio and Beasley Broadcast Group also utilizing this service).
iHeartRadio is available online, via mobile devices, and on select video-game consoles., and was created by Mary Beth Fitzgerald.
iHeartRadio was ranked No. 4 on AdAge's Entertainment A-List in 2010.
Since 2011, they hold the iHeartRadio Music Festival.
In 2014, iHeartRadio started an awards show titled iHeartRadio Music Awards and regularly produces concerts in Los Angeles and New York though the iHeartRadio Theater locations.
Click on any of the following blue hyperlinks for more about iHeartRadio:
Founded in April 2008 as the website iheartmusic.com, as of 2015 iHeartRadio functions both as a music recommender system and as a radio network that aggregates audio content from over 800 local iHeartMedia radio stations across the United States, as well as from hundreds of other stations and from various other media (with companies such as Cumulus Media, Cox Radio and Beasley Broadcast Group also utilizing this service).
iHeartRadio is available online, via mobile devices, and on select video-game consoles., and was created by Mary Beth Fitzgerald.
iHeartRadio was ranked No. 4 on AdAge's Entertainment A-List in 2010.
Since 2011, they hold the iHeartRadio Music Festival.
In 2014, iHeartRadio started an awards show titled iHeartRadio Music Awards and regularly produces concerts in Los Angeles and New York though the iHeartRadio Theater locations.
Click on any of the following blue hyperlinks for more about iHeartRadio:
- History
- Availability and supported devices
- Mobile
Home
Automotive
Wearables
- Mobile
- Functionality and rating system
- Limitations
- See also:
Internet Privacy and the Right to Privacy including Repeal of the FCC Privacy Rules (as reported by the Washington Post April 4, 2017)
YouTube Video about the Right to Privacy on the Internet*
* -- As reported by CBS News, 24-year-old Ashley Payne was forced to resign from her position as a public high school teacher when a student allegedly complained over a Facebook photo of Payne holding alcoholic beverages claiming it promoted drinking. 48 Hours' Erin Moriarty investigates our ever changing rights to privacy.
Trump has signed repeal of the FCC privacy rules. Here’s what happens next. (by Brian Fung of The Washington Post April 4, 2017)
"President Trump signed congressional legislation Monday night that repeals the Federal Communications Commission's privacy protections for Internet users, rolling back a landmark policy from the Obama era and enabling Internet providers to compete with Google and Facebook in the online ad market.The Obama-backed rules — which would have taken effect later this year — would have banned Internet providers from collecting, storing, sharing and selling certain types of customer information without user consent.
Data such as a consumer's Web browsing history, app usage history, location details and more would have required a customer's explicit permission before companies such as Verizon and Comcast could mine the information for advertising purposes.
Evan Greer, campaign director for the Internet activism group Fight for the Future, condemned the move, saying it was “deeply ironic” for Trump to sign the legislation while complaining about the privacy of his own communications in connection with the FBI's probe into his campaign's possible links with Russia.
The only people in the United States who want less Internet privacy are CEOs and lobbyists for giant telecom companies, who want to rake in money by spying on all of us and selling the private details of our lives to marketing companies,” said Greer.
Trump signed the legislation with little fanfare Monday evening, a contrast to other major executive actions he has taken from the Oval Office. The move prohibits the FCC from passing similar privacy regulations in the future. And it paves the way for Internet providers to compete in the $83 billion market for digital advertising.
By watching where their customers go online, providers may understand more about their users' Internet habits and present those findings to third parties. While companies such as Comcast have pledged not to sell the data of individual customers, those commitments are voluntary and as a result of Trump's signature, not backed by federal regulation.
Trump's FCC chairman, Ajit Pai, said the Federal Trade Commission, not the FCC, should regulate Internet providers' data-mining practices. “American consumers’ privacy deserves to be protected regardless of who handles their personal information,” he said in a statement Monday evening.
The FTC currently has guidelines for how companies such as Google and Facebook may use customers' information. Those websites are among the world's biggest online advertisers, and Internet providers are eager to gain a slice of their market share. But critics of the FCC privacy rules argued that the regulations placed stricter requirements on broadband companies than on tech firms, creating an imbalance that could only be resolved by rolling back the FCC rules and designing something new.
The FTC is empowered to bring lawsuits against companies that violate its privacy guidelines, but it has no authority to create new rules for industry. It also currently cannot enforce its own guidelines against Internet providers due to a government rule that places those types of companies squarely within the jurisdiction of the FCC and out of the reach of the FTC.
As a result, Internet providers now exist in a “policy gap” in which the only privacy regulators for the industry operate at the state, not federal, level, analysts say. They add that policymakers are likely to focus next on how to resolve that contradiction as well as look for ways to undo net neutrality, another Obama-era initiative that bans Internet providers from discriminating against websites."
END of Washington Post Article.
___________________________________________________________________________
Internet privacy involves the right or mandate of personal privacy concerning the storing, re-purposing, provision to third parties, and displaying of information pertaining to oneself via of the Internet.
Internet privacy is a subset of data privacy. Privacy concerns have been articulated from the beginnings of large scale computer sharing.
Privacy can entail either Personally Identifying Information (PII) or non-PII information such as a site visitor's behavior on a website. PII refers to any information that can be used to identify an individual. For example, age and physical address alone could identify who an individual is without explicitly disclosing their name, as these two factors are unique enough to typically identify a specific person.
Some experts such as Steve Rambam, a private investigator specializing in Internet privacy cases, believe that privacy no longer exists; saying, "Privacy is dead – get over it". In fact, it has been suggested that the "appeal of online services is to broadcast personal information on purpose."
On the other hand, in his essay The Value of Privacy, security expert Bruce Schneier says, "Privacy protects us from abuses by those in power, even if we're doing nothing wrong at the time of surveillance."
Levels of Privacy:
Internet and digital privacy are viewed differently from traditional expectations of privacy. Internet privacy is primarily concerned with protecting user information.
Law Professor Jerry Kang explains that the term privacy expresses space, decision, and information. In terms of space, individuals have an expectation that their physical spaces (i.e. homes, cars) not be intruded. Privacy within the realm of decision is best illustrated by the landmark case Roe v. Wade. Lastly, information privacy is in regards to the collection of user information from a variety of sources, which produces great discussion.
The 1997 Information Infrastructure Task Force (IITF) created under President Clinton defined information privacy as "an individual's claim to control the terms under which personal information--information identifiable to the individual--is acquired, disclosed, and used."
At the end of the 1990s, with the rise of the Internet, it became clear that the internet and companies would need to abide by new rules to protect individual's privacy. With the rise of the internet and mobile networks the salience of internet privacy is a daily concern for users.
People with only a casual concern for Internet privacy need not achieve total anonymity. Internet users may protect their privacy through controlled disclosure of personal information.
The revelation of IP addresses, non-personally-identifiable profiling, and similar information might become acceptable trade-offs for the convenience that users could otherwise lose using the workarounds needed to suppress such details rigorously.
On the other hand, some people desire much stronger privacy. In that case, they may try to achieve Internet anonymity to ensure privacy — use of the Internet without giving any third parties the ability to link the Internet activities to personally-identifiable information of the Internet user. In order to keep their information private, people need to be careful with what they submit to and look at online.
When filling out forms and buying merchandise, that becomes tracked and because the information was not private, some companies are now sending Internet users spam and advertising on similar products.
There are also several governmental organizations that protect individual's privacy and anonymity on the Internet, to a point. In an article presented by the FTC, in October 2011, a number of pointers were brought to attention that helps an individual internet user avoid possible identity theft and other cyber-attacks.
Preventing or limiting the usage of Social Security numbers online, being wary and respectful of emails including spam messages, being mindful of personal financial details, creating and managing strong passwords, and intelligent web-browsing behaviours are recommended, among others.
Posting things on the Internet can be harmful or in danger of malicious attack. Some information posted on the Internet is permanent, depending on the terms of service, and privacy policies of particular services offered online.
This can include comments written on blogs, pictures, and Internet sites, such as Facebook and Twitter. It is absorbed into cyberspace and once it is posted, anyone can potentially find it and access it. Some employers may research a potential employee by searching online for the details of their online behaviors, possibly affecting the outcome of the success of the candidate.
Risks to Internet Privacy:
Companies are hired to watch what internet sites people visit, and then use the information, for instance by sending advertising based on one's browsing history. There are many ways in which people can divulge their personal information, for instance by use of "social media" and by sending bank and credit card information to various websites.
Moreover, directly observed behavior, such as browsing logs, search queries, or contents of the Facebook profile can be automatically processed to infer potentially more intrusive details about an individual, such as sexual orientation, political and religious views, race, substance use, intelligence, and personality.
Those concerned about Internet privacy often cite a number of privacy risks — events that can compromise privacy — which may be encountered through Internet use. These range from the gathering of statistics on users to more malicious acts such as the spreading of spyware and the exploitation of various forms of bugs (software faults).
Several social networking sites try to protect the personal information of their subscribers. On Facebook, for example, privacy settings are available to all registered users: they can block certain individuals from seeing their profile, they can choose their "friends", and they can limit who has access to one's pictures and videos. Privacy settings are also available on other social networking sites such as Google Plus and Twitter. The user can apply such settings when providing personal information on the internet.
In late 2007 Facebook launched the Beacon program where user rental records were released on the public for friends to see. Many people were enraged by this breach in privacy, and the Lane v. Facebook, Inc. case ensued.
Children and adolescents often use the Internet (including social media) in ways which risk their privacy: a cause for growing concern among parents. Young people also may not realise that all their information and browsing can and may be tracked while visiting a particular site, and that it is up to them to protect their own privacy. They must be informed about all these risks.
For example, on Twitter, threats include shortened links that lead one to potentially harmful places. In their e-mail inbox, threats include email scams and attachments that get them to install malware and disclose personal information.
On Torrent sites, threats include malware hiding in video, music, and software downloads. Even when using a smartphone, threats include geolocation, meaning that one's phone can detect where they are and post it online for all to see. Users can protect themselves by updating virus protection, using security settings, downloading patches, installing a firewall, screening e-mail, shutting down spyware, controlling cookies, using encryption, fending off browser hijackers, and blocking pop-ups.
However most people have little idea how to go about doing many of these things. How can the average user with no training be expected to know how to run their own network security (especially as things are getting more complicated all the time)? Many businesses hire professionals to take care of these issues, but most individuals can only do their best to learn about all this.
In 1998, the Federal Trade Commission in the USA considered the lack of privacy for children on the Internet, and created the Children Online Privacy Protection Act (COPPA). COPPA limits the options which gather information from children and created warning labels if potential harmful information or content was presented.
In 2000, Children's Internet Protection Act (CIPA) was developed to implement safe Internet policies such as rules, and filter software. These laws, awareness campaigns, parental and adult supervision strategies and Internet filters can all help to make the Internet safer for children around the world.
Click on any of the following blue hyperlinks for more about Internet Privacy:
The right to privacy is an element of various legal traditions to restrain government and private actions that threaten the privacy of individuals. Over 150 national constitutions mention the right to privacy.
Since the global surveillance disclosures of 2013, the inalienable human right to privacy has been a subject of international debate.
In combating worldwide terrorism, government agencies, such as the NSA, CIA, R&AW, and GCHQ have engaged in mass, global surveillance, perhaps undermining the right to privacy.
There is now a question as to whether the right to privacy can co-exist with the current capabilities of intelligence agencies to access and analyse virtually every detail of an individual's life. A major question is whether or not the right to privacy needs to be forfeited as part of the social contract to bolster defense against supposed terrorist threats.
Click on any of the following blue hyperlinks for more about the Right to Privacy:
"President Trump signed congressional legislation Monday night that repeals the Federal Communications Commission's privacy protections for Internet users, rolling back a landmark policy from the Obama era and enabling Internet providers to compete with Google and Facebook in the online ad market.The Obama-backed rules — which would have taken effect later this year — would have banned Internet providers from collecting, storing, sharing and selling certain types of customer information without user consent.
Data such as a consumer's Web browsing history, app usage history, location details and more would have required a customer's explicit permission before companies such as Verizon and Comcast could mine the information for advertising purposes.
Evan Greer, campaign director for the Internet activism group Fight for the Future, condemned the move, saying it was “deeply ironic” for Trump to sign the legislation while complaining about the privacy of his own communications in connection with the FBI's probe into his campaign's possible links with Russia.
The only people in the United States who want less Internet privacy are CEOs and lobbyists for giant telecom companies, who want to rake in money by spying on all of us and selling the private details of our lives to marketing companies,” said Greer.
Trump signed the legislation with little fanfare Monday evening, a contrast to other major executive actions he has taken from the Oval Office. The move prohibits the FCC from passing similar privacy regulations in the future. And it paves the way for Internet providers to compete in the $83 billion market for digital advertising.
By watching where their customers go online, providers may understand more about their users' Internet habits and present those findings to third parties. While companies such as Comcast have pledged not to sell the data of individual customers, those commitments are voluntary and as a result of Trump's signature, not backed by federal regulation.
Trump's FCC chairman, Ajit Pai, said the Federal Trade Commission, not the FCC, should regulate Internet providers' data-mining practices. “American consumers’ privacy deserves to be protected regardless of who handles their personal information,” he said in a statement Monday evening.
The FTC currently has guidelines for how companies such as Google and Facebook may use customers' information. Those websites are among the world's biggest online advertisers, and Internet providers are eager to gain a slice of their market share. But critics of the FCC privacy rules argued that the regulations placed stricter requirements on broadband companies than on tech firms, creating an imbalance that could only be resolved by rolling back the FCC rules and designing something new.
The FTC is empowered to bring lawsuits against companies that violate its privacy guidelines, but it has no authority to create new rules for industry. It also currently cannot enforce its own guidelines against Internet providers due to a government rule that places those types of companies squarely within the jurisdiction of the FCC and out of the reach of the FTC.
As a result, Internet providers now exist in a “policy gap” in which the only privacy regulators for the industry operate at the state, not federal, level, analysts say. They add that policymakers are likely to focus next on how to resolve that contradiction as well as look for ways to undo net neutrality, another Obama-era initiative that bans Internet providers from discriminating against websites."
END of Washington Post Article.
___________________________________________________________________________
Internet privacy involves the right or mandate of personal privacy concerning the storing, re-purposing, provision to third parties, and displaying of information pertaining to oneself via of the Internet.
Internet privacy is a subset of data privacy. Privacy concerns have been articulated from the beginnings of large scale computer sharing.
Privacy can entail either Personally Identifying Information (PII) or non-PII information such as a site visitor's behavior on a website. PII refers to any information that can be used to identify an individual. For example, age and physical address alone could identify who an individual is without explicitly disclosing their name, as these two factors are unique enough to typically identify a specific person.
Some experts such as Steve Rambam, a private investigator specializing in Internet privacy cases, believe that privacy no longer exists; saying, "Privacy is dead – get over it". In fact, it has been suggested that the "appeal of online services is to broadcast personal information on purpose."
On the other hand, in his essay The Value of Privacy, security expert Bruce Schneier says, "Privacy protects us from abuses by those in power, even if we're doing nothing wrong at the time of surveillance."
Levels of Privacy:
Internet and digital privacy are viewed differently from traditional expectations of privacy. Internet privacy is primarily concerned with protecting user information.
Law Professor Jerry Kang explains that the term privacy expresses space, decision, and information. In terms of space, individuals have an expectation that their physical spaces (i.e. homes, cars) not be intruded. Privacy within the realm of decision is best illustrated by the landmark case Roe v. Wade. Lastly, information privacy is in regards to the collection of user information from a variety of sources, which produces great discussion.
The 1997 Information Infrastructure Task Force (IITF) created under President Clinton defined information privacy as "an individual's claim to control the terms under which personal information--information identifiable to the individual--is acquired, disclosed, and used."
At the end of the 1990s, with the rise of the Internet, it became clear that the internet and companies would need to abide by new rules to protect individual's privacy. With the rise of the internet and mobile networks the salience of internet privacy is a daily concern for users.
People with only a casual concern for Internet privacy need not achieve total anonymity. Internet users may protect their privacy through controlled disclosure of personal information.
The revelation of IP addresses, non-personally-identifiable profiling, and similar information might become acceptable trade-offs for the convenience that users could otherwise lose using the workarounds needed to suppress such details rigorously.
On the other hand, some people desire much stronger privacy. In that case, they may try to achieve Internet anonymity to ensure privacy — use of the Internet without giving any third parties the ability to link the Internet activities to personally-identifiable information of the Internet user. In order to keep their information private, people need to be careful with what they submit to and look at online.
When filling out forms and buying merchandise, that becomes tracked and because the information was not private, some companies are now sending Internet users spam and advertising on similar products.
There are also several governmental organizations that protect individual's privacy and anonymity on the Internet, to a point. In an article presented by the FTC, in October 2011, a number of pointers were brought to attention that helps an individual internet user avoid possible identity theft and other cyber-attacks.
Preventing or limiting the usage of Social Security numbers online, being wary and respectful of emails including spam messages, being mindful of personal financial details, creating and managing strong passwords, and intelligent web-browsing behaviours are recommended, among others.
Posting things on the Internet can be harmful or in danger of malicious attack. Some information posted on the Internet is permanent, depending on the terms of service, and privacy policies of particular services offered online.
This can include comments written on blogs, pictures, and Internet sites, such as Facebook and Twitter. It is absorbed into cyberspace and once it is posted, anyone can potentially find it and access it. Some employers may research a potential employee by searching online for the details of their online behaviors, possibly affecting the outcome of the success of the candidate.
Risks to Internet Privacy:
Companies are hired to watch what internet sites people visit, and then use the information, for instance by sending advertising based on one's browsing history. There are many ways in which people can divulge their personal information, for instance by use of "social media" and by sending bank and credit card information to various websites.
Moreover, directly observed behavior, such as browsing logs, search queries, or contents of the Facebook profile can be automatically processed to infer potentially more intrusive details about an individual, such as sexual orientation, political and religious views, race, substance use, intelligence, and personality.
Those concerned about Internet privacy often cite a number of privacy risks — events that can compromise privacy — which may be encountered through Internet use. These range from the gathering of statistics on users to more malicious acts such as the spreading of spyware and the exploitation of various forms of bugs (software faults).
Several social networking sites try to protect the personal information of their subscribers. On Facebook, for example, privacy settings are available to all registered users: they can block certain individuals from seeing their profile, they can choose their "friends", and they can limit who has access to one's pictures and videos. Privacy settings are also available on other social networking sites such as Google Plus and Twitter. The user can apply such settings when providing personal information on the internet.
In late 2007 Facebook launched the Beacon program where user rental records were released on the public for friends to see. Many people were enraged by this breach in privacy, and the Lane v. Facebook, Inc. case ensued.
Children and adolescents often use the Internet (including social media) in ways which risk their privacy: a cause for growing concern among parents. Young people also may not realise that all their information and browsing can and may be tracked while visiting a particular site, and that it is up to them to protect their own privacy. They must be informed about all these risks.
For example, on Twitter, threats include shortened links that lead one to potentially harmful places. In their e-mail inbox, threats include email scams and attachments that get them to install malware and disclose personal information.
On Torrent sites, threats include malware hiding in video, music, and software downloads. Even when using a smartphone, threats include geolocation, meaning that one's phone can detect where they are and post it online for all to see. Users can protect themselves by updating virus protection, using security settings, downloading patches, installing a firewall, screening e-mail, shutting down spyware, controlling cookies, using encryption, fending off browser hijackers, and blocking pop-ups.
However most people have little idea how to go about doing many of these things. How can the average user with no training be expected to know how to run their own network security (especially as things are getting more complicated all the time)? Many businesses hire professionals to take care of these issues, but most individuals can only do their best to learn about all this.
In 1998, the Federal Trade Commission in the USA considered the lack of privacy for children on the Internet, and created the Children Online Privacy Protection Act (COPPA). COPPA limits the options which gather information from children and created warning labels if potential harmful information or content was presented.
In 2000, Children's Internet Protection Act (CIPA) was developed to implement safe Internet policies such as rules, and filter software. These laws, awareness campaigns, parental and adult supervision strategies and Internet filters can all help to make the Internet safer for children around the world.
Click on any of the following blue hyperlinks for more about Internet Privacy:
- HTTP cookies
- Flash cookies
- Evercookies
- Anti-fraud uses
Advertising uses
Criticism
- Anti-fraud uses
- Device fingerprinting
- Search engines
- Public views including Concerns of Internet privacy and real life implications
- Laws and regulations
- Legal threats
- See also:
- Anonymity
- Anonymous blogging
Anonymous P2P
Anonymous post
Anonymous remailer
Anonymous web browsing
- Anonymous blogging
- Index of Articles Relating to Terms of Service and Privacy Policies
- Internet censorship including Internet censorship circumvention
- Internet vigilantism
- Privacy-enhancing technologies
- PRISM
- Privacy law
- Surveillance
- Unauthorized access in online social networks
- PrivacyTools.io - Provides knowledge and tools to protect your privacy against global mass surveillance
- Activist Net Privacy - Curated list of interviews of individuals at the forefront of the privacy debate
- Electronic Frontier Foundation - an organization devoted to privacy and intellectual freedom advocacy
- Expectation of privacy for company email not deemed objectively reasonable – Bourke v. Nissan
- Internet Privacy: The Views of the FTC, the FCC, and NTIA: Joint Hearing before the Subcommittee on Commerce, Manufacturing, and Trade and the Subcommittee on Communications and Technology of the Committee on Energy and Commerce, House of Representatives, One Hundred Twelfth Congress, First Session, July 14, 2011
- Anonymity
The right to privacy is an element of various legal traditions to restrain government and private actions that threaten the privacy of individuals. Over 150 national constitutions mention the right to privacy.
Since the global surveillance disclosures of 2013, the inalienable human right to privacy has been a subject of international debate.
In combating worldwide terrorism, government agencies, such as the NSA, CIA, R&AW, and GCHQ have engaged in mass, global surveillance, perhaps undermining the right to privacy.
There is now a question as to whether the right to privacy can co-exist with the current capabilities of intelligence agencies to access and analyse virtually every detail of an individual's life. A major question is whether or not the right to privacy needs to be forfeited as part of the social contract to bolster defense against supposed terrorist threats.
Click on any of the following blue hyperlinks for more about the Right to Privacy:
- Background
- Definitions
An individual right
A collective value and a human right
Universal Declaration of Human Rights
- Definitions
- United States
- Journalism
- Mass surveillance and privacy
- Support
- Opposition
- See also:
- Bank Secrecy Act, a US law requiring banks to disclose details of financial transactions
- Right to be forgotten
- Moore, Adam D. Privacy Rights: Moral and Legal Foundations (Pennsylvania State University Press, August 2010). ISBN 978-0-271-03686-1.
- "The Privacy Torts" (December 19, 2000). Privacilla.org, a "web-based think tank", devoted to privacy issues, edited by Jim Harper ("About Privacilla")
WebMD
YouTube Video: What Is a Spleen and What Does it Do?
YouTube Video: Advances in Liver Transplant Surgery
Pictured: Giada De Laurentiis, WebMD Editor-in-Chief Kristy Hammam, WebMD CEO David Schlanger, Robin Roberts and WebMD President Steve Zatz at WebMD's first-ever Digital Content NewFront presentation in New York City.

WebMD is an American corporation known primarily as an online publisher of news and information pertaining to human health and well-being. It was founded in 1996 by James H. Clark and Pavan Nigam as Healthscape, later Healtheon, and then it acquired WebMD in 1999 to form Healtheon/WebMD. The name was later shortened to WebMD.
Website Traffic:
WebMD is best known as a health information services website, which publishes content regarding health and health care topics, including a symptom checklist, pharmacy information, drugs information, blogs of physicians with specific topics, and providing a place to store personal medical information.
During 2015, WebMD’s network of websites reached more unique visitors each month than any other leading private or government healthcare website, making it the leading health publisher in the United States. In the fourth quarter of 2016, WebMD recorded an average of 179.5 million unique users per month, and 3.63 billion page views per quarter.
Accreditation:
URAC, the Utilization Review Accreditation Commission, has accredited WebMD’s operations continuously since 2001 regarding everything from proper disclosures and health content to security and privacy.
Click on any of the following blue hyperlinks for more about the website WebMD:
Website Traffic:
WebMD is best known as a health information services website, which publishes content regarding health and health care topics, including a symptom checklist, pharmacy information, drugs information, blogs of physicians with specific topics, and providing a place to store personal medical information.
During 2015, WebMD’s network of websites reached more unique visitors each month than any other leading private or government healthcare website, making it the leading health publisher in the United States. In the fourth quarter of 2016, WebMD recorded an average of 179.5 million unique users per month, and 3.63 billion page views per quarter.
Accreditation:
URAC, the Utilization Review Accreditation Commission, has accredited WebMD’s operations continuously since 2001 regarding everything from proper disclosures and health content to security and privacy.
Click on any of the following blue hyperlinks for more about the website WebMD:
- Revenues
- Business model
- Criticism
- See also:
- WebMD (corporate website)
- WebMD Health (consumer website)
- Medscape (physician website)
- MedicineNet (MedicineNet website)
- RxList (drugs and medications website)
- eMedicineHealth (consumer first aid and health information website)
- Boots WebMD (UK consumer website)
- WebMD Health Services (private portal website)
Crowdsourcing*
* - [Note that while Crowdsourcing does not apply to just the Internet, it is the ability to use Internet-based Crowdsourcing technology that has caught on so well, per the examples below.]
YouTube Video: Mindsharing, the art of crowdsourcing everything | TED Talks
Pictured: Example of Crowdsourcing Process in Graphic Design
Crowdsourcing is a specific sourcing model in which individuals or organizations use contributions from Internet users to obtain needed services or ideas.
Crowdsourcing was coined in 2005 as a portmanteau of crowd and outsourcing.This mode of sourcing, which is to divide work between participants to achieve a cumulative result, was already successful prior to the digital age (i.e., "offline").
Crowdsourcing is distinguished from outsourcing in that the work can come from an undefined public (instead of being commissioned from a specific, named group) and in that crowdsourcing includes a mix of bottom-up and top-down processes.
Advantages of using crowdsourcing may include improved costs, speed, quality, flexibility, scalability, or diversity. Crowdsourcing in the form of idea competitions or innovation contests provides a way for organizations to learn beyond what their "base of minds" of employees provides (e.g., LEGO Ideas).
Crowdsourcing can also involve rather tedious "microtasks" that are performed in parallel by large, paid crowds (e.g., Amazon Mechanical Turk). Crowdsourcing has also been used for noncommercial work and to develop common goods (e.g., Wikipedia). The affect of user communication and the platform presentation should be taken into account when evaluating the performance of ideas in crowdsourcing contexts.
The term "crowdsourcing" was coined in 2005 by Jeff Howe and Mark Robinson, editors at Wired, to describe how businesses were using the Internet to "outsource work to the crowd", which quickly led to the portmanteau "crowdsourcing."
Howe first published a definition for the term crowdsourcing in a companion blog post to his June 2006 Wired article, "The Rise of Crowdsourcing", which came out in print just days later:
"Simply defined, crowdsourcing represents the act of a company or institution taking a function once performed by employees and outsourcing it to an undefined (and generally large) network of people in the form of an open call. This can take the form of peer-production (when the job is performed collaboratively), but is also often undertaken by sole individuals. The crucial prerequisite is the use of the open call format and the large network of potential laborers."
In a February 1, 2008, article, Daren C. Brabham, "the first [person] to publish scholarly research using the word crowdsourcing" and writer of the 2013 book, Crowdsourcing, defined it as an "online, distributed problem-solving and production model."
Kristen L. Guth and Brabham found that the performance of ideas offered in crowdsourcing platforms are affected not only by their quality, but also by the communication among users about the ideas, and presentation in the platform itself.
After studying more than 40 definitions of crowdsourcing in the scientific and popular literature, Enrique Estellés-Arolas and Fernando González Ladrón-de-Guevara, researchers at the Technical University of Valencia, developed a new integrating definition:
"Crowdsourcing is a type of participatory online activity in which an individual, an institution, a nonprofit organization, or company proposes to a group of individuals of varying knowledge, heterogeneity, and number, via a flexible open call, the voluntary undertaking of a task. The undertaking of the task; of variable complexity and modularity, and; in which the crowd should participate, bringing their work, money, knowledge **[and/or]** experience, always entails mutual benefit. The user will receive the satisfaction of a given type of need, be it economic, social recognition, self-esteem, or the development of individual skills, while the crowdsourcer will obtain and use to their advantage that which the user has brought to the venture, whose form will depend on the type of activity undertaken".
As mentioned by the definitions of Brabham and Estellés-Arolas and Ladrón-de-Guevara above, crowdsourcing in the modern conception is an IT-mediated phenomenon, meaning that a form of IT is always used to create and access crowds of people. In this respect, crowdsourcing has been considered to encompass three separate, but stable techniques:
Henk van Ess, a college lecturer in online communications, emphasizes the need to "give back" the crowdsourced results to the public on ethical grounds. His nonscientific, noncommercial definition is widely cited in the popular press: "Crowdsourcing is channeling the experts’ desire to solve a problem and then freely sharing the answer with everyone."
Despite the multiplicity of definitions for crowdsourcing, one constant has been the broadcasting of problems to the public, and an open call for contributions to help solve the problem. Members of the public submit solutions that are then owned by the entity, which originally broadcast the problem.
In some cases, the contributor of the solution is compensated monetarily with prizes or with recognition. In other cases, the only rewards may be a kudos or intellectual satisfaction. Crowdsourcing may produce solutions from amateurs or volunteers working in their spare time or from experts or small businesses, which were previously unknown to the initiating organization.
Another consequence of the multiple definitions is the controversy surrounding what kinds of activities that may be considered crowdsourcing.
Click on any of the following blue hyperlinks for more about Crowdsourcing:
Crowdsourcing was coined in 2005 as a portmanteau of crowd and outsourcing.This mode of sourcing, which is to divide work between participants to achieve a cumulative result, was already successful prior to the digital age (i.e., "offline").
Crowdsourcing is distinguished from outsourcing in that the work can come from an undefined public (instead of being commissioned from a specific, named group) and in that crowdsourcing includes a mix of bottom-up and top-down processes.
Advantages of using crowdsourcing may include improved costs, speed, quality, flexibility, scalability, or diversity. Crowdsourcing in the form of idea competitions or innovation contests provides a way for organizations to learn beyond what their "base of minds" of employees provides (e.g., LEGO Ideas).
Crowdsourcing can also involve rather tedious "microtasks" that are performed in parallel by large, paid crowds (e.g., Amazon Mechanical Turk). Crowdsourcing has also been used for noncommercial work and to develop common goods (e.g., Wikipedia). The affect of user communication and the platform presentation should be taken into account when evaluating the performance of ideas in crowdsourcing contexts.
The term "crowdsourcing" was coined in 2005 by Jeff Howe and Mark Robinson, editors at Wired, to describe how businesses were using the Internet to "outsource work to the crowd", which quickly led to the portmanteau "crowdsourcing."
Howe first published a definition for the term crowdsourcing in a companion blog post to his June 2006 Wired article, "The Rise of Crowdsourcing", which came out in print just days later:
"Simply defined, crowdsourcing represents the act of a company or institution taking a function once performed by employees and outsourcing it to an undefined (and generally large) network of people in the form of an open call. This can take the form of peer-production (when the job is performed collaboratively), but is also often undertaken by sole individuals. The crucial prerequisite is the use of the open call format and the large network of potential laborers."
In a February 1, 2008, article, Daren C. Brabham, "the first [person] to publish scholarly research using the word crowdsourcing" and writer of the 2013 book, Crowdsourcing, defined it as an "online, distributed problem-solving and production model."
Kristen L. Guth and Brabham found that the performance of ideas offered in crowdsourcing platforms are affected not only by their quality, but also by the communication among users about the ideas, and presentation in the platform itself.
After studying more than 40 definitions of crowdsourcing in the scientific and popular literature, Enrique Estellés-Arolas and Fernando González Ladrón-de-Guevara, researchers at the Technical University of Valencia, developed a new integrating definition:
"Crowdsourcing is a type of participatory online activity in which an individual, an institution, a nonprofit organization, or company proposes to a group of individuals of varying knowledge, heterogeneity, and number, via a flexible open call, the voluntary undertaking of a task. The undertaking of the task; of variable complexity and modularity, and; in which the crowd should participate, bringing their work, money, knowledge **[and/or]** experience, always entails mutual benefit. The user will receive the satisfaction of a given type of need, be it economic, social recognition, self-esteem, or the development of individual skills, while the crowdsourcer will obtain and use to their advantage that which the user has brought to the venture, whose form will depend on the type of activity undertaken".
As mentioned by the definitions of Brabham and Estellés-Arolas and Ladrón-de-Guevara above, crowdsourcing in the modern conception is an IT-mediated phenomenon, meaning that a form of IT is always used to create and access crowds of people. In this respect, crowdsourcing has been considered to encompass three separate, but stable techniques:
- competition crowdsourcing,
- virtual labor market crowdsourcing,
- and open collaboration crowdsourcing.
Henk van Ess, a college lecturer in online communications, emphasizes the need to "give back" the crowdsourced results to the public on ethical grounds. His nonscientific, noncommercial definition is widely cited in the popular press: "Crowdsourcing is channeling the experts’ desire to solve a problem and then freely sharing the answer with everyone."
Despite the multiplicity of definitions for crowdsourcing, one constant has been the broadcasting of problems to the public, and an open call for contributions to help solve the problem. Members of the public submit solutions that are then owned by the entity, which originally broadcast the problem.
In some cases, the contributor of the solution is compensated monetarily with prizes or with recognition. In other cases, the only rewards may be a kudos or intellectual satisfaction. Crowdsourcing may produce solutions from amateurs or volunteers working in their spare time or from experts or small businesses, which were previously unknown to the initiating organization.
Another consequence of the multiple definitions is the controversy surrounding what kinds of activities that may be considered crowdsourcing.
Click on any of the following blue hyperlinks for more about Crowdsourcing:
- Historical examples
- Modern methods
- Examples
- Crowdvoting
- Crowdsourcing creative work
- Crowdsourcing language-related data collection
- Crowdsolving
- Crowdsearching
- Crowdfunding
- Mobile crowdsourcing
- Macrowork
- Microwork
- Simple projects
- Complex projects
- Inducement prize contests
- Implicit crowdsourcing
- Health-care crowdsourcing
- Crowdsourcing in agriculture
- Crowdsourcing in cheating in bridge
- Crowdsourcers
- Limitations and controversies
- See also:
- Citizen science
- Clickworkers
- Collaborative innovation network
- Collective consciousness
- Collective intelligence
- Collective problem solving
- Commons-based peer production
- Crowd computing
- Crowdcasting
- Crowdfixing
- Crowdsourcing software development
- Distributed thinking
- Distributed Proofreaders
- Flash mob
- Gamification
- Government crowdsourcing
- List of crowdsourcing projects
- Microcredit
- Participatory democracy
- Participatory monitoring
- Smart mob
- Social collaboration
- "Stone Soup"
- TrueCaller
- Virtual Collective Consciousness
- Virtual volunteering
- Wisdom of the crowd
Online Encyclopedias including a List of Online Encyclopedias
YouTube Video: Is Wikipedia a Credible Source?
Pictured (L-R): Wikipedia and Fortune Online Encyclopedia of Economics

An online encyclopedia is an encyclopedia accessible through the internet, such as the English Wikipedia. The idea to build a free encyclopedia using the Internet can be traced at least to the 1994 Interpedia proposal; it was planned as an encyclopedia on the Internet to which everyone could contribute materials. The project never left the planning stage and was overtaken by a key branch of old printed encyclopedias.
Digitization of old content:
In January 1995, Project Gutenberg started to publish the ASCII text of the Encyclopædia Britannica, 11th edition (1911), but disagreement about the method halted the work after the first volume.
For trademark reasons this has been published as the Gutenberg Encyclopedia. In 2002, ASCII text of and 48 sounds of music was published on Encyclopædia Britannica Eleventh Edition by source; a copyright claim was added to the materials included.
Project Gutenberg has restarted work on digitizing and proofreading this encyclopedia; as of June 2005 it had not yet been published. Meanwhile, in the face of competition from rivals such as Encarta, the latest Britannica was digitized by its publishers, and sold first as a CD-ROM and later as an online service.
Other digitization projects have made progress in other titles. One example is Easton's Bible Dictionary (1897) digitized by the Christian Classics Ethereal Library. Probably the most important and successful digitization of an encyclopedia was the Bartleby Project's online adaptation of the Columbia Encyclopedia, tenth Edition, in early 2000 and is updated periodically.
Creation of new content:
Another related branch of activity is the creation of new, free contents on a volunteer basis. In 1991, the participants of the Usenet newsgroup alt.fan.douglas-adams started a project to produce a real version of The Hitchhiker's Guide to the Galaxy, a fictional encyclopedia used in the works of Douglas Adams.
It became known as Project Galactic Guide. Although it originally aimed to contain only real, factual articles, policy was changed to allow and encourage semi-real and unreal articles as well. Project Galactic Guide contains over 1700 articles, but no new articles have been added since 2000; this is probably partly due to the founding of h2g2, a more official project along similar lines.
See Also: ___________________________________________________________________________
List of Online Encyclopedias:
Click on any of the following blue hyperlinks for a List of Online Encyclopedias by category:
Digitization of old content:
In January 1995, Project Gutenberg started to publish the ASCII text of the Encyclopædia Britannica, 11th edition (1911), but disagreement about the method halted the work after the first volume.
For trademark reasons this has been published as the Gutenberg Encyclopedia. In 2002, ASCII text of and 48 sounds of music was published on Encyclopædia Britannica Eleventh Edition by source; a copyright claim was added to the materials included.
Project Gutenberg has restarted work on digitizing and proofreading this encyclopedia; as of June 2005 it had not yet been published. Meanwhile, in the face of competition from rivals such as Encarta, the latest Britannica was digitized by its publishers, and sold first as a CD-ROM and later as an online service.
Other digitization projects have made progress in other titles. One example is Easton's Bible Dictionary (1897) digitized by the Christian Classics Ethereal Library. Probably the most important and successful digitization of an encyclopedia was the Bartleby Project's online adaptation of the Columbia Encyclopedia, tenth Edition, in early 2000 and is updated periodically.
Creation of new content:
Another related branch of activity is the creation of new, free contents on a volunteer basis. In 1991, the participants of the Usenet newsgroup alt.fan.douglas-adams started a project to produce a real version of The Hitchhiker's Guide to the Galaxy, a fictional encyclopedia used in the works of Douglas Adams.
It became known as Project Galactic Guide. Although it originally aimed to contain only real, factual articles, policy was changed to allow and encourage semi-real and unreal articles as well. Project Galactic Guide contains over 1700 articles, but no new articles have been added since 2000; this is probably partly due to the founding of h2g2, a more official project along similar lines.
See Also: ___________________________________________________________________________
List of Online Encyclopedias:
Click on any of the following blue hyperlinks for a List of Online Encyclopedias by category:
- General reference
- Biography
- Antiquities, arts, and literature
- Regional interest
- Pop culture and fiction
- Mathematics
- Music
- Philosophy
- Politics and history
- Religion and theology
- Science and technology
- See also:
HTTP cookies and How They Work
YouTube Video: How Cookies Work in the Google Chrome Browser
Pictured: How Cookies Work (by Google) (Below: GATC Request Process)
(for description of items "1" through "6", see below picture)
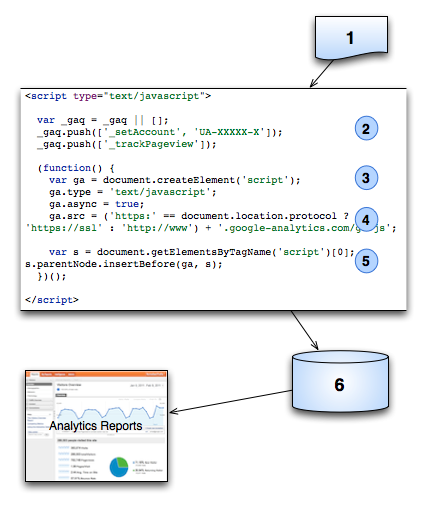
How the Tracking Code Works (see the above illustration):
In general, the Google Analytics Tracking Code (GATC) retrieves web page data as follows:
An HTTP cookie (also called web cookie, Internet cookie, browser cookie, or simply cookie) is a small piece of data sent from a website and stored on the user's computer by the user's web browser while the user is browsing.
Cookies were designed to be a reliable mechanism for websites to remember stateful information (such as items added in the shopping cart in an online store) or to record the user's browsing activity (including clicking particular buttons, logging in, or recording which pages were visited in the past). They can also be used to remember arbitrary pieces of information that the user previously entered into form fields such as names, addresses, passwords, and credit card numbers.
Other kinds of cookies perform essential functions in the modern web. Perhaps most importantly, authentication cookies are the most common method used by web servers to know whether the user is logged in or not, and which account they are logged in with. Without such a mechanism, the site would not know whether to send a page containing sensitive information, or require the user to authenticate themselves by logging in.
The security of an authentication cookie generally depends on the security of the issuing website and the user's web browser, and on whether the cookie data is encrypted. Security vulnerabilities may allow a cookie's data to be read by a hacker, used to gain access to user data, or used to gain access (with the user's credentials) to the website to which the cookie belongs (see cross-site scripting and cross-site request forgery for examples).
The tracking cookies, and especially third-party tracking cookies, are commonly used as ways to compile long-term records of individuals' browsing histories – a potential privacy concern that prompted European and U.S. lawmakers to take action in 2011. European law requires that all websites targeting European Union member states gain "informed consent" from users before storing non-essential cookies on their device.
Origin of the nameThe term "cookie" was coined by web browser programmer Lou Montulli. It was derived from the term "magic cookie", which is a packet of data a program receives and sends back unchanged, used by Unix programmers.
History
Magic cookies were already used in computing when computer programmer Lou Montulli had the idea of using them in web communications in June 1994. At the time, he was an employee of Netscape Communications, which was developing an e-commerce application for MCI.
Vint Cerf and John Klensin represented MCI in technical discussions with Netscape Communications. MCI did not want its servers to have to retain partial transaction states, which led them to ask Netscape to find a way to store that state in each user's computer instead. Cookies provided a solution to the problem of reliably implementing a virtual shopping cart.
Together with John Giannandrea, Montulli wrote the initial Netscape cookie specification the same year. Version 0.9beta of Mosaic Netscape, released on October 13, 1994, supported cookies.
The first use of cookies (out of the labs) was checking whether visitors to the Netscape website had already visited the site. Montulli applied for a patent for the cookie technology in 1995, and US 5774670 was granted in 1998. Support for cookies was integrated in Internet Explorer in version 2, released in October 1995.
The introduction of cookies was not widely known to the public at the time. In particular, cookies were accepted by default, and users were not notified of their presence. The general public learned about cookies after the Financial Times published an article about them on February 12, 1996. In the same year, cookies received a lot of media attention, especially because of potential privacy implications. Cookies were discussed in two U.S. Federal Trade Commission hearings in 1996 and 1997.
The development of the formal cookie specifications was already ongoing. In particular, the first discussions about a formal specification started in April 1995 on the www-talk mailing list. A special working group within the Internet Engineering Task Force (IETF) was formed.
Two alternative proposals for introducing state in HTTP transactions had been proposed by Brian Behlendorf and David Kristol respectively. But the group, headed by Kristol himself and Lou Montulli, soon decided to use the Netscape specification as a starting point.
In February 1996, the working group identified third-party cookies as a considerable privacy threat. The specification produced by the group was eventually published as RFC 2109 in February 1997. It specifies that third-party cookies were either not allowed at all, or at least not enabled by default.
At this time, advertising companies were already using third-party cookies. The recommendation about third-party cookies of RFC 2109 was not followed by Netscape and Internet Explorer. RFC 2109 was superseded by RFC 2965 in October 2000. RFC 2965 added a Set-Cookie2 header, which informally came to be called "RFC 2965-style cookies" as opposed to the original Set-Cookie header which was called "Netscape-style cookies". Set-Cookie2 was seldom used however, and was deprecated in RFC 6265 in April 2011 which was written as a definitive specification for cookies as used in the real world.
Types of Cookies:
Session cookie:
A session cookie, also known as an in-memory cookie or transient cookie, exists only in temporary memory while the user navigates the website. Web browsers normally delete session cookies when the user closes the browser. Unlike other cookies, session cookies do not have an expiration date assigned to them, which is how the browser knows to treat them as session cookies.
Persistent cookie;
Instead of expiring when the web browser is closed as session cookies do, a persistent cookie expires at a specific date or after a specific length of time. This means that, for the cookie's entire lifespan (which can be as long or as short as its creators want), its information will be transmitted to the server every time the user visits the website that it belongs to, or every time the user views a resource belonging to that website from another website (such as an advertisement).
For this reason, persistent cookies are sometimes referred to as tracking cookies because they can be used by advertisers to record information about a user's web browsing habits over an extended period of time. However, they are also used for "legitimate" reasons (such as keeping users logged into their accounts on websites, to avoid re-entering login credentials at every visit).
These cookies are however reset if the expiration time is reached or the user manually deletes the cookie.
Secure cookie:
A secure cookie can only be transmitted over an encrypted connection (i.e. HTTPS). They cannot be transmitted over unencrypted connections (i.e. HTTP). This makes the cookie less likely to be exposed to cookie theft via eavesdropping. A cookie is made secure by adding the Secure flag to the cookie.
HttpOnly cookie:
An HttpOnly cookie cannot be accessed by client-side APIs, such as JavaScript. This restriction eliminates the threat of cookie theft via cross-site scripting (XSS). However, the cookie remains vulnerable to cross-site tracing (XST) and cross-site request forgery (XSRF) attacks. A cookie is given this characteristic by adding the HttpOnly flag to the cookie.
SameSite cookie:
Google Chrome 51 recently introduced a new kind of cookie which can only be sent in requests originating from the same origin as the target domain. This restriction mitigates attacks such as cross-site request forgery (XSRF). A cookie is given this characteristic by setting the SameSite flag to Strict or Lax.
Third-party cookie:
Normally, a cookie's domain attribute will match the domain that is shown in the web browser's address bar. This is called a first-party cookie. A third-party cookie, however, belongs to a domain different from the one shown in the address bar. This sort of cookie typically appears when web pages feature content from external websites, such as banner advertisements. This opens up the potential for tracking the user's browsing history, and is often used by advertisers in an effort to serve relevant advertisements to each user.
As an example, suppose a user visits www.example.org. This web site contains an advertisement from ad.foxytracking.com, which, when downloaded, sets a cookie belonging to the advertisement's domain (ad.foxytracking.com).
Then, the user visits another website, www.foo.com, which also contains an advertisement from ad.foxytracking.com, and which also sets a cookie belonging to that domain (ad.foxytracking.com). Eventually, both of these cookies will be sent to the advertiser when loading their advertisements or visiting their website. The advertiser can then use these cookies to build up a browsing history of the user across all the websites that have ads from this advertiser.
As of 2014, some websites were setting cookies readable for over 100 third-party domains. On average, a single website was setting 10 cookies, with a maximum number of cookies (first- and third-party) reaching over 800.
Most modern web browsers contain privacy settings that can block third-party cookies.
Supercookie:
A supercookie is a cookie with an origin of a top-level domain (such as .com) or a public suffix (such as .co.uk). Ordinary cookies, by contrast, have an origin of a specific domain name, such as example.com.
Supercookies can be a potential security concern and are therefore often blocked by web browsers. If unblocked by the browser, an attacker in control of a malicious website could set a supercookie and potentially disrupt or impersonate legitimate user requests to another website that shares the same top-level domain or public suffix as the malicious website.
For example, a supercookie with an origin of .com, could maliciously affect a request made to example.com, even if the cookie did not originate from example.com. This can be used to fake logins or change user information.
The Public Suffix List helps to mitigate the risk that supercookies pose. The Public Suffix List is a cross-vendor initiative that aims to provide an accurate and up-to-date list of domain name suffixes. Older versions of browsers may not have an up-to-date list, and will therefore be vulnerable to supercookies from certain domains.
Other usesThe term "supercookie" is sometimes used for tracking technologies that do not rely on HTTP cookies. Two such "supercookie" mechanisms were found on Microsoft websites in August 2011: cookie syncing that respawned MUID (machine unique identifier) cookies, and ETag cookies. Due to media attention, Microsoft later disabled this code.
Zombie cookie:
Main articles: Zombie cookie and Evercookie
A zombie cookie is a cookie that is automatically recreated after being deleted. This is accomplished by storing the cookie's content in multiple locations, such as Flash Local shared object, HTML5 Web storage, and other client-side and even server-side locations. When the cookie's absence is detected, the cookie is recreated using the data stored in these locations.
Cookie Structure:
A cookie consists of the following components:
Cookie Uses:
Session management:
Cookies were originally introduced to provide a way for users to record items they want to purchase as they navigate throughout a website (a virtual "shopping cart" or "shopping basket").
Today, however, the contents of a user's shopping cart are usually stored in a database on the server, rather than in a cookie on the client. To keep track of which user is assigned to which shopping cart, the server sends a cookie to the client that contains a unique session identifier (typically, a long string of random letters and numbers).
Because cookies are sent to the server with every request the client makes, that session identifier will be sent back to the server every time the user visits a new page on the website, which lets the server know which shopping cart to display to the user.
Another popular use of cookies is for logging into websites. When the user visits a website's login page, the web server typically sends the client a cookie containing a unique session identifier. When the user successfully logs in, the server remembers that that particular session identifier has been authenticated, and grants the user access to its services.
Because session cookies only contain a unique session identifier, this makes the amount of personal information that a website can save about each user virtually limitless—the website is not limited to restrictions concerning how large a cookie can be. Session cookies also help to improve page load times, since the amount of information in a session cookie is small and requires little bandwidth.
Personalization:
Cookies can be used to remember information about the user in order to show relevant content to that user over time. For example, a web server might send a cookie containing the username last used to log into a website so that it may be filled in automatically the next time the user logs in.
Many websites use cookies for personalization based on the user's preferences. Users select their preferences by entering them in a web form and submitting the form to the server. The server encodes the preferences in a cookie and sends the cookie back to the browser. This way, every time the user accesses a page on the website, the server can personalize the page according to the user's preferences.
For example, the Google search engine once used cookies to allow users (even non-registered ones) to decide how many search results per page they wanted to see.
Also, DuckDuckGo uses cookies to allow users to set the viewing preferences like colors of the web page.
Tracking:
See also: Web visitor tracking
Tracking cookies are used to track users' web browsing habits. This can also be done to some extent by using the IP address of the computer requesting the page or the referer field of the HTTP request header, but cookies allow for greater precision. This can be demonstrated as follows:
By analyzing this log file, it is then possible to find out which pages the user has visited, in what sequence, and for how long.
Corporations exploit users' web habits by tracking cookies to collect information about buying habits. The Wall Street Journal found that America's top fifty websites installed an average of sixty-four pieces of tracking technology onto computers resulting in a total of 3,180 tracking files. The data can then be collected and sold to bidding corporations.
Implemention:
Cookies are arbitrary pieces of data, usually chosen and first sent by the web server, and stored on the client computer by the web browser. The browser then sends them back to the server with every request, introducing states (memory of previous events) into otherwise stateless HTTP transactions.
Without cookies, each retrieval of a web page or component of a web page would be an isolated event, largely unrelated to all other page views made by the user on the website.
Although cookies are usually set by the web server, they can also be set by the client using a scripting language such as JavaScript (unless the cookie's HttpOnly flag is set, in which case the cookie cannot be modified by scripting languages).
The cookie specifications require that browsers meet the following requirements in order to support cookies:
See also:
Browser Settings:
Most modern browsers support cookies and allow the user to disable them. The following are common options:
By default, Internet Explorer allows third-party cookies only if they are accompanied by a P3P "CP" (Compact Policy) field.
Add-on tools for managing cookie permissions also exist.
Privacy and third-party cookies:
See also: Do Not Track and Web analytics § Problems with cookies
Cookies have some important implications on the privacy and anonymity of web users. While cookies are sent only to the server setting them or a server in the same Internet domain, a web page may contain images or other components stored on servers in other domains.
Cookies that are set during retrieval of these components are called third-party cookies. The older standards for cookies, RFC 2109 and RFC 2965, specify that browsers should protect user privacy and not allow sharing of cookies between servers by default. However, the newer standard, RFC 6265, explicitly allows user agents to implement whichever third-party cookie policy they wish.
Most browsers, such as Mozilla Firefox, Internet Explorer, Opera and Google Chrome do allow third-party cookies by default, as long as the third-party website has Compact Privacy Policy published.
Newer versions of Safari block third-party cookies, and this is planned for Mozilla Firefox as well (initially planned for version 22 but was postponed indefinitely).
Advertising companies use third-party cookies to track a user across multiple sites. In particular, an advertising company can track a user across all pages where it has placed advertising images or web bugs.
Knowledge of the pages visited by a user allows the advertising company to target advertisements to the user's presumed preferences.
Website operators who do not disclose third-party cookie use to consumers run the risk of harming consumer trust if cookie use is discovered. Having clear disclosure (such as in a privacy policy) tends to eliminate any negative effects of such cookie discovery.
The possibility of building a profile of users is a privacy threat, especially when tracking is done across multiple domains using third-party cookies. For this reason, some countries have legislation about cookies.
The United States government has set strict rules on setting cookies in 2000 after it was disclosed that the White House drug policy office used cookies to track computer users viewing its online anti-drug advertising. In 2002, privacy activist Daniel Brandt found that the CIA had been leaving persistent cookies on computers which had visited its website.
When notified it was violating policy, CIA stated that these cookies were not intentionally set and stopped setting them. On December 25, 2005, Brandt discovered that the National Security Agency (NSA) had been leaving two persistent cookies on visitors' computers due to a software upgrade. After being informed, the NSA immediately disabled the cookies.
Cookie theft and session hijacking:
Most websites use cookies as the only identifiers for user sessions, because other methods of identifying web users have limitations and vulnerabilities. If a website uses cookies as session identifiers, attackers can impersonate users' requests by stealing a full set of victims' cookies.
From the web server's point of view, a request from an attacker then has the same authentication as the victim's requests; thus the request is performed on behalf of the victim's session.
Listed here are various scenarios of cookie theft and user session hijacking (even without stealing user cookies) which work with websites which rely solely on HTTP cookies for user identification.
See Also:
Drawbacks of cookies:
Besides privacy concerns, cookies also have some technical drawbacks. In particular, they do not always accurately identify users, they can be used for security attacks, and they are often at odds with the Representational State Transfer (REST) software architectural style.
Inaccurate identification:
If more than one browser is used on a computer, each usually has a separate storage area for cookies. Hence cookies do not identify a person, but a combination of a user account, a computer, and a web browser. Thus, anyone who uses multiple accounts, computers, or browsers has multiple sets of cookies.
Likewise, cookies do not differentiate between multiple users who share the same user account, computer, and browser.
Inconsistent state on client and server:
The use of cookies may generate an inconsistency between the state of the client and the state as stored in the cookie. If the user acquires a cookie and then clicks the "Back" button of the browser, the state on the browser is generally not the same as before that acquisition.
As an example, if the shopping cart of an online shop is built using cookies, the content of the cart may not change when the user goes back in the browser's history: if the user presses a button to add an item in the shopping cart and then clicks on the "Back" button, the item remains in the shopping cart.
This might not be the intention of the user, who possibly wanted to undo the addition of the item. This can lead to unreliability, confusion, and bugs. Web developers should therefore be aware of this issue and implement measures to handle such situations.
Alternatives to cookies:
Some of the operations that can be done using cookies can also be done using other mechanisms.
JSON Web Tokens:
JSON Web Token (JWT) is a self-contained packet of information that can be used to store user identity and authenticity information. This allows them to be used in place of session cookies. Unlike cookies, which are automatically attached to each HTTP request by the browser, JWTs must be explicitly attached to each HTTP request by the web application.
HTTP authentication:
The HTTP protocol includes the basic access authentication and the digest access authentication protocols, which allow access to a web page only when the user has provided the correct username and password. If the server requires such credentials for granting access to a web page, the browser requests them from the user and, once obtained, the browser stores and sends them in every subsequent page request. This information can be used to track the user.
IP address:
Some users may be tracked based on the IP address of the computer requesting the page. The server knows the IP address of the computer running the browser (or the proxy, if any is used) and could theoretically link a user's session to this IP address.
However, IP addresses are generally not a reliable way to track a session or identify a user. Many computers designed to be used by a single user, such as office PCs or home PCs, are behind a network address translator (NAT).
This means that several PCs will share a public IP address. Furthermore, some systems, such as Tor, are designed to retain Internet anonymity, rendering tracking by IP address impractical, impossible, or a security risk.
URL (query string):
A more precise technique is based on embedding information into URLs. The query string part of the URL is the part that is typically used for this purpose, but other parts can be used as well. The Java Servlet and PHP session mechanisms both use this method if cookies are not enabled.
This method consists of the web server appending query strings containing a unique session identifier to all the links inside of a web page. When the user follows a link, the browser sends the query string to the server, allowing the server to identify the user and maintain state.
These kinds of query strings are very similar to cookies in that both contain arbitrary pieces of information chosen by the server and both are sent back to the server on every request.
However, there are some differences. Since a query string is part of a URL, if that URL is later reused, the same attached piece of information will be sent to the server, which could lead to confusion. For example, if the preferences of a user are encoded in the query string of a URL and the user sends this URL to another user by e-mail, those preferences will be used for that other user as well.
Moreover, if the same user accesses the same page multiple times from different sources, there is no guarantee that the same query string will be used each time. For example, if a user visits a page by coming from a page internal to the site the first time, and then visits the same page by coming from an external search engine the second time, the query strings would likely be different. If cookies were used in this situation, the cookies would be the same.
Other drawbacks of query strings are related to security. Storing data that identifies a session in a query string enables session fixation attacks, referer logging attacks and other security exploits. Transferring session identifiers as HTTP cookies is more secure.
Hidden form fields:
Another form of session tracking is to use web forms with hidden fields. This technique is very similar to using URL query strings to hold the information and has many of the same advantages and drawbacks.
In fact, if the form is handled with the HTTP GET method, then this technique is similar to using URL query strings, since the GET method adds the form fields to the URL as a query string. But most forms are handled with HTTP POST, which causes the form information, including the hidden fields, to be sent in the HTTP request body, which is neither part of the URL, nor of a cookie.
This approach presents two advantages from the point of view of the tracker:
"window.name" DOM property:
All current web browsers can store a fairly large amount of data (2–32 MB) via JavaScript using the DOM property window.name. This data can be used instead of session cookies and is also cross-domain. The technique can be coupled with JSON/JavaScript objects to store complex sets of session variables on the client side.
The downside is that every separate window or tab will initially have an empty window.name property when opened. Furthermore, the property can be used for tracking visitors across different websites, making it of concern for Internet privacy.
In some respects, this can be more secure than cookies due to the fact that its contents are not automatically sent to the server on every request like cookies are, so it is not vulnerable to network cookie sniffing attacks. However, if special measures are not taken to protect the data, it is vulnerable to other attacks because the data is available across different websites opened in the same window or tab.
Identifier for advertisers:
Apple uses a tracking technique called "identifier for advertisers" (IDFA). This technique assigns a unique identifier to every user that buys an Apple iOS device (such as an iPhone or iPad). This identifier is then used by Apple's advertising network, iAd, to determine the ads that individuals are viewing and responding to.
ETagMain:
Article: HTTP ETag § Tracking using ETags
Because ETags are cached by the browser, and returned with subsequent requests for the same resource, a tracking server can simply repeat any ETag received from the browser to ensure an assigned ETag persists indefinitely (in a similar way to persistent cookies). Additional caching headers can also enhance the preservation of ETag data.
ETags can be flushed in some browsers by clearing the browser cache.
Web storage:
Main article: Web storage
Some web browsers support persistence mechanisms which allow the page to store the information locally for later use.
The HTML5 standard (which most modern web browsers support to some extent) includes a JavaScript API called Web storage that allows two types of storage: local storage and session storage.
Local storage behaves similarly to persistent cookies while session storage behaves similarly to session cookies, except that session storage is tied to an individual tab/window's lifetime (AKA a page session), not to a whole browser session like session cookies.
Internet Explorer supports persistent information in the browser's history, in the browser's favorites, in an XML store ("user data"), or directly within a web page saved to disk.
Some web browser plugins include persistence mechanisms as well. For example, Adobe Flash has Local shared object and Microsoft Silverlight has Isolated storage.
Browser cache:
Main article: Web cache
The browser cache can also be used to store information that can be used to track individual users. This technique takes advantage of the fact that the web browser will use resources stored within the cache instead of downloading them from the website when it determines that the cache already has the most up-to-date version of the resource.
For example, a website could serve a JavaScript file that contains code which sets a unique identifier for the user (for example, var userId = 3243242;). After the user's initial visit, every time the user accesses the page, this file will be loaded from the cache instead of downloaded from the server. Thus, its content will never change.
Browser fingerprint:
Main article: Device fingerprint
A browser fingerprint is information collected about a browser's configuration, such as version number, screen resolution, and operating system, for the purpose of identification. Fingerprints can be used to fully or partially identify individual users or devices even when cookies are turned off.
Basic web browser configuration information has long been collected by web analytics services in an effort to accurately measure real human web traffic and discount various forms of click fraud.
With the assistance of client-side scripting languages, collection of much more esoteric parameters is possible. Assimilation of such information into a single string comprises a device fingerprint.
In 2010, EFF measured at least 18.1 bits of entropy possible from browser fingerprinting. Canvas fingerprinting, a more recent technique, claims to add another 5.7 bits.
See also:
In general, the Google Analytics Tracking Code (GATC) retrieves web page data as follows:
- A browser requests a web page that contains the tracking code.
- A JavaScript Array named _gaq is created and tracking commands are pushed onto the array.
- A <script> element is created and enabled for asynchronous loading (loading in the background).
- The ga.js tracking code is fetched, with the appropriate protocol automatically detected. Once the code is fetched and loaded, the commands on the _gaq array are executed and the array is transformed into a tracking object. Subsequent tracking calls are made directly to Google Analytics.
- Loads the script element to the DOM.
- After the tracking code collects data, the GIF request is sent to the Analytics database for logging and post-processing.
An HTTP cookie (also called web cookie, Internet cookie, browser cookie, or simply cookie) is a small piece of data sent from a website and stored on the user's computer by the user's web browser while the user is browsing.
Cookies were designed to be a reliable mechanism for websites to remember stateful information (such as items added in the shopping cart in an online store) or to record the user's browsing activity (including clicking particular buttons, logging in, or recording which pages were visited in the past). They can also be used to remember arbitrary pieces of information that the user previously entered into form fields such as names, addresses, passwords, and credit card numbers.
Other kinds of cookies perform essential functions in the modern web. Perhaps most importantly, authentication cookies are the most common method used by web servers to know whether the user is logged in or not, and which account they are logged in with. Without such a mechanism, the site would not know whether to send a page containing sensitive information, or require the user to authenticate themselves by logging in.
The security of an authentication cookie generally depends on the security of the issuing website and the user's web browser, and on whether the cookie data is encrypted. Security vulnerabilities may allow a cookie's data to be read by a hacker, used to gain access to user data, or used to gain access (with the user's credentials) to the website to which the cookie belongs (see cross-site scripting and cross-site request forgery for examples).
The tracking cookies, and especially third-party tracking cookies, are commonly used as ways to compile long-term records of individuals' browsing histories – a potential privacy concern that prompted European and U.S. lawmakers to take action in 2011. European law requires that all websites targeting European Union member states gain "informed consent" from users before storing non-essential cookies on their device.
Origin of the nameThe term "cookie" was coined by web browser programmer Lou Montulli. It was derived from the term "magic cookie", which is a packet of data a program receives and sends back unchanged, used by Unix programmers.
History
Magic cookies were already used in computing when computer programmer Lou Montulli had the idea of using them in web communications in June 1994. At the time, he was an employee of Netscape Communications, which was developing an e-commerce application for MCI.
Vint Cerf and John Klensin represented MCI in technical discussions with Netscape Communications. MCI did not want its servers to have to retain partial transaction states, which led them to ask Netscape to find a way to store that state in each user's computer instead. Cookies provided a solution to the problem of reliably implementing a virtual shopping cart.
Together with John Giannandrea, Montulli wrote the initial Netscape cookie specification the same year. Version 0.9beta of Mosaic Netscape, released on October 13, 1994, supported cookies.
The first use of cookies (out of the labs) was checking whether visitors to the Netscape website had already visited the site. Montulli applied for a patent for the cookie technology in 1995, and US 5774670 was granted in 1998. Support for cookies was integrated in Internet Explorer in version 2, released in October 1995.
The introduction of cookies was not widely known to the public at the time. In particular, cookies were accepted by default, and users were not notified of their presence. The general public learned about cookies after the Financial Times published an article about them on February 12, 1996. In the same year, cookies received a lot of media attention, especially because of potential privacy implications. Cookies were discussed in two U.S. Federal Trade Commission hearings in 1996 and 1997.
The development of the formal cookie specifications was already ongoing. In particular, the first discussions about a formal specification started in April 1995 on the www-talk mailing list. A special working group within the Internet Engineering Task Force (IETF) was formed.
Two alternative proposals for introducing state in HTTP transactions had been proposed by Brian Behlendorf and David Kristol respectively. But the group, headed by Kristol himself and Lou Montulli, soon decided to use the Netscape specification as a starting point.
In February 1996, the working group identified third-party cookies as a considerable privacy threat. The specification produced by the group was eventually published as RFC 2109 in February 1997. It specifies that third-party cookies were either not allowed at all, or at least not enabled by default.
At this time, advertising companies were already using third-party cookies. The recommendation about third-party cookies of RFC 2109 was not followed by Netscape and Internet Explorer. RFC 2109 was superseded by RFC 2965 in October 2000. RFC 2965 added a Set-Cookie2 header, which informally came to be called "RFC 2965-style cookies" as opposed to the original Set-Cookie header which was called "Netscape-style cookies". Set-Cookie2 was seldom used however, and was deprecated in RFC 6265 in April 2011 which was written as a definitive specification for cookies as used in the real world.
Types of Cookies:
Session cookie:
A session cookie, also known as an in-memory cookie or transient cookie, exists only in temporary memory while the user navigates the website. Web browsers normally delete session cookies when the user closes the browser. Unlike other cookies, session cookies do not have an expiration date assigned to them, which is how the browser knows to treat them as session cookies.
Persistent cookie;
Instead of expiring when the web browser is closed as session cookies do, a persistent cookie expires at a specific date or after a specific length of time. This means that, for the cookie's entire lifespan (which can be as long or as short as its creators want), its information will be transmitted to the server every time the user visits the website that it belongs to, or every time the user views a resource belonging to that website from another website (such as an advertisement).
For this reason, persistent cookies are sometimes referred to as tracking cookies because they can be used by advertisers to record information about a user's web browsing habits over an extended period of time. However, they are also used for "legitimate" reasons (such as keeping users logged into their accounts on websites, to avoid re-entering login credentials at every visit).
These cookies are however reset if the expiration time is reached or the user manually deletes the cookie.
Secure cookie:
A secure cookie can only be transmitted over an encrypted connection (i.e. HTTPS). They cannot be transmitted over unencrypted connections (i.e. HTTP). This makes the cookie less likely to be exposed to cookie theft via eavesdropping. A cookie is made secure by adding the Secure flag to the cookie.
HttpOnly cookie:
An HttpOnly cookie cannot be accessed by client-side APIs, such as JavaScript. This restriction eliminates the threat of cookie theft via cross-site scripting (XSS). However, the cookie remains vulnerable to cross-site tracing (XST) and cross-site request forgery (XSRF) attacks. A cookie is given this characteristic by adding the HttpOnly flag to the cookie.
SameSite cookie:
Google Chrome 51 recently introduced a new kind of cookie which can only be sent in requests originating from the same origin as the target domain. This restriction mitigates attacks such as cross-site request forgery (XSRF). A cookie is given this characteristic by setting the SameSite flag to Strict or Lax.
Third-party cookie:
Normally, a cookie's domain attribute will match the domain that is shown in the web browser's address bar. This is called a first-party cookie. A third-party cookie, however, belongs to a domain different from the one shown in the address bar. This sort of cookie typically appears when web pages feature content from external websites, such as banner advertisements. This opens up the potential for tracking the user's browsing history, and is often used by advertisers in an effort to serve relevant advertisements to each user.
As an example, suppose a user visits www.example.org. This web site contains an advertisement from ad.foxytracking.com, which, when downloaded, sets a cookie belonging to the advertisement's domain (ad.foxytracking.com).
Then, the user visits another website, www.foo.com, which also contains an advertisement from ad.foxytracking.com, and which also sets a cookie belonging to that domain (ad.foxytracking.com). Eventually, both of these cookies will be sent to the advertiser when loading their advertisements or visiting their website. The advertiser can then use these cookies to build up a browsing history of the user across all the websites that have ads from this advertiser.
As of 2014, some websites were setting cookies readable for over 100 third-party domains. On average, a single website was setting 10 cookies, with a maximum number of cookies (first- and third-party) reaching over 800.
Most modern web browsers contain privacy settings that can block third-party cookies.
Supercookie:
A supercookie is a cookie with an origin of a top-level domain (such as .com) or a public suffix (such as .co.uk). Ordinary cookies, by contrast, have an origin of a specific domain name, such as example.com.
Supercookies can be a potential security concern and are therefore often blocked by web browsers. If unblocked by the browser, an attacker in control of a malicious website could set a supercookie and potentially disrupt or impersonate legitimate user requests to another website that shares the same top-level domain or public suffix as the malicious website.
For example, a supercookie with an origin of .com, could maliciously affect a request made to example.com, even if the cookie did not originate from example.com. This can be used to fake logins or change user information.
The Public Suffix List helps to mitigate the risk that supercookies pose. The Public Suffix List is a cross-vendor initiative that aims to provide an accurate and up-to-date list of domain name suffixes. Older versions of browsers may not have an up-to-date list, and will therefore be vulnerable to supercookies from certain domains.
Other usesThe term "supercookie" is sometimes used for tracking technologies that do not rely on HTTP cookies. Two such "supercookie" mechanisms were found on Microsoft websites in August 2011: cookie syncing that respawned MUID (machine unique identifier) cookies, and ETag cookies. Due to media attention, Microsoft later disabled this code.
Zombie cookie:
Main articles: Zombie cookie and Evercookie
A zombie cookie is a cookie that is automatically recreated after being deleted. This is accomplished by storing the cookie's content in multiple locations, such as Flash Local shared object, HTML5 Web storage, and other client-side and even server-side locations. When the cookie's absence is detected, the cookie is recreated using the data stored in these locations.
Cookie Structure:
A cookie consists of the following components:
- Name
- Value
- Zero or more attributes (name/value pairs). Attributes store information such as the cookie’s expiration, domain, and flags (such as Secure and HttpOnly).
Cookie Uses:
Session management:
Cookies were originally introduced to provide a way for users to record items they want to purchase as they navigate throughout a website (a virtual "shopping cart" or "shopping basket").
Today, however, the contents of a user's shopping cart are usually stored in a database on the server, rather than in a cookie on the client. To keep track of which user is assigned to which shopping cart, the server sends a cookie to the client that contains a unique session identifier (typically, a long string of random letters and numbers).
Because cookies are sent to the server with every request the client makes, that session identifier will be sent back to the server every time the user visits a new page on the website, which lets the server know which shopping cart to display to the user.
Another popular use of cookies is for logging into websites. When the user visits a website's login page, the web server typically sends the client a cookie containing a unique session identifier. When the user successfully logs in, the server remembers that that particular session identifier has been authenticated, and grants the user access to its services.
Because session cookies only contain a unique session identifier, this makes the amount of personal information that a website can save about each user virtually limitless—the website is not limited to restrictions concerning how large a cookie can be. Session cookies also help to improve page load times, since the amount of information in a session cookie is small and requires little bandwidth.
Personalization:
Cookies can be used to remember information about the user in order to show relevant content to that user over time. For example, a web server might send a cookie containing the username last used to log into a website so that it may be filled in automatically the next time the user logs in.
Many websites use cookies for personalization based on the user's preferences. Users select their preferences by entering them in a web form and submitting the form to the server. The server encodes the preferences in a cookie and sends the cookie back to the browser. This way, every time the user accesses a page on the website, the server can personalize the page according to the user's preferences.
For example, the Google search engine once used cookies to allow users (even non-registered ones) to decide how many search results per page they wanted to see.
Also, DuckDuckGo uses cookies to allow users to set the viewing preferences like colors of the web page.
Tracking:
See also: Web visitor tracking
Tracking cookies are used to track users' web browsing habits. This can also be done to some extent by using the IP address of the computer requesting the page or the referer field of the HTTP request header, but cookies allow for greater precision. This can be demonstrated as follows:
- If the user requests a page of the site, but the request contains no cookie, the server presumes that this is the first page visited by the user. So the server creates a unique identifier (typically a string of random letters and numbers) and sends it as a cookie back to the browser together with the requested page.
- From this point on, the cookie will automatically be sent by the browser to the server every time a new page from the site is requested. The server sends the page as usual, but also stores the URL of the requested page, the date/time of the request, and the cookie in a log file.
By analyzing this log file, it is then possible to find out which pages the user has visited, in what sequence, and for how long.
Corporations exploit users' web habits by tracking cookies to collect information about buying habits. The Wall Street Journal found that America's top fifty websites installed an average of sixty-four pieces of tracking technology onto computers resulting in a total of 3,180 tracking files. The data can then be collected and sold to bidding corporations.
Implemention:
Cookies are arbitrary pieces of data, usually chosen and first sent by the web server, and stored on the client computer by the web browser. The browser then sends them back to the server with every request, introducing states (memory of previous events) into otherwise stateless HTTP transactions.
Without cookies, each retrieval of a web page or component of a web page would be an isolated event, largely unrelated to all other page views made by the user on the website.
Although cookies are usually set by the web server, they can also be set by the client using a scripting language such as JavaScript (unless the cookie's HttpOnly flag is set, in which case the cookie cannot be modified by scripting languages).
The cookie specifications require that browsers meet the following requirements in order to support cookies:
- Can support cookies as large as 4,096 bytes in size.
- Can support at least 50 cookies per domain (i.e. per website).
- Can support at least 3,000 cookies in total.
See also:
Browser Settings:
Most modern browsers support cookies and allow the user to disable them. The following are common options:
- To enable or disable cookies completely, so that they are always accepted or always blocked.
- To view and selectively delete cookies using a cookie manager.
- To fully wipe all private data, including cookies.
By default, Internet Explorer allows third-party cookies only if they are accompanied by a P3P "CP" (Compact Policy) field.
Add-on tools for managing cookie permissions also exist.
Privacy and third-party cookies:
See also: Do Not Track and Web analytics § Problems with cookies
Cookies have some important implications on the privacy and anonymity of web users. While cookies are sent only to the server setting them or a server in the same Internet domain, a web page may contain images or other components stored on servers in other domains.
Cookies that are set during retrieval of these components are called third-party cookies. The older standards for cookies, RFC 2109 and RFC 2965, specify that browsers should protect user privacy and not allow sharing of cookies between servers by default. However, the newer standard, RFC 6265, explicitly allows user agents to implement whichever third-party cookie policy they wish.
Most browsers, such as Mozilla Firefox, Internet Explorer, Opera and Google Chrome do allow third-party cookies by default, as long as the third-party website has Compact Privacy Policy published.
Newer versions of Safari block third-party cookies, and this is planned for Mozilla Firefox as well (initially planned for version 22 but was postponed indefinitely).
Advertising companies use third-party cookies to track a user across multiple sites. In particular, an advertising company can track a user across all pages where it has placed advertising images or web bugs.
Knowledge of the pages visited by a user allows the advertising company to target advertisements to the user's presumed preferences.
Website operators who do not disclose third-party cookie use to consumers run the risk of harming consumer trust if cookie use is discovered. Having clear disclosure (such as in a privacy policy) tends to eliminate any negative effects of such cookie discovery.
The possibility of building a profile of users is a privacy threat, especially when tracking is done across multiple domains using third-party cookies. For this reason, some countries have legislation about cookies.
The United States government has set strict rules on setting cookies in 2000 after it was disclosed that the White House drug policy office used cookies to track computer users viewing its online anti-drug advertising. In 2002, privacy activist Daniel Brandt found that the CIA had been leaving persistent cookies on computers which had visited its website.
When notified it was violating policy, CIA stated that these cookies were not intentionally set and stopped setting them. On December 25, 2005, Brandt discovered that the National Security Agency (NSA) had been leaving two persistent cookies on visitors' computers due to a software upgrade. After being informed, the NSA immediately disabled the cookies.
Cookie theft and session hijacking:
Most websites use cookies as the only identifiers for user sessions, because other methods of identifying web users have limitations and vulnerabilities. If a website uses cookies as session identifiers, attackers can impersonate users' requests by stealing a full set of victims' cookies.
From the web server's point of view, a request from an attacker then has the same authentication as the victim's requests; thus the request is performed on behalf of the victim's session.
Listed here are various scenarios of cookie theft and user session hijacking (even without stealing user cookies) which work with websites which rely solely on HTTP cookies for user identification.
See Also:
- Network eavesdropping
- Publishing false sub-domain: DNS cache poisoning
- Cross-site scripting: cookie theft
- Cross-site scripting: proxy request
- Cross-site request forgery
Drawbacks of cookies:
Besides privacy concerns, cookies also have some technical drawbacks. In particular, they do not always accurately identify users, they can be used for security attacks, and they are often at odds with the Representational State Transfer (REST) software architectural style.
Inaccurate identification:
If more than one browser is used on a computer, each usually has a separate storage area for cookies. Hence cookies do not identify a person, but a combination of a user account, a computer, and a web browser. Thus, anyone who uses multiple accounts, computers, or browsers has multiple sets of cookies.
Likewise, cookies do not differentiate between multiple users who share the same user account, computer, and browser.
Inconsistent state on client and server:
The use of cookies may generate an inconsistency between the state of the client and the state as stored in the cookie. If the user acquires a cookie and then clicks the "Back" button of the browser, the state on the browser is generally not the same as before that acquisition.
As an example, if the shopping cart of an online shop is built using cookies, the content of the cart may not change when the user goes back in the browser's history: if the user presses a button to add an item in the shopping cart and then clicks on the "Back" button, the item remains in the shopping cart.
This might not be the intention of the user, who possibly wanted to undo the addition of the item. This can lead to unreliability, confusion, and bugs. Web developers should therefore be aware of this issue and implement measures to handle such situations.
Alternatives to cookies:
Some of the operations that can be done using cookies can also be done using other mechanisms.
JSON Web Tokens:
JSON Web Token (JWT) is a self-contained packet of information that can be used to store user identity and authenticity information. This allows them to be used in place of session cookies. Unlike cookies, which are automatically attached to each HTTP request by the browser, JWTs must be explicitly attached to each HTTP request by the web application.
HTTP authentication:
The HTTP protocol includes the basic access authentication and the digest access authentication protocols, which allow access to a web page only when the user has provided the correct username and password. If the server requires such credentials for granting access to a web page, the browser requests them from the user and, once obtained, the browser stores and sends them in every subsequent page request. This information can be used to track the user.
IP address:
Some users may be tracked based on the IP address of the computer requesting the page. The server knows the IP address of the computer running the browser (or the proxy, if any is used) and could theoretically link a user's session to this IP address.
However, IP addresses are generally not a reliable way to track a session or identify a user. Many computers designed to be used by a single user, such as office PCs or home PCs, are behind a network address translator (NAT).
This means that several PCs will share a public IP address. Furthermore, some systems, such as Tor, are designed to retain Internet anonymity, rendering tracking by IP address impractical, impossible, or a security risk.
URL (query string):
A more precise technique is based on embedding information into URLs. The query string part of the URL is the part that is typically used for this purpose, but other parts can be used as well. The Java Servlet and PHP session mechanisms both use this method if cookies are not enabled.
This method consists of the web server appending query strings containing a unique session identifier to all the links inside of a web page. When the user follows a link, the browser sends the query string to the server, allowing the server to identify the user and maintain state.
These kinds of query strings are very similar to cookies in that both contain arbitrary pieces of information chosen by the server and both are sent back to the server on every request.
However, there are some differences. Since a query string is part of a URL, if that URL is later reused, the same attached piece of information will be sent to the server, which could lead to confusion. For example, if the preferences of a user are encoded in the query string of a URL and the user sends this URL to another user by e-mail, those preferences will be used for that other user as well.
Moreover, if the same user accesses the same page multiple times from different sources, there is no guarantee that the same query string will be used each time. For example, if a user visits a page by coming from a page internal to the site the first time, and then visits the same page by coming from an external search engine the second time, the query strings would likely be different. If cookies were used in this situation, the cookies would be the same.
Other drawbacks of query strings are related to security. Storing data that identifies a session in a query string enables session fixation attacks, referer logging attacks and other security exploits. Transferring session identifiers as HTTP cookies is more secure.
Hidden form fields:
Another form of session tracking is to use web forms with hidden fields. This technique is very similar to using URL query strings to hold the information and has many of the same advantages and drawbacks.
In fact, if the form is handled with the HTTP GET method, then this technique is similar to using URL query strings, since the GET method adds the form fields to the URL as a query string. But most forms are handled with HTTP POST, which causes the form information, including the hidden fields, to be sent in the HTTP request body, which is neither part of the URL, nor of a cookie.
This approach presents two advantages from the point of view of the tracker:
- Having the tracking information placed in the HTTP request body rather than in the URL means it will not be noticed by the average user.
- The session information is not copied when the user copies the URL (to bookmark the page or send it via email, for example).
"window.name" DOM property:
All current web browsers can store a fairly large amount of data (2–32 MB) via JavaScript using the DOM property window.name. This data can be used instead of session cookies and is also cross-domain. The technique can be coupled with JSON/JavaScript objects to store complex sets of session variables on the client side.
The downside is that every separate window or tab will initially have an empty window.name property when opened. Furthermore, the property can be used for tracking visitors across different websites, making it of concern for Internet privacy.
In some respects, this can be more secure than cookies due to the fact that its contents are not automatically sent to the server on every request like cookies are, so it is not vulnerable to network cookie sniffing attacks. However, if special measures are not taken to protect the data, it is vulnerable to other attacks because the data is available across different websites opened in the same window or tab.
Identifier for advertisers:
Apple uses a tracking technique called "identifier for advertisers" (IDFA). This technique assigns a unique identifier to every user that buys an Apple iOS device (such as an iPhone or iPad). This identifier is then used by Apple's advertising network, iAd, to determine the ads that individuals are viewing and responding to.
ETagMain:
Article: HTTP ETag § Tracking using ETags
Because ETags are cached by the browser, and returned with subsequent requests for the same resource, a tracking server can simply repeat any ETag received from the browser to ensure an assigned ETag persists indefinitely (in a similar way to persistent cookies). Additional caching headers can also enhance the preservation of ETag data.
ETags can be flushed in some browsers by clearing the browser cache.
Web storage:
Main article: Web storage
Some web browsers support persistence mechanisms which allow the page to store the information locally for later use.
The HTML5 standard (which most modern web browsers support to some extent) includes a JavaScript API called Web storage that allows two types of storage: local storage and session storage.
Local storage behaves similarly to persistent cookies while session storage behaves similarly to session cookies, except that session storage is tied to an individual tab/window's lifetime (AKA a page session), not to a whole browser session like session cookies.
Internet Explorer supports persistent information in the browser's history, in the browser's favorites, in an XML store ("user data"), or directly within a web page saved to disk.
Some web browser plugins include persistence mechanisms as well. For example, Adobe Flash has Local shared object and Microsoft Silverlight has Isolated storage.
Browser cache:
Main article: Web cache
The browser cache can also be used to store information that can be used to track individual users. This technique takes advantage of the fact that the web browser will use resources stored within the cache instead of downloading them from the website when it determines that the cache already has the most up-to-date version of the resource.
For example, a website could serve a JavaScript file that contains code which sets a unique identifier for the user (for example, var userId = 3243242;). After the user's initial visit, every time the user accesses the page, this file will be loaded from the cache instead of downloaded from the server. Thus, its content will never change.
Browser fingerprint:
Main article: Device fingerprint
A browser fingerprint is information collected about a browser's configuration, such as version number, screen resolution, and operating system, for the purpose of identification. Fingerprints can be used to fully or partially identify individual users or devices even when cookies are turned off.
Basic web browser configuration information has long been collected by web analytics services in an effort to accurately measure real human web traffic and discount various forms of click fraud.
With the assistance of client-side scripting languages, collection of much more esoteric parameters is possible. Assimilation of such information into a single string comprises a device fingerprint.
In 2010, EFF measured at least 18.1 bits of entropy possible from browser fingerprinting. Canvas fingerprinting, a more recent technique, claims to add another 5.7 bits.
See also:
- Dynamic HTML
- Enterprise JavaBeans
- Session (computer science)
- Secure cookies
- RFC 6265, the current official specification for HTTP cookies
- HTTP cookies, Mozilla Developer Network
- Using cookies via ECMAScript, Mozilla Developer Network
- How Internet Cookies Work at HowStuffWorks
- Cookies at the Electronic Privacy Information Center (EPIC)
- Mozilla Knowledge-Base: Cookies
- Cookie Domain, explain in detail how cookie domains are handled in current major browsers
Buzzfeed.com
YouTube Video: $11 Steak Vs. $306 Steak
BuzzFeed Inc is an American Internet media company based in New York City. The firm is a social news and entertainment company with a focus on digital media.
BuzzFeed was founded in 2006 as a viral lab focusing on tracking viral content, by Jonah Peretti and John S. Johnson III. Kenneth Lerer, co-founder and chairman of The Huffington Post, started as a co-founder and investor in BuzzFeed and is now the executive chairman as well.
The company has grown into a global media and technology company providing coverage on a variety of topics including politics, DIY, animals and business. In late 2011, Ben Smith of Politico was hired as editor-in-chief to expand the site into serious journalism, long-form journalism, and reportage.
History:
Founding:
Prior to establishing BuzzFeed, Peretti was director of research and development and the OpenLab at Eyebeam, Johnson's New York City-based art and technology nonprofit, where he experimented with other viral media.
While working at the Huffington Post, Peretti started BuzzFeed as a side project, in 2006, in partnership with his former supervisor John Johnson. In the beginning, BuzzFeed employed no writers or editors, just an "algorithm to cull stories from around the web that were showing stirrings of virality."
The site initially launched an instant messaging client, BuzzBot, which messaged users a link to popular content. The messages were sent based on algorithms which examined the links that were being quickly disseminated, scouring through the feeds of hundreds of blogs that were aggregating them.
Later, the site began spotlighting the most popular links that BuzzBot found. Peretti hired curators to help describe the content that was popular around the web. In 2011, Peretti hired Politico's Ben Smith, who earlier had achieved much attention as a political blogger, to assemble a news operation in addition to the many aggregated "listicles".
Funding:
In August 2014, BuzzFeed raised $50 million from the venture capital firm Andreessen Horowitz, more than doubling previous rounds of funding. The site was reportedly valued at around $850 million by Andreessen Horowitz.
BuzzFeed generates its advertising revenue through native advertising that matches its own editorial content, and does not rely on banner ads. BuzzFeed also uses its familiarity with social media to target conventional advertising through other channels, such as Facebook.
In December 2014, growth equity firm General Atlantic acquired $50M in secondary stock of the company.
In August 2015, NBCUniversal made a $200 million equity investment in BuzzFeed. Along with plans to hire more journalists to build a more prominent "investigative" unit, BuzzFeed is hiring journalists around the world and plans to open outposts in India, Germany, Mexico, and Japan.
In October 2016, BuzzFeed raised $200 million from Comcast’s TV and movie arm NBCUniversal, at a valuation of roughly $1.7 billion.
Acquisitions:
BuzzFeed's first acquisition was in 2012 when the company purchased Kingfish Labs, a startup founded by Rob Fishman, initially focused on optimizing Facebook ads.
On October 28, 2014, BuzzFeed announced its next acquisition, taking hold of Torando Labs. The Torando team was to become BuzzFeed's first data engineering team.
Content:
BuzzFeed produces daily content, in which the work of staff reporters, contributors, syndicated cartoon artists, and its community are featured. Popular formats on the website include lists, videos, and quizzes.
While BuzzFeed initially was focused exclusively on such viral content, according to The New York Times, "it added more traditional content, building a track record for delivering breaking news and deeply reported articles" in the years up to 2014. In that year, BuzzFeed deleted over 4000 early posts, "apparently because, as time passed, they looked stupider and stupider", as observed by The New Yorker.
BuzzFeed consistently ranked at the top of NewsWhip's "Facebook Publisher Rankings" from December 2013 to April 2014, until The Huffington Post entered the position.
Video:
BuzzFeed Video, BuzzFeed Motion Picture's flagship channel, produces original content. Its production studio and team are based in Los Angeles. Since hiring Ze Frank in 2012, BuzzFeed Video has produced several video series including "The Try Guys".
In August 2014, the company announced a new division, BuzzFeed Motion Pictures, which may produce feature-length films. As of June 27, 2017, BuzzFeed Video's YouTube had garnered more than 10.2 billion views and more than 12.6 million subscribers. It recently was announced that YouTube has signed on for two feature length series to be created by BuzzFeed Motion Pictures, entitled Broke and Squad Wars.
Community:
On July 17, 2012, humor website McSweeney's Internet Tendency published a satirical piece entitled "Suggested BuzzFeed Articles", prompting BuzzFeed to create many of the suggestions.
BuzzFeed listed McSweeney's as a "Community Contributor."The post subsequently received more than 350,000 page views, prompted BuzzFeed to ask for user submissions, and received media attention.
Subsequently, the website launched the "Community" section in May 2013 to enable users to submit content. Users initially are limited to publishing only one post per day, but may increase their submission capacity by raising their "Cat Power", described on the BuzzFeed website as "an official measure of your rank in BuzzFeed's Community." A user's Cat Power increases as they achieve greater prominence on the site.
Technology and social media:
BuzzFeed receives the majority of its traffic by creating content that is shared on social media websites. BuzzFeed works by judging their content on how viral it will become.
Operating in a “continuous feedback loop” where all of its articles and videos are used as input for its sophisticated data operation. The site continues to test and track their custom content with an in-house team of data scientists and external-facing “social dashboard.”
Using an algorithm dubbed "Viral Rank" created by Jonah Peretti and Duncan Watts, the company uses this formula to let editors, users, and advertisers try lots of different ideas, which maximizes distribution. Staff writers are ranked by views on an internal leaderboard.
In 2014, BuzzFeed received 75% of its views from links on social media outlets such as Pinterest, Twitter, and Facebook.
Tasty:
BuzzFeed's video series on comfort food, Tasty, is made for Facebook, where it has ninety million followers as of November 2017.
The channel has substantially more views than BuzzFeed's dedicated food site. The channel included five spinoff segments: "Tasty Junior"—which eventually spun off into its own page, "Tasty Happy Hour" (alcoholic beverages), "Tasty Fresh", "Tasty Vegetarian", and "Tasty Story"—which has celebrities making and discussing their own recipes. Tasty has also released a cookbook. The company also operates these international versions of Tasty in other languages.
Worth It:
Since 2016, Tasty also sponsors a show named "Worth It" starring Steven Lim, Andrew Ilnyckyj, and Adam Bianchi. In each episode, the trio visit three different food places with three different price points in one food category.
Steven Lim also stars on some of BuzzFeed Blue's "Worth It - Lifestyle" videos. The series is similar, in that three items or experiences are valued from different companies, each at their different price point, but focus on material items and experiences, such as plane seats, hotel rooms, and haircuts.
BuzzFeed Unsolved:
BuzzFeed Unsolved is the most successful web series on BuzzFeed's BuzzFeedBlue, created by Ryan Bergara. The show features Ryan Bergara, Shane Madej, and occasionally Brent Bennett.
Notable Stories:
Trump dossier:
Main article: Donald Trump–Russia dossier
On January 10, 2017, CNN reported on the existence of classified documents that claimed Russia had compromising personal and financial information about President-elect Donald Trump. Both Trump and President Barack Obama had been briefed on the content of the dossier the previous week. CNN did not publish the dossier, or any specific details of the dossier, as they could not be verified.
Later the same day, BuzzFeed published a 35-page dossier nearly in-full. BuzzFeed said that the dossier was unverified and "includes some clear errors". The dossier had been read widely by political and media figures in Washington, and previously been sent to multiple journalists who had declined to publish it as unsubstantiated.
In response the next day, Trump called the website a "failing pile of garbage" during a news conference. The publication of the dossier was also met with criticism from, among others, CNN reporter Jake Tapper, who called it irresponsible. BuzzFeed editor-in-chief Ben Smith defended the site's decision to publish the dossier.
Aleksej Gubarev, chief of technology company XBT and a figure mentioned in the dossier, sued BuzzFeed on February 3, 2017. The suit, filed in a Broward County, Florida court, centers on the allegations from the dossier that XBT had been "using botnets and porn traffic to transmit viruses, plant bugs, steal data and conduct 'altering operations' against the Democratic Party leadership."
Traingate:
In September 2016, Private Eye revealed that a Guardian story from August 16 on "Traingate" was written by a former Socialist Workers Party member who joined the Labour Party once Jeremy Corbyn became Labour leader.
The journalist also had a conflict of interest with the individual who filmed Corbyn on the floor of an allegedly-overcrowded train, something the Guardian did not mention in its reporting. Paul Chadwich, the global readers editor for the Guardian, later stated that the story was published too quickly, with aspects of the story not being corroborated by third-party sources prior to reporting. The story proved to be an embarrassment for Corbyn and the Guardian.
The story originally was submitted to BuzzFeed News, who rejected the article because its author had "attached a load of conditions around the words and he wanted it written his way", according to BuzzFeed UK editor-in-chief Janine Gibson.
Watermelon stunt:
Main article: Exploding watermelon stunt
On April 8, 2016, two BuzzFeed interns created a live stream on Facebook, during which rubber bands were wrapped one by one around a watermelon until the pressure caused it to explode. The Daily Dot compared it to something from America's Funniest Home Videosor by the comedian Gallagher, and "just as stupid-funny, but with incredible immediacy and zero production costs".
The video is seen as part of Facebook's strategy to shift to live video, Facebook Live, to counter the rise of Snapchat and Periscope among a younger audience.
"The dress":
Main article: The dress
In February 2015, a post resulting in a debate over the color of an item of clothing from BuzzFeed's Tumblr editor Cates Holderness garnered more than 28 million views in one day, setting a record for most concurrent visitors to a BuzzFeed post.
Holderness had showed the picture to other members of the site's social media team, who immediately began arguing about the dress colors among themselves. After creating a simple poll for users of the site, she left work and took the subway back to her Brooklyn home.
When she got off the train and checked her telephone, it was overwhelmed by the messages on various sites. "I couldn't open Twitter because it kept crashing. I thought somebody had died, maybe. I didn't know what was going on." Later in the evening the page set a new record at BuzzFeed for concurrent visitors, which would reach 673,000 at its peak.
Leaked Milo Yiannopoulos emails:
An exposé by BuzzFeed published in October 2017 documented how Breitbart News solicited story ideas and copy edits from white supremacists and neo-Nazis, with Milo Yiannopoulos acting as an intermediary.
Yiannopoulos and other Breitbart employees developed and marketed the values and tactics of these groups, attempting to make them palatable to a broader audience. In the article, BuzzFeed senior technology reporter Joseph Bernstein wrote that Breitbart actively fed from the "most hate-filled, racist voices of the alt-right" and helped to normalize the American far right.
MSNBC's Chris Hayes called the 8,500-word article "one of the best reported pieces of the year." The Columbia Journalism Review described the story as a scrupulous, months-long project and "the culmination of years of reporting and source-building on a beat that few thought much about until Donald Trump won the presidential election."
Kevin Spacey sexual misconduct accusation:
On October 29, 2017, BuzzFeed published the original story in which actor Anthony Rapp accused actor Kevin Spacey of making sexual advances toward him at a party in 1986 when Rapp was 14 at the time and Spacey was 26.
Subsequently, numerous other men alleged that Spacey had sexually harassed or assaulted them. As a result, Netflix indefinitely suspended production of Spacey's TV series House of Cards, and opted to not release his film Gore on their service, which was in post-production at the time, and Spacey was replaced by Christopher Plummer in Ridley Scott's film All the Money in the World, which was six weeks from release.
Criticism and Controversies:
BuzzFeed has been accused of plagiarizing original content from competitors throughout the online and offline press. On June 28, 2012, Gawker's Adrian Chen posted a story entitled "BuzzFeed and the Plagiarism Problem". In the article, Chen observed that one of BuzzFeed's most popular writers--Matt Stopera—frequently had copied and pasted "chunks of text into lists without attribution." On March 8, 2013, The Atlantic Wire also published an article concerning BuzzFeed and plagiarism issues.
BuzzFeed has been the subject of multiple copyright infringement lawsuits, for both using content it had no rights to and encouraging its proliferation without attributing its sources: one for an individual photographer's photograph, and another for nine celebrity photographs from a single photography company.
In July 2014, BuzzFeed writer Benny Johnson was accused of multiple instances of plagiarism. Two anonymous Twitter users chronicled Johnson attributing work that was not his own, but "directly lift[ed] from other reporters, Wikipedia, and Yahoo! Answers," all without credit.
BuzzFeed editor Ben Smith initially defended Johnson, calling him a "deeply original writer". Days later, Smith acknowledged that Johnson had plagiarized the work of others 40 times and announced that Johnson had been fired, and apologized to BuzzFeed readers.
"Plagiarism, much less copying unchecked facts from Wikipedia or other sources, is an act of disrespect to the reader," Smith said. "We are deeply embarrassed and sorry to have misled you." In total, 41 instances of plagiarism were found and corrected. Johnson, who had previously worked for the Mitt Romney 2008 presidential campaign, subsequently, was hired by the conservative magazine National Review as their social media editor.
In October 2014, it was noted by the Pew Research Center that in the United States, BuzzFeed was viewed as an unreliable source by the majority of people, regardless of political affiliation.
In April 2015, BuzzFeed drew scrutiny after Gawker observed the publication had deleted two posts that criticized advertisers. One of the posts criticized Dove soap (manufactured by Unilever), while another criticized Hasbro. Both companies advertise with BuzzFeed.
Ben Smith apologized in a memo to staff for his actions. "I blew it," Smith wrote. "Twice in the past couple of months, I've asked editors—over their better judgment and without any respect to our standards or process—to delete recently published posts from the site. Both involved the same thing: my overreaction to questions we've been wrestling with about the place of personal opinion pieces on our site. I reacted impulsively when I saw the posts and I was wrong to do that. We've reinstated both with a brief note."
Days later, one of the authors of the deleted posts, Arabelle Sicardi, resigned. An internal review by the company found three additional posts deleted for being critical of products or advertisements (by Microsoft, Pepsi, and Unilever).
In September 2015, The Christian Post wrote that a video by BuzzFeed entitled I'm Christian But I'm Not... was getting criticism from conservative Christians for not specifically mentioning Christ or certain Biblical values.
In 2016, the Advertising Standards Authority of the United Kingdom ruled that BuzzFeed broke the UK advertising rules for failing to make it clear that an article on "14 Laundry Fails We've All Experienced" that promoted Dylon was an online advertorial paid for by the brand.
Although the ASA agreed with BuzzFeed's defence that links to the piece from its homepage and search results clearly labelled the article as "sponsored content", this failed to take into account that many people may link to the story directly, ruling that the labeling "was not sufficient to make clear that the main content of the web page was an advertorial and that editorial content was therefore retained by the advertiser".
In February 2016, Scaachi Koul, a Senior Writer for BuzzFeed Canada tweeted a request for pitches stating that BuzzFeed was "...looking for mostly non-white non-men" followed by "If you are a white man upset that we are looking mostly for non-white non-men I don't care about you go write for Maclean's."
When confronted, she followed with the tweet "White men are still permitted to pitch, I will read it, I will consider it. I'm just less interested because, ugh, men." In response to the tweets, Koul received numerous rape and death threats and racist insults.
Sarmishta Subramanian, a former colleague of Koul's writing for Maclean's condemned the reaction to the tweets, and commented that Koul's request for diversity was appropriate. Subramanian said that her provocative approach raised concerns of tokenism that might hamper BuzzFeed's stated goals.
See also:
BuzzFeed was founded in 2006 as a viral lab focusing on tracking viral content, by Jonah Peretti and John S. Johnson III. Kenneth Lerer, co-founder and chairman of The Huffington Post, started as a co-founder and investor in BuzzFeed and is now the executive chairman as well.
The company has grown into a global media and technology company providing coverage on a variety of topics including politics, DIY, animals and business. In late 2011, Ben Smith of Politico was hired as editor-in-chief to expand the site into serious journalism, long-form journalism, and reportage.
History:
Founding:
Prior to establishing BuzzFeed, Peretti was director of research and development and the OpenLab at Eyebeam, Johnson's New York City-based art and technology nonprofit, where he experimented with other viral media.
While working at the Huffington Post, Peretti started BuzzFeed as a side project, in 2006, in partnership with his former supervisor John Johnson. In the beginning, BuzzFeed employed no writers or editors, just an "algorithm to cull stories from around the web that were showing stirrings of virality."
The site initially launched an instant messaging client, BuzzBot, which messaged users a link to popular content. The messages were sent based on algorithms which examined the links that were being quickly disseminated, scouring through the feeds of hundreds of blogs that were aggregating them.
Later, the site began spotlighting the most popular links that BuzzBot found. Peretti hired curators to help describe the content that was popular around the web. In 2011, Peretti hired Politico's Ben Smith, who earlier had achieved much attention as a political blogger, to assemble a news operation in addition to the many aggregated "listicles".
Funding:
In August 2014, BuzzFeed raised $50 million from the venture capital firm Andreessen Horowitz, more than doubling previous rounds of funding. The site was reportedly valued at around $850 million by Andreessen Horowitz.
BuzzFeed generates its advertising revenue through native advertising that matches its own editorial content, and does not rely on banner ads. BuzzFeed also uses its familiarity with social media to target conventional advertising through other channels, such as Facebook.
In December 2014, growth equity firm General Atlantic acquired $50M in secondary stock of the company.
In August 2015, NBCUniversal made a $200 million equity investment in BuzzFeed. Along with plans to hire more journalists to build a more prominent "investigative" unit, BuzzFeed is hiring journalists around the world and plans to open outposts in India, Germany, Mexico, and Japan.
In October 2016, BuzzFeed raised $200 million from Comcast’s TV and movie arm NBCUniversal, at a valuation of roughly $1.7 billion.
Acquisitions:
BuzzFeed's first acquisition was in 2012 when the company purchased Kingfish Labs, a startup founded by Rob Fishman, initially focused on optimizing Facebook ads.
On October 28, 2014, BuzzFeed announced its next acquisition, taking hold of Torando Labs. The Torando team was to become BuzzFeed's first data engineering team.
Content:
BuzzFeed produces daily content, in which the work of staff reporters, contributors, syndicated cartoon artists, and its community are featured. Popular formats on the website include lists, videos, and quizzes.
While BuzzFeed initially was focused exclusively on such viral content, according to The New York Times, "it added more traditional content, building a track record for delivering breaking news and deeply reported articles" in the years up to 2014. In that year, BuzzFeed deleted over 4000 early posts, "apparently because, as time passed, they looked stupider and stupider", as observed by The New Yorker.
BuzzFeed consistently ranked at the top of NewsWhip's "Facebook Publisher Rankings" from December 2013 to April 2014, until The Huffington Post entered the position.
Video:
BuzzFeed Video, BuzzFeed Motion Picture's flagship channel, produces original content. Its production studio and team are based in Los Angeles. Since hiring Ze Frank in 2012, BuzzFeed Video has produced several video series including "The Try Guys".
In August 2014, the company announced a new division, BuzzFeed Motion Pictures, which may produce feature-length films. As of June 27, 2017, BuzzFeed Video's YouTube had garnered more than 10.2 billion views and more than 12.6 million subscribers. It recently was announced that YouTube has signed on for two feature length series to be created by BuzzFeed Motion Pictures, entitled Broke and Squad Wars.
Community:
On July 17, 2012, humor website McSweeney's Internet Tendency published a satirical piece entitled "Suggested BuzzFeed Articles", prompting BuzzFeed to create many of the suggestions.
BuzzFeed listed McSweeney's as a "Community Contributor."The post subsequently received more than 350,000 page views, prompted BuzzFeed to ask for user submissions, and received media attention.
Subsequently, the website launched the "Community" section in May 2013 to enable users to submit content. Users initially are limited to publishing only one post per day, but may increase their submission capacity by raising their "Cat Power", described on the BuzzFeed website as "an official measure of your rank in BuzzFeed's Community." A user's Cat Power increases as they achieve greater prominence on the site.
Technology and social media:
BuzzFeed receives the majority of its traffic by creating content that is shared on social media websites. BuzzFeed works by judging their content on how viral it will become.
Operating in a “continuous feedback loop” where all of its articles and videos are used as input for its sophisticated data operation. The site continues to test and track their custom content with an in-house team of data scientists and external-facing “social dashboard.”
Using an algorithm dubbed "Viral Rank" created by Jonah Peretti and Duncan Watts, the company uses this formula to let editors, users, and advertisers try lots of different ideas, which maximizes distribution. Staff writers are ranked by views on an internal leaderboard.
In 2014, BuzzFeed received 75% of its views from links on social media outlets such as Pinterest, Twitter, and Facebook.
Tasty:
BuzzFeed's video series on comfort food, Tasty, is made for Facebook, where it has ninety million followers as of November 2017.
The channel has substantially more views than BuzzFeed's dedicated food site. The channel included five spinoff segments: "Tasty Junior"—which eventually spun off into its own page, "Tasty Happy Hour" (alcoholic beverages), "Tasty Fresh", "Tasty Vegetarian", and "Tasty Story"—which has celebrities making and discussing their own recipes. Tasty has also released a cookbook. The company also operates these international versions of Tasty in other languages.
Worth It:
Since 2016, Tasty also sponsors a show named "Worth It" starring Steven Lim, Andrew Ilnyckyj, and Adam Bianchi. In each episode, the trio visit three different food places with three different price points in one food category.
Steven Lim also stars on some of BuzzFeed Blue's "Worth It - Lifestyle" videos. The series is similar, in that three items or experiences are valued from different companies, each at their different price point, but focus on material items and experiences, such as plane seats, hotel rooms, and haircuts.
BuzzFeed Unsolved:
BuzzFeed Unsolved is the most successful web series on BuzzFeed's BuzzFeedBlue, created by Ryan Bergara. The show features Ryan Bergara, Shane Madej, and occasionally Brent Bennett.
Notable Stories:
Trump dossier:
Main article: Donald Trump–Russia dossier
On January 10, 2017, CNN reported on the existence of classified documents that claimed Russia had compromising personal and financial information about President-elect Donald Trump. Both Trump and President Barack Obama had been briefed on the content of the dossier the previous week. CNN did not publish the dossier, or any specific details of the dossier, as they could not be verified.
Later the same day, BuzzFeed published a 35-page dossier nearly in-full. BuzzFeed said that the dossier was unverified and "includes some clear errors". The dossier had been read widely by political and media figures in Washington, and previously been sent to multiple journalists who had declined to publish it as unsubstantiated.
In response the next day, Trump called the website a "failing pile of garbage" during a news conference. The publication of the dossier was also met with criticism from, among others, CNN reporter Jake Tapper, who called it irresponsible. BuzzFeed editor-in-chief Ben Smith defended the site's decision to publish the dossier.
Aleksej Gubarev, chief of technology company XBT and a figure mentioned in the dossier, sued BuzzFeed on February 3, 2017. The suit, filed in a Broward County, Florida court, centers on the allegations from the dossier that XBT had been "using botnets and porn traffic to transmit viruses, plant bugs, steal data and conduct 'altering operations' against the Democratic Party leadership."
Traingate:
In September 2016, Private Eye revealed that a Guardian story from August 16 on "Traingate" was written by a former Socialist Workers Party member who joined the Labour Party once Jeremy Corbyn became Labour leader.
The journalist also had a conflict of interest with the individual who filmed Corbyn on the floor of an allegedly-overcrowded train, something the Guardian did not mention in its reporting. Paul Chadwich, the global readers editor for the Guardian, later stated that the story was published too quickly, with aspects of the story not being corroborated by third-party sources prior to reporting. The story proved to be an embarrassment for Corbyn and the Guardian.
The story originally was submitted to BuzzFeed News, who rejected the article because its author had "attached a load of conditions around the words and he wanted it written his way", according to BuzzFeed UK editor-in-chief Janine Gibson.
Watermelon stunt:
Main article: Exploding watermelon stunt
On April 8, 2016, two BuzzFeed interns created a live stream on Facebook, during which rubber bands were wrapped one by one around a watermelon until the pressure caused it to explode. The Daily Dot compared it to something from America's Funniest Home Videosor by the comedian Gallagher, and "just as stupid-funny, but with incredible immediacy and zero production costs".
The video is seen as part of Facebook's strategy to shift to live video, Facebook Live, to counter the rise of Snapchat and Periscope among a younger audience.
"The dress":
Main article: The dress
In February 2015, a post resulting in a debate over the color of an item of clothing from BuzzFeed's Tumblr editor Cates Holderness garnered more than 28 million views in one day, setting a record for most concurrent visitors to a BuzzFeed post.
Holderness had showed the picture to other members of the site's social media team, who immediately began arguing about the dress colors among themselves. After creating a simple poll for users of the site, she left work and took the subway back to her Brooklyn home.
When she got off the train and checked her telephone, it was overwhelmed by the messages on various sites. "I couldn't open Twitter because it kept crashing. I thought somebody had died, maybe. I didn't know what was going on." Later in the evening the page set a new record at BuzzFeed for concurrent visitors, which would reach 673,000 at its peak.
Leaked Milo Yiannopoulos emails:
An exposé by BuzzFeed published in October 2017 documented how Breitbart News solicited story ideas and copy edits from white supremacists and neo-Nazis, with Milo Yiannopoulos acting as an intermediary.
Yiannopoulos and other Breitbart employees developed and marketed the values and tactics of these groups, attempting to make them palatable to a broader audience. In the article, BuzzFeed senior technology reporter Joseph Bernstein wrote that Breitbart actively fed from the "most hate-filled, racist voices of the alt-right" and helped to normalize the American far right.
MSNBC's Chris Hayes called the 8,500-word article "one of the best reported pieces of the year." The Columbia Journalism Review described the story as a scrupulous, months-long project and "the culmination of years of reporting and source-building on a beat that few thought much about until Donald Trump won the presidential election."
Kevin Spacey sexual misconduct accusation:
On October 29, 2017, BuzzFeed published the original story in which actor Anthony Rapp accused actor Kevin Spacey of making sexual advances toward him at a party in 1986 when Rapp was 14 at the time and Spacey was 26.
Subsequently, numerous other men alleged that Spacey had sexually harassed or assaulted them. As a result, Netflix indefinitely suspended production of Spacey's TV series House of Cards, and opted to not release his film Gore on their service, which was in post-production at the time, and Spacey was replaced by Christopher Plummer in Ridley Scott's film All the Money in the World, which was six weeks from release.
Criticism and Controversies:
BuzzFeed has been accused of plagiarizing original content from competitors throughout the online and offline press. On June 28, 2012, Gawker's Adrian Chen posted a story entitled "BuzzFeed and the Plagiarism Problem". In the article, Chen observed that one of BuzzFeed's most popular writers--Matt Stopera—frequently had copied and pasted "chunks of text into lists without attribution." On March 8, 2013, The Atlantic Wire also published an article concerning BuzzFeed and plagiarism issues.
BuzzFeed has been the subject of multiple copyright infringement lawsuits, for both using content it had no rights to and encouraging its proliferation without attributing its sources: one for an individual photographer's photograph, and another for nine celebrity photographs from a single photography company.
In July 2014, BuzzFeed writer Benny Johnson was accused of multiple instances of plagiarism. Two anonymous Twitter users chronicled Johnson attributing work that was not his own, but "directly lift[ed] from other reporters, Wikipedia, and Yahoo! Answers," all without credit.
BuzzFeed editor Ben Smith initially defended Johnson, calling him a "deeply original writer". Days later, Smith acknowledged that Johnson had plagiarized the work of others 40 times and announced that Johnson had been fired, and apologized to BuzzFeed readers.
"Plagiarism, much less copying unchecked facts from Wikipedia or other sources, is an act of disrespect to the reader," Smith said. "We are deeply embarrassed and sorry to have misled you." In total, 41 instances of plagiarism were found and corrected. Johnson, who had previously worked for the Mitt Romney 2008 presidential campaign, subsequently, was hired by the conservative magazine National Review as their social media editor.
In October 2014, it was noted by the Pew Research Center that in the United States, BuzzFeed was viewed as an unreliable source by the majority of people, regardless of political affiliation.
In April 2015, BuzzFeed drew scrutiny after Gawker observed the publication had deleted two posts that criticized advertisers. One of the posts criticized Dove soap (manufactured by Unilever), while another criticized Hasbro. Both companies advertise with BuzzFeed.
Ben Smith apologized in a memo to staff for his actions. "I blew it," Smith wrote. "Twice in the past couple of months, I've asked editors—over their better judgment and without any respect to our standards or process—to delete recently published posts from the site. Both involved the same thing: my overreaction to questions we've been wrestling with about the place of personal opinion pieces on our site. I reacted impulsively when I saw the posts and I was wrong to do that. We've reinstated both with a brief note."
Days later, one of the authors of the deleted posts, Arabelle Sicardi, resigned. An internal review by the company found three additional posts deleted for being critical of products or advertisements (by Microsoft, Pepsi, and Unilever).
In September 2015, The Christian Post wrote that a video by BuzzFeed entitled I'm Christian But I'm Not... was getting criticism from conservative Christians for not specifically mentioning Christ or certain Biblical values.
In 2016, the Advertising Standards Authority of the United Kingdom ruled that BuzzFeed broke the UK advertising rules for failing to make it clear that an article on "14 Laundry Fails We've All Experienced" that promoted Dylon was an online advertorial paid for by the brand.
Although the ASA agreed with BuzzFeed's defence that links to the piece from its homepage and search results clearly labelled the article as "sponsored content", this failed to take into account that many people may link to the story directly, ruling that the labeling "was not sufficient to make clear that the main content of the web page was an advertorial and that editorial content was therefore retained by the advertiser".
In February 2016, Scaachi Koul, a Senior Writer for BuzzFeed Canada tweeted a request for pitches stating that BuzzFeed was "...looking for mostly non-white non-men" followed by "If you are a white man upset that we are looking mostly for non-white non-men I don't care about you go write for Maclean's."
When confronted, she followed with the tweet "White men are still permitted to pitch, I will read it, I will consider it. I'm just less interested because, ugh, men." In response to the tweets, Koul received numerous rape and death threats and racist insults.
Sarmishta Subramanian, a former colleague of Koul's writing for Maclean's condemned the reaction to the tweets, and commented that Koul's request for diversity was appropriate. Subramanian said that her provocative approach raised concerns of tokenism that might hamper BuzzFeed's stated goals.
See also:
- Official website
- ClickHole, a parody of BuzzFeed and similar websites
- Mic (media company)
- Vice Media, Inc.
Fandango
YouTube Video: Easy Movie Tickets with Fandango

Fandango is an American ticketing company that sells movie tickets via their website as well as through their mobile app.
Hi Industry revenue increased rapidly for several years after the company's formation. However, as the Internet grew in popularity, small- and medium-sized movie-theater chains began to offer independent ticket sale capabilities through their own websites.
In addition, a new paradigm of moviegoers printing their own tickets at home (with barcodes to be scanned at the theater) emerged, in services offered by PrintTixUSA and by point-of-sale software vendor operated web sites like "ticketmakers.com" (and eventually Fandango itself).
Finally, an overall slump in moviegoing continued into the 2000s, as home theaters, DVDs, and high definition televisions proliferated in average households, turning the home into the preferred place to screen films.
On April 11, 2007, Comcast acquired Fandango, with plans to integrate it into a new entertainment website called "Fancast.com," set to launch the summer of 2007. In June 2008, the domain Movies.com was acquired from Disney. With Comcast's purchase of a stake in NBCUniversal in January 2011, Fandango and all other Comcast media assets were merged into the company.
In March 2012, Fandango announced a partnership with Yahoo! Movies, becoming the official online and mobile ticketer serving over 30 million registered users of the Yahoo! service.
On January 29, 2016, Fandango announced its acquisition of M-GO, a joint venture between Technicolor SA and DreamWorks Animation (which NBCUniversal acquired the company three months later), which it would later rebrand as "FandangoNOW".
In February of that same year Fandango announced its acquisition of Flixster and Rotten Tomatoes from Time Warner's Warner Bros. Entertainment. As part of the deal, Warner Bros. would become a 30% shareholder of the combined Fandango company.
In December 2016, Fandango Media purchased Cinepapaya, a Peru-based website for purchasing movie tickets, for an undisclosed amount.
Click on any of the following blue hyperlinks for more about the website Fandango:
Hi Industry revenue increased rapidly for several years after the company's formation. However, as the Internet grew in popularity, small- and medium-sized movie-theater chains began to offer independent ticket sale capabilities through their own websites.
In addition, a new paradigm of moviegoers printing their own tickets at home (with barcodes to be scanned at the theater) emerged, in services offered by PrintTixUSA and by point-of-sale software vendor operated web sites like "ticketmakers.com" (and eventually Fandango itself).
Finally, an overall slump in moviegoing continued into the 2000s, as home theaters, DVDs, and high definition televisions proliferated in average households, turning the home into the preferred place to screen films.
On April 11, 2007, Comcast acquired Fandango, with plans to integrate it into a new entertainment website called "Fancast.com," set to launch the summer of 2007. In June 2008, the domain Movies.com was acquired from Disney. With Comcast's purchase of a stake in NBCUniversal in January 2011, Fandango and all other Comcast media assets were merged into the company.
In March 2012, Fandango announced a partnership with Yahoo! Movies, becoming the official online and mobile ticketer serving over 30 million registered users of the Yahoo! service.
On January 29, 2016, Fandango announced its acquisition of M-GO, a joint venture between Technicolor SA and DreamWorks Animation (which NBCUniversal acquired the company three months later), which it would later rebrand as "FandangoNOW".
In February of that same year Fandango announced its acquisition of Flixster and Rotten Tomatoes from Time Warner's Warner Bros. Entertainment. As part of the deal, Warner Bros. would become a 30% shareholder of the combined Fandango company.
In December 2016, Fandango Media purchased Cinepapaya, a Peru-based website for purchasing movie tickets, for an undisclosed amount.
Click on any of the following blue hyperlinks for more about the website Fandango:
Online Advertising
YouTube Video: Buyer Beware -- The Pitfalls of Online Advertising
Pictured: This chart presents the digital advertising spending in the United States from 2011 to 2014, as well as a forecast until 2019, broken down by channel. The source projected that mobile ad spending would grow from 1.57 million U.S. dollars in 2011 to 65.49 billion in 2019.
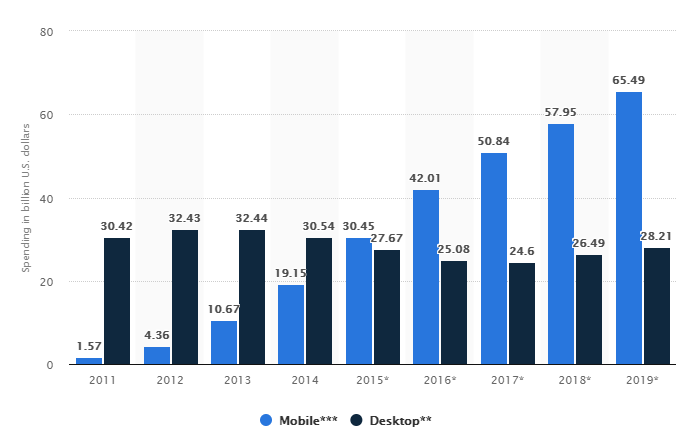
Online advertising, also called online marketing or Internet advertising or web advertising, is a form of marketing and advertising which uses the Internet to deliver promotional marketing messages to consumers. Consumers view online advertising as an unwanted distraction with few benefits and have increasingly turned to ad blocking for a variety of reasons.
It includes the following:
Like other advertising media, online advertising frequently involves both a publisher, who integrates advertisements into its online content, and an advertiser, who provides the advertisements to be displayed on the publisher's content.
Other potential participants include advertising agencies who help generate and place the ad copy, an ad server which technologically delivers the ad and tracks statistics, and advertising affiliates who do independent promotional work for the advertiser.
In 2016, Internet advertising revenues in the United States surpassed those of cable television and broadcast television. In 2017, Internet advertising revenues in the United States totaled $83.0 billion, a 14% increase over the $72.50 billion in revenues in 2016.
Many common online advertising practices are controversial and increasingly subject to regulation. Online ad revenues may not adequately replace other publishers' revenue streams.
Declining ad revenue has led some publishers to hide their content behind paywalls.
Delivery Methods:
Display Advertising:
Display advertising conveys its advertising message visually using text, logos, animations, videos, photographs, or other graphics. Display advertisers frequently target users with particular traits to increase the ads' effect.
Online advertisers (typically through their ad servers) often use cookies, which are unique identifiers of specific computers, to decide which ads to serve to a particular consumer. Cookies can track whether a user left a page without buying anything, so the advertiser can later retarget the user with ads from the site the user visited.
As advertisers collect data across multiple external websites about a user's online activity, they can create a detailed profile of the user's interests to deliver even more targeted advertising. This aggregation of data is called behavioral targeting. Advertisers can also target their audience by using contextual to deliver display ads related to the content of the web page where the ads appear.
Re-targeting, behavioral targeting, and contextual advertising all are designed to increase an advertiser's return on investment, or ROI, over untargeted ads.
Advertisers may also deliver ads based on a user's suspected geography through geotargeting.
A user's IP address communicates some geographic information (at minimum, the user's country or general region). The geographic information from an IP can be supplemented and refined with other proxies or information to narrow the range of possible locations. For example, with mobile devices, advertisers can sometimes use a phone's GPS receiver or the location of nearby mobile towers.
Cookies and other persistent data on a user's machine may provide help narrowing a user's location further.
Web banner advertising:
Web banners or banner ads typically are graphical ads displayed within a web page. Many banner ads are delivered by a central ad server.
Banner ads can use rich media to incorporate video, audio, animations, buttons, forms, or other interactive elements using Java applets, HTML5, Adobe Flash, and other programs.
Frame ad (traditional banner):
Frame ads were the first form of web banners. The colloquial usage of "banner ads" often refers to traditional frame ads. Website publishers incorporate frame ads by setting aside a particular space on the web page. The Interactive Advertising Bureau's Ad Unit Guidelines proposes standardized pixel dimensions for ad units.
Pop-ups/pop-unders:
A pop-up ad is displayed in a new web browser window that opens above a website visitor's initial browser window. A pop-under ad opens a new browser window under a website visitor's initial browser window. Pop-under ads and similar technologies are now advised against by online authorities such as Google, who state that they "do not condone this practice".
Floating ad:
A floating ad, or overlay ad, is a type of rich media advertisement that appears superimposed over the requested website's content. Floating ads may disappear or become less obtrusive after a preset time period.
Expanding ad:
An expanding ad is a rich media frame ad that changes dimensions upon a predefined condition, such as a preset amount of time a visitor spends on a webpage, the user's click on the ad, or the user's mouse movement over the ad. Expanding ads allow advertisers to fit more information into a restricted ad space.
Trick banners:
A trick banner is a banner ad where the ad copy imitates some screen element users commonly encounter, such as an operating system message or popular application message, to induce ad clicks.
Trick banners typically do not mention the advertiser in the initial ad, and thus they are a form of bait-and-switch. Trick banners commonly attract a higher-than-average click-through rate, but tricked users may resent the advertiser for deceiving them.
News Feed Ads:
"News Feed Ads", also called "Sponsored Stories", "Boosted Posts", typically exist on social media platforms that offer a steady stream of information updates ("news feed") in regulated formats (i.e. in similar sized small boxes with a uniform style). Those advertisements are intertwined with non-promoted news that the users are reading through.
These advertisements can be of any content, such as promoting a website, a fan page, an app, or a product. Some examples are:
This display ads format falls into its own category because unlike banner ads which are quite distinguishable, News Feed Ads' format blends well into non-paid news updates. This format of online advertisement yields much higher click-through rates than traditional display ads.
Display advertising process overview:
The process by which online advertising is displayed can involve many parties. In the simplest case, the website publisher selects and serves the ads. Publishers which operate their own advertising departments may use this method.
The ads may be outsourced to an advertising agency under contract with the publisher, and served from the advertising agency's servers.
Alternatively, ad space may be offered for sale in a bidding market using an ad exchange and real-time bidding. This involves many parties interacting automatically in real time. In response to a request from the user's browser, the publisher content server sends the web page content to the user's browser over the Internet.
The page does not yet contain ads, but contains links which cause the user's browser to connect to the publisher ad server to request that the spaces left for ads be filled in with ads. Information identifying the user, such as cookies and the page being viewed, is transmitted to the publisher ad server.
The publisher ad server then communicates with a supply-side platform server. The publisher is offering ad space for sale, so they are considered the supplier. The supply side platform also receives the user's identifying information, which it sends to a data management platform. At the data management platform, the user's identifying information is used to look up demographic information, previous purchases, and other information of interest to advertisers.
Broadly speaking, there are three types of data obtained through such a data management platform:
This customer information is combined and returned to the supply side platform, which can now package up the offer of ad space along with information about the user who will view it. The supply side platform sends that offer to an ad exchange.
The ad exchange puts the offer out for bid to demand-side platforms. Demand side platforms act on behalf of ad agencies, who sell ads which advertise brands. Demand side platforms thus have ads ready to display, and are searching for users to view them.
Bidders get the information about the user ready to view the ad, and decide, based on that information, how much to offer to buy the ad space. According to the Internet Advertising Bureau, a demand side platform has 10 milliseconds to respond to an offer. The ad exchange picks the winning bid and informs both parties.
The ad exchange then passes the link to the ad back through the supply side platform and the publisher's ad server to the user's browser, which then requests the ad content from the agency's ad server. The ad agency can thus confirm that the ad was delivered to the browser.
This is simplified, according to the IAB. Exchanges may try to unload unsold ("remnant") space at low prices through other exchanges. Some agencies maintain semi-permanent pre-cached bids with ad exchanges, and those may be examined before going out to additional demand side platforms for bids.
The process for mobile advertising is different and may involve mobile carriers and handset software manufacturers.
Interstitial:
An interstitial ad displays before a user can access requested content, sometimes while the user is waiting for the content to load. Interstitial ads are a form of interruption marketing.
Text ads:
A text ad displays text-based hyperlinks. Text-based ads may display separately from a web page's primary content, or they can be embedded by hyperlinking individual words or phrases to advertiser's websites. Text ads may also be delivered through email marketing or text message marketing. Text-based ads often render faster than graphical ads and can be harder for ad-blocking software to block.
Search engine marketing (SEM):
Search engine marketing, or SEM, is designed to increase a website's visibility in search engine results pages (SERPs). Search engines provide sponsored results and organic (non-sponsored) results based on a web searcher's query. Search engines often employ visual cues to differentiate sponsored results from organic results. Search engine marketing includes all of an advertiser's actions to make a website's listing more prominent for topical keywords.
Search engine optimization (SEO):
Search engine optimization, or SEO, attempts to improve a website's organic search rankings in SERPs by increasing the website content's relevance to search terms. Search engines regularly update their algorithms to penalize poor quality sites that try to game their rankings, making optimization a moving target for advertisers. Many vendors offer SEO services.
Sponsored search:
Sponsored search (also called sponsored links, search ads, or paid search) allows advertisers to be included in the sponsored results of a search for selected keywords. Search ads are often sold via real-time auctions, where advertisers bid on keywords. In addition to setting a maximum price per keyword, bids may include time, language, geographical, and other constraints.
Search engines originally sold listings in order of highest bids. Modern search engines rank sponsored listings based on a combination of bid price, expected click-through rate, keyword relevancy and site quality.
Social media marketing:
Social media marketing is commercial promotion conducted through social media websites.
Many companies promote their products by posting frequent updates and providing special offers through their social media profiles.
Mobile advertising:
Mobile advertising is ad copy delivered through wireless mobile devices such as smartphones, feature phones, or tablet computers. Mobile advertising may take the form of static or rich media display ads, SMS (Short Message Service) or MMS (Multimedia Messaging Service) ads, mobile search ads, advertising within mobile websites, or ads within mobile applications or games (such as interstitial ads, "advergaming," or application sponsorship).
Industry groups such as the Mobile Marketing Association have attempted to standardize mobile ad unit specifications, similar to the IAB's efforts for general online advertising.
Mobile advertising is growing rapidly for several reasons. There are more mobile devices in the field, connectivity speeds have improved (which, among other things, allows for richer media ads to be served quickly), screen resolutions have advanced, mobile publishers are becoming more sophisticated about incorporating ads, and consumers are using mobile devices more extensively.
The Interactive Advertising Bureau predicts continued growth in mobile advertising with the adoption of location-based targeting and other technological features not available or relevant on personal computers.
In July 2014 Facebook reported advertising revenue for the June 2014 quarter of $2.68 billion, an increase of 67 percent over the second quarter of 2013. Of that, mobile advertising revenue accounted for around 62 percent, an increase of 41 percent on the previous year.
As of 2016, 14% of marketers used live videos for advertising.
Email advertising:
Email advertising is ad copy comprising an entire email or a portion of an email message. Email marketing may be unsolicited, in which case the sender may give the recipient an option to opt out of future emails, or it may be sent with the recipient's prior consent (opt-in).
Chat advertising:
As opposed to static messaging, chat advertising refers to real time messages dropped to users on certain sites. This is done by the usage of live chat software or tracking applications installed within certain websites with the operating personnel behind the site often dropping adverts on the traffic surfing around the sites. In reality this is a subset of the email advertising but different because of its time window.
Online classified advertising:
Online classified advertising is advertising posted online in a categorical listing of specific products or services. Examples include online job boards, online real estate listings, automotive listings, online yellow pages, and online auction-based listings. Craigslist and eBay are two prominent providers of online classified listings.
Adware:
Adware is software that, once installed, automatically displays advertisements on a user's computer. The ads may appear in the software itself, integrated into web pages visited by the user, or in pop-ups/pop-unders. Adware installed without the user's permission is a type of malware.
Affiliate marketing:
Affiliate marketing occurs when advertisers organize third parties to generate potential customers for them. Third-party affiliates receive payment based on sales generated through their promotion.
Affiliate marketers generate traffic to offers from affiliate networks, and when the desired action is taken by the visitor, the affiliate earns a commission. These desired actions can be an email submission, a phone call, filling out an online form, or an online order being completed.
Content marketing:
Content marketing is any marketing that involves the creation and sharing of media and publishing content in order to acquire and retain customers. This information can be presented in a variety of formats, including blogs, news, video, white papers, e-books, infographics, case studies, how-to guides and more.
Considering that most marketing involves some form of published media, it is almost (though not entirely) redundant to call 'content marketing' anything other than simply 'marketing'.
There are, of course, other forms of marketing (in-person marketing, telephone-based marketing, word of mouth marketing, etc.) where the label is more useful for identifying the type of marketing. However, even these are usually merely presenting content that they are marketing as information in a way that is different from traditional print, radio, TV, film, email, or web media.
Online marketing platform:
Online marketing platform (OMP) is an integrated web-based platform that combines the benefits of a business directory, local search engine, search engine optimization (SEO) tool, customer relationship management (CRM) package and content management system (CMS).
Ebay and Amazon are used as online marketing and logistics management platforms. On Facebook, Twitter, YouTube, Pinterest, LinkedIn, and other Social Media, retail online marketing is also used. Online business marketing platforms such as Marketo, Aprimo, MarketBright and Pardot have been bought by major IT companies (Eloqua-Oracle, Neolane-Adobe and Unica-IBM).
Unlike television marketing in which Neilsen TV Ratings can be relied upon for viewing metrics, online advertisers do not have an independent party to verify viewing claims made by the big online platforms.
Compensation methods:
Main article: Compensation methods
Advertisers and publishers use a wide range of payment calculation methods. In 2012, advertisers calculated 32% of online advertising transactions on a cost-per-impression basis, 66% on customer performance (e.g. cost per click or cost per acquisition), and 2% on hybrids of impression and performance methods.
CPM (cost per mille):
Cost per mille, often abbreviated to CPM, means that advertisers pay for every thousand displays of their message to potential customers (mille is the Latin word for thousand). In the online context, ad displays are usually called "impressions." Definitions of an "impression" vary among publishers, and some impressions may not be charged because they don't represent a new exposure to an actual customer. Advertisers can use technologies such as web bugs to verify if an impression is actually delivered.
Publishers use a variety of techniques to increase page views, such as dividing content across multiple pages, repurposing someone else's content, using sensational titles, or publishing tabloid or sexual content.
CPM advertising is susceptible to "impression fraud," and advertisers who want visitors to their sites may not find per-impression payments a good proxy for the results they desire.
CPC (cost per click):
CPC (Cost Per Click) or PPC (Pay per click) means advertisers pay each time a user clicks on the ad. CPC advertising works well when advertisers want visitors to their sites, but it's a less accurate measurement for advertisers looking to build brand awareness. CPC's market share has grown each year since its introduction, eclipsing CPM to dominate two-thirds of all online advertising compensation methods.
Like impressions, not all recorded clicks are valuable to advertisers. GoldSpot Media reported that up to 50% of clicks on static mobile banner ads are accidental and resulted in redirected visitors leaving the new site immediately.
CPE (cost per engagement):
Cost per engagement aims to track not just that an ad unit loaded on the page (i.e., an impression was served), but also that the viewer actually saw and/or interacted with the ad.
CPV (cost per view):
Cost per view video advertising. Both Google and TubeMogul endorsed this standardized CPV metric to the IAB's (Interactive Advertising Bureau) Digital Video Committee, and it's garnering a notable amount of industry support. CPV is the primary benchmark used in YouTube Advertising Campaigns, as part of Google's AdWords platform.
CPI (cost per install):
The CPI compensation method is specific to mobile applications and mobile advertising. In CPI ad campaigns brands are charged a fixed of bid rate only when the application was installed.
Attribution of ad value:
Main article: Attribution (marketing)
In marketing, "attribution" is the measurement of effectiveness of particular ads in a consumer's ultimate decision to purchase. Multiple ad impressions may lead to a consumer "click" or other action. A single action may lead to revenue being paid to multiple ad space sellers.
Other performance-based compensation:
CPA (Cost Per Action or Cost Per Acquisition) or PPP (Pay Per Performance) advertising means the advertiser pays for the number of users who perform a desired activity, such as completing a purchase or filling out a registration form.
Performance-based compensation can also incorporate revenue sharing, where publishers earn a percentage of the advertiser's profits made as a result of the ad. Performance-based compensation shifts the risk of failed advertising onto publishers.
Fixed cost:
Fixed cost compensation means advertisers pay a fixed cost for delivery of ads online, usually over a specified time period, irrespective of the ad's visibility or users' response to it.
One example is CPD (cost per day) where advertisers pay a fixed cost for publishing an ad for a day irrespective of impressions served or clicks.
Benefits of Online Advertising:
Cost:
The low costs of electronic communication reduce the cost of displaying online advertisements compared to offline ads. Online advertising, and in particular social media, provides a low-cost means for advertisers to engage with large established communities.
Advertising online offers better returns than in other media.
Measurability:
Online advertisers can collect data on their ads' effectiveness, such as the size of the potential audience or actual audience response, how a visitor reached their advertisement, whether the advertisement resulted in a sale, and whether an ad actually loaded within a visitor's view. This helps online advertisers improve their ad campaigns over time.
Formatting:
Advertisers have a wide variety of ways of presenting their promotional messages, including the ability to convey images, video, audio, and links. Unlike many offline ads, online ads also can be interactive. For example, some ads let users input queries or let users follow the advertiser on social media. Online ads can even incorporate games.
Targeting:
Publishers can offer advertisers the ability to reach customizable and narrow market segments for targeted advertising. Online advertising may use geo-targeting to display relevant advertisements to the user's geography.
Advertisers can customize each individual ad to a particular user based on the user's previous preferences. Advertisers can also track whether a visitor has already seen a particular ad in order to reduce unwanted repetitious exposures and provide adequate time gaps between exposures.
Coverage:
Online advertising can reach nearly every global market, and online advertising influences offline sales.
Speed:
Once ad design is complete, online ads can be deployed immediately. The delivery of online ads does not need to be linked to the publisher's publication schedule. Furthermore, online advertisers can modify or replace ad copy more rapidly than their offline counterparts.
Concerns:
Security concerns:
According to a US Senate investigation, the current state of online advertising endangers the security and privacy of users.
Banner blindness:
Eye-tracking studies have shown that Internet users often ignore web page zones likely to contain display ads (sometimes called "banner blindness"), and this problem is worse online than in offline media. On the other hand, studies suggest that even those ads "ignored" by the users may influence the user subconsciously.
Fraud on the advertiser:
There are numerous ways that advertisers can be overcharged for their advertising. For example, click fraud occurs when a publisher or third parties click (manually or through automated means) on a CPC ad with no legitimate buying intent. For example, click fraud can occur when a competitor clicks on ads to deplete its rival's advertising budget, or when publishers attempt to manufacture revenue.
Click fraud is especially associated with pornography sites. In 2011, certain scamming porn websites launched dozens of hidden pages on each visitor's computer, forcing the visitor's computer to click on hundreds of paid links without the visitor's knowledge.
As with offline publications, online impression fraud can occur when publishers overstate the number of ad impressions they have delivered to their advertisers. To combat impression fraud, several publishing and advertising industry associations are developing ways to count online impressions credibly.
Technological variations:
Heterogeneous clients: Because users have different operating systems, web browsers and computer hardware (including mobile devices and different screen sizes), online ads may appear to users differently from how the advertiser intended, or the ads may not display properly at all.
A 2012 comScore study revealed that, on average, 31% of ads were not "in-view" when rendered, meaning they never had an opportunity to be seen. Rich media ads create even greater compatibility problems, as some developers may use competing (and exclusive) software to render the ads (see e.g. Comparison of HTML 5 and Flash).
Furthermore, advertisers may encounter legal problems if legally required information doesn't actually display to users, even if that failure is due to technological heterogeneity.
In the United States, the FTC has released a set of guidelines indicating that it's the advertisers' responsibility to ensure the ads display any required disclosures or disclaimers, irrespective of the users' technology.
Ad blocking: Ad blocking, or ad filtering, means the ads do not appear to the user because the user uses technology to screen out ads. Many browsers block unsolicited pop-up ads by default.
Other software programs or browser add-ons may also block the loading of ads, or block elements on a page with behaviors characteristic of ads (e.g. HTML autoplay of both audio and video). Approximately 9% of all online page views come from browsers with ad-blocking software installed, and some publishers have 40%+ of their visitors using ad-blockers.
Anti-targeting technologies: Some web browsers offer privacy modes where users can hide information about themselves from publishers and advertisers. Among other consequences, advertisers can't use cookies to serve targeted ads to private browsers. Most major browsers have incorporated Do Not Track options into their browser headers, but the regulations currently are only enforced by the honor system.
Privacy concerns: The collection of user information by publishers and advertisers has raised consumer concerns about their privacy. Sixty percent of Internet users would use Do Not Track technology to block all collection of information if given an opportunity. Over half of all Google and Facebook users are concerned about their privacy when using Google and Facebook, according to Gallup.
Many consumers have reservations about online behavioral targeting. By tracking users' online activities, advertisers are able to understand consumers quite well. Advertisers often use technology, such as web bugs and re-spawning cookies, to maximizing their abilities to track consumers.
According to a 2011 survey conducted by Harris Interactive, over half of Internet users had a negative impression of online behavioral advertising, and forty percent feared that their personally-identifiable information had been shared with advertisers without their consent.
Consumers can be especially troubled by advertisers targeting them based on sensitive information, such as financial or health status. Furthermore, some advertisers attach the MAC address of users' devices to their 'demographic profiles' so they can be re-targeted (regardless of the accuracy of the profile) even if the user clears their cookies and browsing history.
Trustworthiness of advertisers: Scammers can take advantage of consumers' difficulties verifying an online persona's identity, leading to artifices like phishing (where scam emails look identical to those from a well-known brand owner) and confidence schemes like the Nigerian "419" scam.
The Internet Crime Complaint Center received 289,874 complaints in 2012, totaling over half a billion dollars in losses, most of which originated with scam ads.
Consumers also face malware risks, i.e. malvertising, when interacting with online advertising. Cisco's 2013 Annual Security Report revealed that clicking on ads was 182 times more likely to install a virus on a user's computer than surfing the Internet for porn.
For example, in August 2014 Yahoo's advertising network reportedly saw cases of infection of a variant of Cryptolocker ransomware.
Spam: The Internet's low cost of disseminating advertising contributes to spam, especially by large-scale spammers. Numerous efforts have been undertaken to combat spam, ranging from blacklists to regulatorily-required labeling to content filters, but most of those efforts have adverse collateral effects, such as mistaken filtering.
Regulation:
In general, consumer protection laws apply equally to online and offline activities. However, there are questions over which jurisdiction's laws apply and which regulatory agencies have enforcement authority over trans-border activity.
As with offline advertising, industry participants have undertaken numerous efforts to self-regulate and develop industry standards or codes of conduct. Several United States advertising industry organizations jointly published Self-Regulatory Principles for Online Behavioral Advertising based on standards proposed by the FTC in 2009.
European ad associations published a similar document in 2011. Primary tenets of both documents include consumer control of data transfer to third parties, data security, and consent for collection of certain health and financial data. Neither framework, however, penalizes violators of the codes of conduct.
Privacy and data collection:
Privacy regulation can require users' consent before an advertiser can track the user or communicate with the user. However, affirmative consent ("opt in") can be difficult and expensive to obtain. Industry participants often prefer other regulatory schemes.
Different jurisdictions have taken different approaches to privacy issues with advertising. The United States has specific restrictions on online tracking of children in the Children's Online Privacy Protection Act (COPPA), and the FTC has recently expanded its interpretation of COPPA to include requiring ad networks to obtain parental consent before knowingly tracking kids.
Otherwise, the U.S. Federal Trade Commission frequently supports industry self-regulation, although increasingly it has been undertaking enforcement actions related to online privacy and security. The FTC has also been pushing for industry consensus about possible Do Not Track legislation.
In contrast, the European Union's "Privacy and Electronic Communications Directive" restricts websites' ability to use consumer data much more comprehensively. The EU limitations restrict targeting by online advertisers; researchers have estimated online advertising effectiveness decreases on average by around 65% in Europe relative to the rest of the world.
Delivery methods:
Many laws specifically regulate the ways online ads are delivered. For example, online advertising delivered via email is more regulated than the same ad content delivered via banner ads. Among other restrictions, the U.S. CAN-SPAM Act of 2003 requires that any commercial email provide an opt-out mechanism.
Similarly, mobile advertising is governed by the Telephone Consumer Protection Act of 1991 (TCPA), which (among other restrictions) requires user opt-in before sending advertising via text messaging.
See Also:
It includes the following:
- email marketing,
- search engine marketing (SEM),
- social media marketing,
- many types of display advertising (including web banner advertising),
- and mobile advertising.
Like other advertising media, online advertising frequently involves both a publisher, who integrates advertisements into its online content, and an advertiser, who provides the advertisements to be displayed on the publisher's content.
Other potential participants include advertising agencies who help generate and place the ad copy, an ad server which technologically delivers the ad and tracks statistics, and advertising affiliates who do independent promotional work for the advertiser.
In 2016, Internet advertising revenues in the United States surpassed those of cable television and broadcast television. In 2017, Internet advertising revenues in the United States totaled $83.0 billion, a 14% increase over the $72.50 billion in revenues in 2016.
Many common online advertising practices are controversial and increasingly subject to regulation. Online ad revenues may not adequately replace other publishers' revenue streams.
Declining ad revenue has led some publishers to hide their content behind paywalls.
Delivery Methods:
Display Advertising:
Display advertising conveys its advertising message visually using text, logos, animations, videos, photographs, or other graphics. Display advertisers frequently target users with particular traits to increase the ads' effect.
Online advertisers (typically through their ad servers) often use cookies, which are unique identifiers of specific computers, to decide which ads to serve to a particular consumer. Cookies can track whether a user left a page without buying anything, so the advertiser can later retarget the user with ads from the site the user visited.
As advertisers collect data across multiple external websites about a user's online activity, they can create a detailed profile of the user's interests to deliver even more targeted advertising. This aggregation of data is called behavioral targeting. Advertisers can also target their audience by using contextual to deliver display ads related to the content of the web page where the ads appear.
Re-targeting, behavioral targeting, and contextual advertising all are designed to increase an advertiser's return on investment, or ROI, over untargeted ads.
Advertisers may also deliver ads based on a user's suspected geography through geotargeting.
A user's IP address communicates some geographic information (at minimum, the user's country or general region). The geographic information from an IP can be supplemented and refined with other proxies or information to narrow the range of possible locations. For example, with mobile devices, advertisers can sometimes use a phone's GPS receiver or the location of nearby mobile towers.
Cookies and other persistent data on a user's machine may provide help narrowing a user's location further.
Web banner advertising:
Web banners or banner ads typically are graphical ads displayed within a web page. Many banner ads are delivered by a central ad server.
Banner ads can use rich media to incorporate video, audio, animations, buttons, forms, or other interactive elements using Java applets, HTML5, Adobe Flash, and other programs.
Frame ad (traditional banner):
Frame ads were the first form of web banners. The colloquial usage of "banner ads" often refers to traditional frame ads. Website publishers incorporate frame ads by setting aside a particular space on the web page. The Interactive Advertising Bureau's Ad Unit Guidelines proposes standardized pixel dimensions for ad units.
Pop-ups/pop-unders:
A pop-up ad is displayed in a new web browser window that opens above a website visitor's initial browser window. A pop-under ad opens a new browser window under a website visitor's initial browser window. Pop-under ads and similar technologies are now advised against by online authorities such as Google, who state that they "do not condone this practice".
Floating ad:
A floating ad, or overlay ad, is a type of rich media advertisement that appears superimposed over the requested website's content. Floating ads may disappear or become less obtrusive after a preset time period.
Expanding ad:
An expanding ad is a rich media frame ad that changes dimensions upon a predefined condition, such as a preset amount of time a visitor spends on a webpage, the user's click on the ad, or the user's mouse movement over the ad. Expanding ads allow advertisers to fit more information into a restricted ad space.
Trick banners:
A trick banner is a banner ad where the ad copy imitates some screen element users commonly encounter, such as an operating system message or popular application message, to induce ad clicks.
Trick banners typically do not mention the advertiser in the initial ad, and thus they are a form of bait-and-switch. Trick banners commonly attract a higher-than-average click-through rate, but tricked users may resent the advertiser for deceiving them.
News Feed Ads:
"News Feed Ads", also called "Sponsored Stories", "Boosted Posts", typically exist on social media platforms that offer a steady stream of information updates ("news feed") in regulated formats (i.e. in similar sized small boxes with a uniform style). Those advertisements are intertwined with non-promoted news that the users are reading through.
These advertisements can be of any content, such as promoting a website, a fan page, an app, or a product. Some examples are:
- Facebook's "Sponsored Stories"
- LinkedIn's "Sponsored Updates",
- and Twitter's "Promoted Tweets".
This display ads format falls into its own category because unlike banner ads which are quite distinguishable, News Feed Ads' format blends well into non-paid news updates. This format of online advertisement yields much higher click-through rates than traditional display ads.
Display advertising process overview:
The process by which online advertising is displayed can involve many parties. In the simplest case, the website publisher selects and serves the ads. Publishers which operate their own advertising departments may use this method.
The ads may be outsourced to an advertising agency under contract with the publisher, and served from the advertising agency's servers.
Alternatively, ad space may be offered for sale in a bidding market using an ad exchange and real-time bidding. This involves many parties interacting automatically in real time. In response to a request from the user's browser, the publisher content server sends the web page content to the user's browser over the Internet.
The page does not yet contain ads, but contains links which cause the user's browser to connect to the publisher ad server to request that the spaces left for ads be filled in with ads. Information identifying the user, such as cookies and the page being viewed, is transmitted to the publisher ad server.
The publisher ad server then communicates with a supply-side platform server. The publisher is offering ad space for sale, so they are considered the supplier. The supply side platform also receives the user's identifying information, which it sends to a data management platform. At the data management platform, the user's identifying information is used to look up demographic information, previous purchases, and other information of interest to advertisers.
Broadly speaking, there are three types of data obtained through such a data management platform:
- First party data refers to the data retrieved from customer relationship management (CRM) platforms, in addition to website and paid media content or cross-platform data. This can include data from customer behaviors, actions or interests.
- Second party data refers to an amalgamation of statistics related to cookie pools on external publications and platforms. The data is provided directly from the source (adservers, hosted solutions for social or an analytics platform). It is also possible to negotiate a deal with a particular publisher to secure specific data points or audiences.
- Third party data is sourced from external providers and often aggregated from numerous websites. Businesses sell third-party data and are able to share this via an array of distribution avenues.
This customer information is combined and returned to the supply side platform, which can now package up the offer of ad space along with information about the user who will view it. The supply side platform sends that offer to an ad exchange.
The ad exchange puts the offer out for bid to demand-side platforms. Demand side platforms act on behalf of ad agencies, who sell ads which advertise brands. Demand side platforms thus have ads ready to display, and are searching for users to view them.
Bidders get the information about the user ready to view the ad, and decide, based on that information, how much to offer to buy the ad space. According to the Internet Advertising Bureau, a demand side platform has 10 milliseconds to respond to an offer. The ad exchange picks the winning bid and informs both parties.
The ad exchange then passes the link to the ad back through the supply side platform and the publisher's ad server to the user's browser, which then requests the ad content from the agency's ad server. The ad agency can thus confirm that the ad was delivered to the browser.
This is simplified, according to the IAB. Exchanges may try to unload unsold ("remnant") space at low prices through other exchanges. Some agencies maintain semi-permanent pre-cached bids with ad exchanges, and those may be examined before going out to additional demand side platforms for bids.
The process for mobile advertising is different and may involve mobile carriers and handset software manufacturers.
Interstitial:
An interstitial ad displays before a user can access requested content, sometimes while the user is waiting for the content to load. Interstitial ads are a form of interruption marketing.
Text ads:
A text ad displays text-based hyperlinks. Text-based ads may display separately from a web page's primary content, or they can be embedded by hyperlinking individual words or phrases to advertiser's websites. Text ads may also be delivered through email marketing or text message marketing. Text-based ads often render faster than graphical ads and can be harder for ad-blocking software to block.
Search engine marketing (SEM):
Search engine marketing, or SEM, is designed to increase a website's visibility in search engine results pages (SERPs). Search engines provide sponsored results and organic (non-sponsored) results based on a web searcher's query. Search engines often employ visual cues to differentiate sponsored results from organic results. Search engine marketing includes all of an advertiser's actions to make a website's listing more prominent for topical keywords.
Search engine optimization (SEO):
Search engine optimization, or SEO, attempts to improve a website's organic search rankings in SERPs by increasing the website content's relevance to search terms. Search engines regularly update their algorithms to penalize poor quality sites that try to game their rankings, making optimization a moving target for advertisers. Many vendors offer SEO services.
Sponsored search:
Sponsored search (also called sponsored links, search ads, or paid search) allows advertisers to be included in the sponsored results of a search for selected keywords. Search ads are often sold via real-time auctions, where advertisers bid on keywords. In addition to setting a maximum price per keyword, bids may include time, language, geographical, and other constraints.
Search engines originally sold listings in order of highest bids. Modern search engines rank sponsored listings based on a combination of bid price, expected click-through rate, keyword relevancy and site quality.
Social media marketing:
Social media marketing is commercial promotion conducted through social media websites.
Many companies promote their products by posting frequent updates and providing special offers through their social media profiles.
Mobile advertising:
Mobile advertising is ad copy delivered through wireless mobile devices such as smartphones, feature phones, or tablet computers. Mobile advertising may take the form of static or rich media display ads, SMS (Short Message Service) or MMS (Multimedia Messaging Service) ads, mobile search ads, advertising within mobile websites, or ads within mobile applications or games (such as interstitial ads, "advergaming," or application sponsorship).
Industry groups such as the Mobile Marketing Association have attempted to standardize mobile ad unit specifications, similar to the IAB's efforts for general online advertising.
Mobile advertising is growing rapidly for several reasons. There are more mobile devices in the field, connectivity speeds have improved (which, among other things, allows for richer media ads to be served quickly), screen resolutions have advanced, mobile publishers are becoming more sophisticated about incorporating ads, and consumers are using mobile devices more extensively.
The Interactive Advertising Bureau predicts continued growth in mobile advertising with the adoption of location-based targeting and other technological features not available or relevant on personal computers.
In July 2014 Facebook reported advertising revenue for the June 2014 quarter of $2.68 billion, an increase of 67 percent over the second quarter of 2013. Of that, mobile advertising revenue accounted for around 62 percent, an increase of 41 percent on the previous year.
As of 2016, 14% of marketers used live videos for advertising.
Email advertising:
Email advertising is ad copy comprising an entire email or a portion of an email message. Email marketing may be unsolicited, in which case the sender may give the recipient an option to opt out of future emails, or it may be sent with the recipient's prior consent (opt-in).
Chat advertising:
As opposed to static messaging, chat advertising refers to real time messages dropped to users on certain sites. This is done by the usage of live chat software or tracking applications installed within certain websites with the operating personnel behind the site often dropping adverts on the traffic surfing around the sites. In reality this is a subset of the email advertising but different because of its time window.
Online classified advertising:
Online classified advertising is advertising posted online in a categorical listing of specific products or services. Examples include online job boards, online real estate listings, automotive listings, online yellow pages, and online auction-based listings. Craigslist and eBay are two prominent providers of online classified listings.
Adware:
Adware is software that, once installed, automatically displays advertisements on a user's computer. The ads may appear in the software itself, integrated into web pages visited by the user, or in pop-ups/pop-unders. Adware installed without the user's permission is a type of malware.
Affiliate marketing:
Affiliate marketing occurs when advertisers organize third parties to generate potential customers for them. Third-party affiliates receive payment based on sales generated through their promotion.
Affiliate marketers generate traffic to offers from affiliate networks, and when the desired action is taken by the visitor, the affiliate earns a commission. These desired actions can be an email submission, a phone call, filling out an online form, or an online order being completed.
Content marketing:
Content marketing is any marketing that involves the creation and sharing of media and publishing content in order to acquire and retain customers. This information can be presented in a variety of formats, including blogs, news, video, white papers, e-books, infographics, case studies, how-to guides and more.
Considering that most marketing involves some form of published media, it is almost (though not entirely) redundant to call 'content marketing' anything other than simply 'marketing'.
There are, of course, other forms of marketing (in-person marketing, telephone-based marketing, word of mouth marketing, etc.) where the label is more useful for identifying the type of marketing. However, even these are usually merely presenting content that they are marketing as information in a way that is different from traditional print, radio, TV, film, email, or web media.
Online marketing platform:
Online marketing platform (OMP) is an integrated web-based platform that combines the benefits of a business directory, local search engine, search engine optimization (SEO) tool, customer relationship management (CRM) package and content management system (CMS).
Ebay and Amazon are used as online marketing and logistics management platforms. On Facebook, Twitter, YouTube, Pinterest, LinkedIn, and other Social Media, retail online marketing is also used. Online business marketing platforms such as Marketo, Aprimo, MarketBright and Pardot have been bought by major IT companies (Eloqua-Oracle, Neolane-Adobe and Unica-IBM).
Unlike television marketing in which Neilsen TV Ratings can be relied upon for viewing metrics, online advertisers do not have an independent party to verify viewing claims made by the big online platforms.
Compensation methods:
Main article: Compensation methods
Advertisers and publishers use a wide range of payment calculation methods. In 2012, advertisers calculated 32% of online advertising transactions on a cost-per-impression basis, 66% on customer performance (e.g. cost per click or cost per acquisition), and 2% on hybrids of impression and performance methods.
CPM (cost per mille):
Cost per mille, often abbreviated to CPM, means that advertisers pay for every thousand displays of their message to potential customers (mille is the Latin word for thousand). In the online context, ad displays are usually called "impressions." Definitions of an "impression" vary among publishers, and some impressions may not be charged because they don't represent a new exposure to an actual customer. Advertisers can use technologies such as web bugs to verify if an impression is actually delivered.
Publishers use a variety of techniques to increase page views, such as dividing content across multiple pages, repurposing someone else's content, using sensational titles, or publishing tabloid or sexual content.
CPM advertising is susceptible to "impression fraud," and advertisers who want visitors to their sites may not find per-impression payments a good proxy for the results they desire.
CPC (cost per click):
CPC (Cost Per Click) or PPC (Pay per click) means advertisers pay each time a user clicks on the ad. CPC advertising works well when advertisers want visitors to their sites, but it's a less accurate measurement for advertisers looking to build brand awareness. CPC's market share has grown each year since its introduction, eclipsing CPM to dominate two-thirds of all online advertising compensation methods.
Like impressions, not all recorded clicks are valuable to advertisers. GoldSpot Media reported that up to 50% of clicks on static mobile banner ads are accidental and resulted in redirected visitors leaving the new site immediately.
CPE (cost per engagement):
Cost per engagement aims to track not just that an ad unit loaded on the page (i.e., an impression was served), but also that the viewer actually saw and/or interacted with the ad.
CPV (cost per view):
Cost per view video advertising. Both Google and TubeMogul endorsed this standardized CPV metric to the IAB's (Interactive Advertising Bureau) Digital Video Committee, and it's garnering a notable amount of industry support. CPV is the primary benchmark used in YouTube Advertising Campaigns, as part of Google's AdWords platform.
CPI (cost per install):
The CPI compensation method is specific to mobile applications and mobile advertising. In CPI ad campaigns brands are charged a fixed of bid rate only when the application was installed.
Attribution of ad value:
Main article: Attribution (marketing)
In marketing, "attribution" is the measurement of effectiveness of particular ads in a consumer's ultimate decision to purchase. Multiple ad impressions may lead to a consumer "click" or other action. A single action may lead to revenue being paid to multiple ad space sellers.
Other performance-based compensation:
CPA (Cost Per Action or Cost Per Acquisition) or PPP (Pay Per Performance) advertising means the advertiser pays for the number of users who perform a desired activity, such as completing a purchase or filling out a registration form.
Performance-based compensation can also incorporate revenue sharing, where publishers earn a percentage of the advertiser's profits made as a result of the ad. Performance-based compensation shifts the risk of failed advertising onto publishers.
Fixed cost:
Fixed cost compensation means advertisers pay a fixed cost for delivery of ads online, usually over a specified time period, irrespective of the ad's visibility or users' response to it.
One example is CPD (cost per day) where advertisers pay a fixed cost for publishing an ad for a day irrespective of impressions served or clicks.
Benefits of Online Advertising:
Cost:
The low costs of electronic communication reduce the cost of displaying online advertisements compared to offline ads. Online advertising, and in particular social media, provides a low-cost means for advertisers to engage with large established communities.
Advertising online offers better returns than in other media.
Measurability:
Online advertisers can collect data on their ads' effectiveness, such as the size of the potential audience or actual audience response, how a visitor reached their advertisement, whether the advertisement resulted in a sale, and whether an ad actually loaded within a visitor's view. This helps online advertisers improve their ad campaigns over time.
Formatting:
Advertisers have a wide variety of ways of presenting their promotional messages, including the ability to convey images, video, audio, and links. Unlike many offline ads, online ads also can be interactive. For example, some ads let users input queries or let users follow the advertiser on social media. Online ads can even incorporate games.
Targeting:
Publishers can offer advertisers the ability to reach customizable and narrow market segments for targeted advertising. Online advertising may use geo-targeting to display relevant advertisements to the user's geography.
Advertisers can customize each individual ad to a particular user based on the user's previous preferences. Advertisers can also track whether a visitor has already seen a particular ad in order to reduce unwanted repetitious exposures and provide adequate time gaps between exposures.
Coverage:
Online advertising can reach nearly every global market, and online advertising influences offline sales.
Speed:
Once ad design is complete, online ads can be deployed immediately. The delivery of online ads does not need to be linked to the publisher's publication schedule. Furthermore, online advertisers can modify or replace ad copy more rapidly than their offline counterparts.
Concerns:
Security concerns:
According to a US Senate investigation, the current state of online advertising endangers the security and privacy of users.
Banner blindness:
Eye-tracking studies have shown that Internet users often ignore web page zones likely to contain display ads (sometimes called "banner blindness"), and this problem is worse online than in offline media. On the other hand, studies suggest that even those ads "ignored" by the users may influence the user subconsciously.
Fraud on the advertiser:
There are numerous ways that advertisers can be overcharged for their advertising. For example, click fraud occurs when a publisher or third parties click (manually or through automated means) on a CPC ad with no legitimate buying intent. For example, click fraud can occur when a competitor clicks on ads to deplete its rival's advertising budget, or when publishers attempt to manufacture revenue.
Click fraud is especially associated with pornography sites. In 2011, certain scamming porn websites launched dozens of hidden pages on each visitor's computer, forcing the visitor's computer to click on hundreds of paid links without the visitor's knowledge.
As with offline publications, online impression fraud can occur when publishers overstate the number of ad impressions they have delivered to their advertisers. To combat impression fraud, several publishing and advertising industry associations are developing ways to count online impressions credibly.
Technological variations:
Heterogeneous clients: Because users have different operating systems, web browsers and computer hardware (including mobile devices and different screen sizes), online ads may appear to users differently from how the advertiser intended, or the ads may not display properly at all.
A 2012 comScore study revealed that, on average, 31% of ads were not "in-view" when rendered, meaning they never had an opportunity to be seen. Rich media ads create even greater compatibility problems, as some developers may use competing (and exclusive) software to render the ads (see e.g. Comparison of HTML 5 and Flash).
Furthermore, advertisers may encounter legal problems if legally required information doesn't actually display to users, even if that failure is due to technological heterogeneity.
In the United States, the FTC has released a set of guidelines indicating that it's the advertisers' responsibility to ensure the ads display any required disclosures or disclaimers, irrespective of the users' technology.
Ad blocking: Ad blocking, or ad filtering, means the ads do not appear to the user because the user uses technology to screen out ads. Many browsers block unsolicited pop-up ads by default.
Other software programs or browser add-ons may also block the loading of ads, or block elements on a page with behaviors characteristic of ads (e.g. HTML autoplay of both audio and video). Approximately 9% of all online page views come from browsers with ad-blocking software installed, and some publishers have 40%+ of their visitors using ad-blockers.
Anti-targeting technologies: Some web browsers offer privacy modes where users can hide information about themselves from publishers and advertisers. Among other consequences, advertisers can't use cookies to serve targeted ads to private browsers. Most major browsers have incorporated Do Not Track options into their browser headers, but the regulations currently are only enforced by the honor system.
Privacy concerns: The collection of user information by publishers and advertisers has raised consumer concerns about their privacy. Sixty percent of Internet users would use Do Not Track technology to block all collection of information if given an opportunity. Over half of all Google and Facebook users are concerned about their privacy when using Google and Facebook, according to Gallup.
Many consumers have reservations about online behavioral targeting. By tracking users' online activities, advertisers are able to understand consumers quite well. Advertisers often use technology, such as web bugs and re-spawning cookies, to maximizing their abilities to track consumers.
According to a 2011 survey conducted by Harris Interactive, over half of Internet users had a negative impression of online behavioral advertising, and forty percent feared that their personally-identifiable information had been shared with advertisers without their consent.
Consumers can be especially troubled by advertisers targeting them based on sensitive information, such as financial or health status. Furthermore, some advertisers attach the MAC address of users' devices to their 'demographic profiles' so they can be re-targeted (regardless of the accuracy of the profile) even if the user clears their cookies and browsing history.
Trustworthiness of advertisers: Scammers can take advantage of consumers' difficulties verifying an online persona's identity, leading to artifices like phishing (where scam emails look identical to those from a well-known brand owner) and confidence schemes like the Nigerian "419" scam.
The Internet Crime Complaint Center received 289,874 complaints in 2012, totaling over half a billion dollars in losses, most of which originated with scam ads.
Consumers also face malware risks, i.e. malvertising, when interacting with online advertising. Cisco's 2013 Annual Security Report revealed that clicking on ads was 182 times more likely to install a virus on a user's computer than surfing the Internet for porn.
For example, in August 2014 Yahoo's advertising network reportedly saw cases of infection of a variant of Cryptolocker ransomware.
Spam: The Internet's low cost of disseminating advertising contributes to spam, especially by large-scale spammers. Numerous efforts have been undertaken to combat spam, ranging from blacklists to regulatorily-required labeling to content filters, but most of those efforts have adverse collateral effects, such as mistaken filtering.
Regulation:
In general, consumer protection laws apply equally to online and offline activities. However, there are questions over which jurisdiction's laws apply and which regulatory agencies have enforcement authority over trans-border activity.
As with offline advertising, industry participants have undertaken numerous efforts to self-regulate and develop industry standards or codes of conduct. Several United States advertising industry organizations jointly published Self-Regulatory Principles for Online Behavioral Advertising based on standards proposed by the FTC in 2009.
European ad associations published a similar document in 2011. Primary tenets of both documents include consumer control of data transfer to third parties, data security, and consent for collection of certain health and financial data. Neither framework, however, penalizes violators of the codes of conduct.
Privacy and data collection:
Privacy regulation can require users' consent before an advertiser can track the user or communicate with the user. However, affirmative consent ("opt in") can be difficult and expensive to obtain. Industry participants often prefer other regulatory schemes.
Different jurisdictions have taken different approaches to privacy issues with advertising. The United States has specific restrictions on online tracking of children in the Children's Online Privacy Protection Act (COPPA), and the FTC has recently expanded its interpretation of COPPA to include requiring ad networks to obtain parental consent before knowingly tracking kids.
Otherwise, the U.S. Federal Trade Commission frequently supports industry self-regulation, although increasingly it has been undertaking enforcement actions related to online privacy and security. The FTC has also been pushing for industry consensus about possible Do Not Track legislation.
In contrast, the European Union's "Privacy and Electronic Communications Directive" restricts websites' ability to use consumer data much more comprehensively. The EU limitations restrict targeting by online advertisers; researchers have estimated online advertising effectiveness decreases on average by around 65% in Europe relative to the rest of the world.
Delivery methods:
Many laws specifically regulate the ways online ads are delivered. For example, online advertising delivered via email is more regulated than the same ad content delivered via banner ads. Among other restrictions, the U.S. CAN-SPAM Act of 2003 requires that any commercial email provide an opt-out mechanism.
Similarly, mobile advertising is governed by the Telephone Consumer Protection Act of 1991 (TCPA), which (among other restrictions) requires user opt-in before sending advertising via text messaging.
See Also:
- Adblock
- Advertising
- Advertising campaign
- Advertising management
- Advertising media
- Branded entertainment
- Direct marketing
- Integrated marketing communications
- Marketing communications
- Media planning
- Promotion (marketing)
- Promotional mix
- Promotional campaign
- Product placement
- Promotional merchandise
- Sales promotion
Targeted Advertising, including "How Ads Follow You from Phone to Desktop to Tablet" (by MIT Technology Review 7/1/2015)
YouTube Video: The Future of Targeted Advertising in Digital Media by Bloomberg

"Many consumers search on mobile devices but buy on computers, giving advertisers the incentive to track them across multiple screens.
Imagine you slack off at work and read up online about the latest Gibson 1959 Les Paul electric guitar replica. On the way home, you see an ad for the same model on your phone, reminding you this is “the most desirable Les Paul ever.” Then before bed on your tablet, you see another ad with new details about the guitar.
You may think the guitar gods have singled you out—it is your destiny to own this instrument!
For advertisers, the process is divine in its own right. Over the past year, companies have substantially and successfully stepped up repeat ad targeting to the same user across home and work computers, smart phones and tablets. With little fanfare, the strategy is fast becoming the new norm.
“You really have a convergence of three or four different things that are creating a tremendous amount of change,” says Philip Smolin, senior vice president for strategy at California-based digital advertising agency Turn. “There may be one wave that is small and it doesn’t move your boat very much, but when you have three or four medium size waves that all converge at the same time, then it becomes a massive wave, and that is happening right now.”
One of these recent waves has been greater sophistication of companies engaged in “probabilistic matching,” the study of millions of Web users to determine who is likely to be the same person across devices. For example, Drawbridge, which specializes in matching users across devices, says it has linked 1.2 billion users across 3.6 billion devices—up from 1.5 billion devices just a year ago.
Another trend making all this matching possible is the continuing transformation of Internet advertising into a marketplace of instant decisions, based on what companies know about the user.
Firms you have never heard of, such as Drawbridge, Crosswise, and Tapad, learn about your devices and your interests by tracking billions of ad requests a day from Internet ad exchanges selling in real time. Potential buyers see the user’s device, IP address, browser, and other details, information that allows for a sort of fingerprinting. “We are getting very smart about associating the anonymous identifiers across the various devices,” says Kamakshi Sivaramakrishnan, founder and CEO of Drawbridge.
For example, a cell phone and tablet accessing the same IP address at home would be one clue, as would searches for the same product. You might look for “Chevy Cruze” on your phone and then search Edmunds.com for the same thing on your laptop. The same geographic location of the searches within a short time period, combined with other information, might suggest the same user.
In the last six months or so, these companies say they have sharply increased the accuracy of probabilistic matching. A Nielsen survey of Drawbridge data released in April found 97.3 percent accuracy in linking two or more devices; an earlier Nielsen survey of Tapad found 91.2 percent accuracy.
Another wave feeding the fast growth of cross-platform advertising is the stampede onto mobile devices. Just last month Google announced that users in the United States, Japan, and eight other countries now use mobile devices for more than half of their searches. U.S. mobile traffic soared 63 percent in 2014 alone, according to a report from Cisco.
Many consumers search on mobile devices but buy on larger-screen computers, giving advertisers ever more incentive to track across multiple screens. Ad agencies are also breaking down traditional walls between video, mobile, and display teams to forge a more integrated approach.
For example, Turn recently worked with an auto insurer’s campaign that started with a video ad on one platform and then moved to display ads on other devices. The results of such efforts are promising. Drawbridge says it ran a cross-platform campaign for women’s sandals in the middle of winter for a major fashion retailer and achieved three times greater response than traditional Internet advertising.
People who prefer not to be tracked can take some countermeasures, especially against what is called deterministic tracking. Signing into Google or Facebook as well as websites and apps using those logins confirms which devices you own.
So you can log off Facebook, Google, and other accounts, use different e-mail addresses to confuse marketers and use masking software such as Blur. “But the probabilistic stuff is really hard to stop because it is like all the detritus of one’s daily activities,” says Andrew Sudbury, chief technology officer and cofounder of privacy company Abine, which makes Blur.
People can opt out of Internet tracking through an industry program called AdChoices, but few know about it or bother.
Advertisers stress they match potential buyers across platforms without gathering individual names. “People freak out over retargeting. People think someone is watching them. No one is watching anyone. The machine has a number,” says Roland Cozzolino, chief technology officer at MediaMath, a digital advertising company that last year bought Tactads, a cross-device targeting agency. “I don’t know who you are, I don’t know any personal information about you. I just know that these devices are controlled by the same user.”
Companies that go too far risk the wrath of customers. Verizon generated headlines such as “Verizon’s super-cookies are a super privacy violation” earlier this year when the public learned that the carrier plants unique identifying codes dubbed “supercookies” on Web pages. Verizon now explains the process on its website and allows an opt-out.
Drawbridge recently started tracking smart televisions and cable boxes, but advertisers on the whole are cautiously approaching targeted TV commercials, even as many expect such ad personalization in the future. Industry officials say they want to turn up the temperature slowly on the frogs in the pot of advertising, lest they leap out and prod regulation."
[End of Article]
___________________________________________________________________________
Targeted Advertising (by Wikipedia)
Targeted advertising is a form of advertising where online advertisers can use sophisticated methods to target the most receptive audiences with certain traits, based on the product or person the advertiser is promoting. These traits can either be demographic which are focused on race, economic status, sex, age, the level of education, income level and employment or they can be psychographic focused which are based on the consumer's values, personality, attitudes, opinions, lifestyles and interests.
They can also be behavioral variables, such as browser history, purchase history, and other recent activity. Targeted advertising is focused on certain traits and the consumers who are likely to have a strong preference will receive the message instead of those who have no interest and whose preferences do not match a product's attribute. This eliminates wastage.
Traditional forms of advertising, including billboards, newspapers, magazines and radio, are progressively becoming replaced by online advertisements. Information and communication technology (ICT) space has transformed over recent years, resulting in targeted advertising to stretch across all ICT technologies, such as web, IPTV, and mobile environments.
In next generation advertising, the importance of targeted advertisements will radically increase, as it spreads across numerous ICT channels cohesively.
Through the emergence of new online channels, the need for targeted advertising is increasing because companies aim to minimize wasted advertising by means of information technology.
Most targeted new media advertising currently uses second-order proxies for targetings, such as tracking online or mobile web activities of consumers, associating historical web page consumer demographics with new consumer web page access, using a search word as the basis for implied interest, or contextual advertising.
Types of Targeted Advertising:
Web services are continually generating new business ventures and revenue opportunities for internet corporations. Companies have rapidly developing technological capabilities that allow them to gather information about web users. By tracking and monitoring what websites users visit, internet service providers can directly show ads that are relative to the consumer's preferences.
Most of the time, this consist of the last search done. For example, you search for a real estate, you will then be overloaded by real estate, that you care about or not and if you had buy the product or not. It's why Ads are totally bias these days. They just tend to suggest the last search you have done. Most of today's websites are using these targeting technology to track users' internet behavior and there is much debate over the privacy issues present.
Search engine marketing:
Further information: Search engine marketing
Search engine marketing uses search engines to reach target audiences. For example, Google's Google Re-marketing Campaigns are a type of targeted advertising where websites use the IP addresses of computers that have visited their websites to re-market their ad specifically to the user who has previously been on their website as they use websites that are a part of the Google display network, or when searching for keywords related to a product or service on the google search engine.
Dynamic remarketing can improve the targeted advertising as the ads are able to include the products or services that the consumers have previously viewed on the advertisers' website within the ads.
Google Adwords have different platforms how the ads appear. The Search Network displays the ads on 'Google Search, other Google sites such as Maps and Shopping, and hundreds of non-Google search partner websites that show AdWords ads matched to search results'.
'The Display Network includes a collection of Google websites (like Google Finance, Gmail, Blogger, and YouTube), partner sites, and mobile sites and apps that show AdWords ads matched to the content on a given page.' These two kinds of Advertising networks can be beneficial for each specific goal of the company, or type of company. For example, the search network can benefit a company with the goal of reaching consumers searching for a particular product or service.
Other ways Advertising campaigns are able to target the user is to use browser history and search history, for example, if the user typed in promotional pens in a search engine, such as Google; ads for promotional pens will appear at the top of the page above the organic pages, these ads will be targeted to the area of the users IP address, showing the product or service in the local area or surrounding regions, the higher ad position is a benefit of the ad having a higher quality score.
The ad quality is affected by the 6 components of the quality score:
When ranked based on this criteria, will affect the advertiser by improving ad auction eligibility, actual cost per click (CPC), ad position, and ad position bid estimates; to summarize, the better the quality score, the better ad position, and lower costs.
Google uses its display network to track what users are looking at and to gather information about them. When a user goes onto a website that uses the google display network it will send a cookie to google, showing information on the user, what he or she searched, where they are from, found by the ip address, and then builds a profile around them, allowing google to easily target ads to the user more specifically.
For example, if a user went onto promotional companies' websites often, that sell promotional pens, google will gather data from the user such as age, gender, location and other demographic information as well as information on the websites visited, the user will then be put into a category of promotional products, allowing google to easily display ads on websites the user visits relating to promotional products. (Betrayed By Your Ads!) these types of adverts are also called behavioral advertisements as they track the website behaviour of the user and displays ads based on previous pages or searched terms. ("Examples Of Targeted Advertising")
Social media targeting:
Further information: Social media marketing
Social media targeting is a form of targeted advertising, that uses general targeting attributes such as geotargeting, behavioral targeting, socio-psychographic targeting, but gathers the information that consumer have provided on each social media platform. For example, on Facebook if a consumer has liked clothing pages they will receive ads based on those page likes and the area they have said they live in, this allows advertisers to target very specific consumers as they can specify cities and interests to their needs.
Social media also creates profiles of the consumer and only needs to look one place, one the users' profile to find all interests and 'likes'. E.g. Facebook lets advertisers target using broad characteristics like Gender, Age, and Location. Furthermore, they allow more narrow targeting based on Demographics, Behavior, and Interests (see a comprehensive list of Facebook's different types of targeting options).
TV and mobile targeting:
Another sphere targeted advertising occurs in is television. Advertisers can reach a consumer that is using digital cable, which is classified as Internet Protocol Television (IPTV). This is effective when information is collected about the user, their age, gender and location, and also their personal interests in films, etc. This data is then processed, optimized and then consumers are advertised to accordingly.
Since the early 2000s, advertising has been pervasive online and more recently in the mobile setting. Targeted advertising based on mobile devices allows more information about the consumer to be transmitted, not just their interests, but their information about their location and time.
A major concern about mobile users, when they don't have unlimited plan, they are force to download an Ads making them paying two times for these Ads (time and data). This allows advertisers to produce advertisements that could cater to their schedule and a more specific changing environment.
Content and contextual targeting:
Further information: Content marketing
The most straightforward method of targeting is content/contextual targeting. This is when advertisers put ads in a specific place, based on the relative content present (Schlee, 2013).
Another name used is content-oriented advertising, as it is corresponding the context being consumed. This targeting method can be used across different mediums, for example in an article online, about purchasing homes would have an advert associated with this context, like an insurance ad. This is usually achieved through an ad matching system which analyses the contents on a page or finds key words and presents a relevant advert, sometimes through pop-ups (Fan & Chang, 2010).
Though sometimes the ad matching system can fail, as it can neglect to tell the difference between positive and negative correlations. This can result in placing contradictory adverts, which are not appropriate to the content (Fan & Chang, 2010).
Technical targeting:
Technical targeting is associated with the user's own software or hardware status. The advertisement is altered depending on the user's available network bandwidth, for example if a user is on their mobile phone that has limited connection, the ad delivery system will display a version of the ad that is smaller for a faster data transfer rate, in theory but in practice they just spam you the same video, again and again.
Addressable advertising systems serve ads directly based on demographic, psychographic, or behavioral attributes associated with the consumer(s) exposed to the ad. These systems are always digital and must be addressable in that the end point which serves the ad (set-top box, website, or digital sign) must be capable of rendering an ad independently of any other end points based on consumer attributes specific to that end point at the time the ad is served.
Addressable advertising systems therefore must use consumer traits associated with the end points as the basis for selecting and serving ads.
Time targeting:
Time targeting is centered around time and focuses on the idea of fitting in around people's everyday lifestyles (Schlee, 2013). For example, scheduling specific ads at a timeframe from 5–7pm, when the typical commute home from work is.
Sociodemographic targeting:
Sociodemographic targeting focuses on the characteristics of consumers, including their age, gender, salary and nationality (Schlee, 2013). The idea is to target users specifically, using this data about them collected, for example, targeting a male in the age bracket of 18-24.
Facebook uses this form of targeting by showing advertisements relevant to the user's individual demographic on their account, this can show up in forms of banner ads, or commercial videos (Taylor et al., 2011).
Geographical and location-based targeting:
This type of advertising involves targeting different users based on their geographic location. IP addresses can signal the location of a user and can usually transfer the location through ZIP codes. (Schlee, 2013) Locations are then stored for users in static profiles, thus advertisers can easily target these individuals based on their geographic location.
A location-based service (LBS) is a mobile information service which allows spatial and temporal data transmission and can be used to an advertiser's advantage (Dhar & Varshney, 2011). This data can be harnessed from applications on the device that allow access to the location information (Peterson & Groot, 2009).
This type of targeted advertising focuses on localising content, for example a user could be prompted with options of activities in the area, for example places to eat, nearby shops etc. Although producing advertising off consumer's location-based services can improve the effectiveness of delivering ads, it can raise issues with the user's privacy (Li & Du, 2012).
Behavioral targeting:
Main article: Behavioral targeting
This form of targeted advertising is centered around the activity/actions of users, and is more easily achieved on web pages (Krumm, 2010). Information from browsing websites can be collected from data mining, which finds patterns in users search history.
Advertisers using this method believe it produces ads that will be more relevant to users, thus leading consumers be more likely influenced by them (Yan et al., 2009). If a consumer was frequently searching for plane ticket prices, the targeting system would recognise this and start showing related adverts across unrelated websites, such as airfare deals on Facebook. Its advantage is that it can target individual's interests, rather than target groups of people whose interests may vary (Schlee, 2013).
Re-targeting:
Retargeting is where advertisers use behavioural targeting to produce ads that follow users after users have looked at or purchased a particular item. An example of this is store catalogs, where stores subscribe customers to their email system after a purchase hoping that they draw attention to more items for continuous purchases. The main example of retargeting that has earned a reputation from most people are ads that follow users across the web, showing them the same items that they have looked at in the hope that they will purchase them.
Retargeting is a very effective process; by analysing consumers activities with the brand they can address their consumers' behaviour appropriately.
Through the emergence of new online channels, the need for targeted advertising is increasing because companies aim to minimize wasted advertising by means of information technology.
Most targeted new media advertising currently uses second-order proxies for targetings, such as tracking online or mobile web activities of consumers, associating historical web page consumer demographics with new consumer web page access, using a search word as the basis for implied interest, or contextual advertising.
Process:
Advertising provides advertisers with a direct line of communication to existing and prospective consumers.
By using a combination of words and/or pictures the general aim of the advertisement is to act as a "medium of information" (David Oglivy) making the means of delivery and to whom the information is delivered most important. Advertising should define how and when structural elements of advertisements influence receivers, knowing that all receivers are not the same and thus may not respond in a single, similar manner.
Targeted advertising serves the purpose of placing particular advertisements before specific groups so as to reach consumers who would be interested in the information. Advertisers aim to reach consumers as efficiently as possible with the belief that it will result in a more effective campaign.
By targeting, advertisers are able to identify when and where the ad should be positioned in order to achieve maximum profits. This requires an understanding of how customers' minds work (see also neuromarketing) so as to determine the best channel by which to communicate.
Types of targeting include, but are not limited to advertising based on demographics, psychographics, behavioral variables and contextual targeting.
Behavioral advertising is the most common form of targeting used online. Internet cookies are sent back and forth between an internet server and the browser, that allows a user to be identified or to track their progressions. Cookies provide detail on what pages a consumer visits, the amount of time spent viewing each page, the links clicked on; and searches and interactions made.
From this information, the cookie issuer gathers an understanding of the user's browsing tendencies and interests generating a profile. Analysing the profile, advertisers are able to create defined audience segments based upon users with similar returned similar information, hence profiles. Tailored advertising is then placed in front of the consumer based upon what organisations working on behalf of the advertisers assume are the interests of the consumer.
These advertisements have been formatted so as to appear on pages and in front of users that it would most likely appeal to based on their profiles. For example, under behavioral targeting if a user is known to have recently visited a number of automotive shopping and comparison sites based on the data recorded by cookies stored on the user's computer, the user can then be served automotive related advertisements when visiting other sites.
So behavioral advertising is reliant on data both wittingly and unwittingly provided by users and is made up of two different forms: one involving the delivery of advertising based on assessment of user's web movements; the second involving the examination of communication and information as it passes through the gateways of internet service providers.
Demographic targeting was the first and most basic form of targeting used online. involves segmenting an audience into more specific groups using parameters such as gender, age, ethnicity, annual income, parental status etc. All members in the group share the common trait.
So, when an advertiser wishes to run a campaign aimed at a specific group of people then that campaign is intended only for the group that contains those traits at which the campaign is targeted. Having finalized the advertiser's demographic target, a website or a website section is chosen as a medium because a large proportion of the targeted audience utilizes that form of media.
Segmentation using psychographics Is based on an individual's personality, values, interests and lifestyles. A recent study concerning what forms of media people use- conducted by the Entertainment Technology Center at the University of Southern California, the Hallmark Channel, and E-Poll Market Research- concludes that a better predictor of media usage is the user's lifestyle.
Researchers concluded that while cohorts of these groups may have similar demographic profiles, they may have different attitudes and media usage habits. Psychographics can provide further insight by distinguishing an audience into specific groups by using their personal traits.
Once acknowledging this is the case, advertisers can begin to target customers having recognized that factors other than age for example provides greater insight into the customer.
Contextual advertising is a strategy to place advertisements on media vehicles, such as specific websites or print magazines, whose themes are relevant to the promoted products (Joeng & King, 2005, p. 2). Advertisers apply this strategy in order to narrow-target their audiences (Belch & Belch, 2009, p. 2; Jeong and King, 2005). Advertisements are selected and served by automated systems based on the identity of the user and the displayed content of the media.
The advertisements will be displayed across the user's different platforms and are chosen based on searches for key words; appearing as either a web page or pop up ads. It is a form of targeted advertising in which the content of an ad is in direct correlation to the content of the webpage the user is viewing.
The major psychographic segments:
Personality: Every brand, service or product has itself a personality, how it is viewed by the public and the community and marketers will create these personalities to match the personality traits of their target market. Marketers and advertisers create these personalities because when a consumer can relate to the characteristics of a brand, service or product they are more likely to feel connected towards the product and purchase it.
Lifestyle: Everyone is different and advertisers compensate for this, they know different people lead different lives, have different lifestyles and different wants and needs at different times in their consumers lives ("Psychographic Market Segmentation | Local Directive", 2016).
Advertisers who base their segmentation on psychographic characteristics promote their product as the solution to these wants and needs. Segmentation by lifestyle considers where the consumer is in their life cycle and what is important to them at that exact time.
Opinions, attitudes, interests and hobbies: Psychographic segmentation also includes opinions on religious, gender and politics, sporting and recreational activities, views on the environment and arts and cultural issues. The views that the market segments hold and the activities they participate in will have a massive impact on the products and services they purchase and it will even affect how they respond to the message.
Alternatives to behavioral advertising and psychographic targeting include geographic targeting and demographic targeting
When advertisers want to reach as many consumers as efficiently as possible they use a six step process:
Alternatives to behavioral advertising include audience targeting, contextual targeting, and psychographic targeting.
Effectiveness:
Targeting improves the effectiveness of advertising it reduces the wastage created by sending advertising to consumers who are unlikely to purchase that product, target advertising or improved targeting will lead to lower advertising costs and expenditures.
The effects of advertising on society and those targeted are all implicitly underpinned by consideration of whether advertising compromises autonomous choice (Sneddon, 2001).
Those arguing for the ethical acceptability of advertising claim either that, because of the commercially competitive context of advertising, the consumer has a choice over what to accept and what to reject.
Humans have the cognitive competence and are equipped with the necessary faculties to decide whether to be affected by adverts (Shiffman, 1990). Those arguing against note, for example, that advertising can make us buy things we do not want or that, as advertising is enmeshed in a capitalist system, it only presents choices based on consumerist-centered reality thus limiting the exposure to non-materialist lifestyles.
Although the effects of target advertising are mainly focused on those targeted it also has an effect on those not targeted. Its unintended audiences often view an advertisement targeted at other groups and start forming judgments and decisions regarding the advertisement and even the brand and company behind the advertisement, these judgments may affect future consumer behavior (Cyril de Run, 2007).
The Network Advertising Initiative conducted a study in 2009 measuring the pricing and effectiveness of targeted advertising. It revealed that targeted advertising:
However, other studies show that targeted advertising, at least by gender, is not effective.
One of the major difficulties in measuring the economic efficiency of targeting, however, is being able to observe what would have happened in the absence of targeting since the users targeted by advertisers are more likely to convert than the general population.
Farahat and Bailey exploit a large-scale natural experiment on Yahoo! allowing them to measure the true economic impact of targeted advertising on brand searches and clicks. They find, assuming the cost per 1000 ad impressions (CPM) is $1, that:
Research shows that Content marketing in 2015 generates 3 times as many leads as traditional outbound marketing, but costs 62% less (Plus) showing how being able to advertise to targeted consumers is becoming the ideal way to advertise to the public.
As other stats show how 86% of people skip television adverts and 44% of people ignore direct mail, which also displays how advertising to the wrong group of people can be a waste of resources.
Benefits and Disadvantages:
Benefits:
There are many benefits of targeted advertising for both consumers and advertisers:
Consumers:
Targeted advertising benefits consumers because advertisers are able to effectively attract the consumers by using their purchasing and browsing habits this enables ads to be more apparent and useful for customers. Having ads that are related to the interests of the consumers allow the message to be received in a direct manner through effective touch points.
An example of how targeted advertising is beneficial to consumers if that if someone sees an ad targeted to them for something similar to an item they have previously viewed online and were interested in, they are more likely to buy it.
Consumers can benefit from targeted advertising in the following ways:
Advertiser:
Advertisers benefit with target advertising are reduced resource costs and creation of more effective ads by attracting consumers with a strong appeal to these products. Targeted advertising allows advertisers in reduced cost of advertisement by minimising "wasted" advertisements to non interested consumers. Targeted advertising captivate the attention of consumers they were aimed at resulting in higher return on investment for the company.
Because behavioral advertising enables advertisers to more easily determine user preference and purchasing habit, the ads will be more pertinent and useful for the consumers. By creating a more efficient and effective manner of advertising to the consumer, an advertiser benefits greatly and in the following ways:
Using information from consumers can benefit the advertiser by developing a more efficient campaign, targeted advertising is proven to work both effectively and efficiently (Gallagher & Parsons, 1997). They don't want to waste time and money advertising to the "wrong people".
Through technological advances, the internet has allowed advertisers to target consumers beyond the capabilities of traditional media, and target significantly larger amount (Bergemann & Bonatti, 2011). The main advantage of using targeted advertising is how it can help minimize wasted advertising by using detailed information about individuals who are intended for a product.
If consumers are produced these ads that are targeted for them, it is more likely they will be interested and click on them. 'Know thy consumer', is a simple principle used by advertisers, when businesses know information about consumers, it can be easier to target them and get them to purchase their product.
Some consumers do not mind if their information being used, and are more accepting to ads with easily accessible links. This is because they may appreciate adverts tailored to their preferences, rather than just generic ads. They are more likely to be directed to products they want, and possibly purchase them, in return generating more income for the business advertising.
Disadvantages:
Consumers: Targeted advertising raises privacy concerns. Targeted advertising is performed by analyzing consumers' activities through online services such as cookies and data-mining, both of which can be seen as detrimental to consumers' privacy. Marketers research consumers' online activity for targeted advertising campaigns like programmatic and SEO.
Consumers' privacy concerns revolve around today's unprecedented tracking capabilities and whether to trust their trackers. Targeted advertising aims to increase promotions' relevance to potential buyers, delivering ad campaign executions to specified consumers at critical stages in the buying decision process. This potentially limits a consumer's awareness of alternatives and reinforces selective exposure.
Advertiser: Targeting advertising is not a process performed overnight, it takes time and effort to analyse the behavior of consumers. This results in more expenses than the traditional advertising processes. As targeted advertising is seen more effective this is not always a disadvantage but there are cases where advertisers have not received the profit expected.
Targeted advertising has a limited reach to consumers, advertisers are not always aware that consumers change their minds and purchases which will no longer mean ads are apparent to them. Another disadvantage is that while using Cookies to track activity advertisers are unable to depict whether 1 or more consumers are using the same computer. This is apparent in family homes where multiple people from a broad age range are using the same device.
Controversies:
Targeted advertising has raised controversies, most particularly towards the privacy rights and policies. With behavioral targeting focusing in on specific user actions such as site history, browsing history, and buying behavior, this has raised user concern that all activity is being tracked.
Privacy International is a UK based registered charity that defends and promotes the right to privacy across the world. This organization is fighting in order to make Governments legislate in a way that protects the rights of the general public. According to them, from any ethical standpoint such interception of web traffic must be conditional on the basis of explicit and informed consent. And action must be taken where organisations can be shown to have acted unlawfully.
A survey conducted in the United States by the Pew Internet & American Life Project between January 20 and February 19, 2012 revealed that most of Americans are not in favor of targeted advertising, seeing it as an invasion of privacy. Indeed, 68% of those surveyed said they are "not okay" with targeted advertising because they do not like having their online behavior tracked and analyzed.
Another issue with targeted advertising is the lack of 'new' advertisements of goods or services. Seeing as all ads are tailored to be based on user preferences, no different products will be introduced to the consumer. Hence, in this case the consumer will be at a loss as they are not exposed to anything new.
Advertisers concentrate their resources on the consumer, which can be very effective when done right (Goldfarb & Tucker, 2011). When advertising doesn't work, consumer can find this creepy and start wondering how the advertiser learnt the information about them (Taylor et al., 2011).
Consumers can have concerns over ads targeted at them, which are basically too personal for comfort, feeling a need for control over their own data (Tucker, 2014).
In targeted advertising privacy is a complicated issue due to the type of protected user information and the number of parties involved. The three main parties involved in online advertising are the advertiser, the publisher and the network. People tend to want to keep their previously browsed websites private, although user's 'clickstreams' are being transferred to advertisers who work with ad networks.
The user's preferences and interests are visible through their clickstream and their behavioural profile is generated (Toubiana et al., 2010).
Many find this form of advertising to be concerning and see these tactics as manipulative and a sense of discrimination (Toubiana et al., 2010). As a result of this, a number of methods have been introduced in order to avoid advertising (Johnson, 2013). Internet users employing ad blockers are rapidly growing in numbers. A study conducted by PageFair found that from 2013 to 2014, there was a 41% increase of people using ad blocking software globally (PageFair, 2015).
See Also:
Imagine you slack off at work and read up online about the latest Gibson 1959 Les Paul electric guitar replica. On the way home, you see an ad for the same model on your phone, reminding you this is “the most desirable Les Paul ever.” Then before bed on your tablet, you see another ad with new details about the guitar.
You may think the guitar gods have singled you out—it is your destiny to own this instrument!
For advertisers, the process is divine in its own right. Over the past year, companies have substantially and successfully stepped up repeat ad targeting to the same user across home and work computers, smart phones and tablets. With little fanfare, the strategy is fast becoming the new norm.
“You really have a convergence of three or four different things that are creating a tremendous amount of change,” says Philip Smolin, senior vice president for strategy at California-based digital advertising agency Turn. “There may be one wave that is small and it doesn’t move your boat very much, but when you have three or four medium size waves that all converge at the same time, then it becomes a massive wave, and that is happening right now.”
One of these recent waves has been greater sophistication of companies engaged in “probabilistic matching,” the study of millions of Web users to determine who is likely to be the same person across devices. For example, Drawbridge, which specializes in matching users across devices, says it has linked 1.2 billion users across 3.6 billion devices—up from 1.5 billion devices just a year ago.
Another trend making all this matching possible is the continuing transformation of Internet advertising into a marketplace of instant decisions, based on what companies know about the user.
Firms you have never heard of, such as Drawbridge, Crosswise, and Tapad, learn about your devices and your interests by tracking billions of ad requests a day from Internet ad exchanges selling in real time. Potential buyers see the user’s device, IP address, browser, and other details, information that allows for a sort of fingerprinting. “We are getting very smart about associating the anonymous identifiers across the various devices,” says Kamakshi Sivaramakrishnan, founder and CEO of Drawbridge.
For example, a cell phone and tablet accessing the same IP address at home would be one clue, as would searches for the same product. You might look for “Chevy Cruze” on your phone and then search Edmunds.com for the same thing on your laptop. The same geographic location of the searches within a short time period, combined with other information, might suggest the same user.
In the last six months or so, these companies say they have sharply increased the accuracy of probabilistic matching. A Nielsen survey of Drawbridge data released in April found 97.3 percent accuracy in linking two or more devices; an earlier Nielsen survey of Tapad found 91.2 percent accuracy.
Another wave feeding the fast growth of cross-platform advertising is the stampede onto mobile devices. Just last month Google announced that users in the United States, Japan, and eight other countries now use mobile devices for more than half of their searches. U.S. mobile traffic soared 63 percent in 2014 alone, according to a report from Cisco.
Many consumers search on mobile devices but buy on larger-screen computers, giving advertisers ever more incentive to track across multiple screens. Ad agencies are also breaking down traditional walls between video, mobile, and display teams to forge a more integrated approach.
For example, Turn recently worked with an auto insurer’s campaign that started with a video ad on one platform and then moved to display ads on other devices. The results of such efforts are promising. Drawbridge says it ran a cross-platform campaign for women’s sandals in the middle of winter for a major fashion retailer and achieved three times greater response than traditional Internet advertising.
People who prefer not to be tracked can take some countermeasures, especially against what is called deterministic tracking. Signing into Google or Facebook as well as websites and apps using those logins confirms which devices you own.
So you can log off Facebook, Google, and other accounts, use different e-mail addresses to confuse marketers and use masking software such as Blur. “But the probabilistic stuff is really hard to stop because it is like all the detritus of one’s daily activities,” says Andrew Sudbury, chief technology officer and cofounder of privacy company Abine, which makes Blur.
People can opt out of Internet tracking through an industry program called AdChoices, but few know about it or bother.
Advertisers stress they match potential buyers across platforms without gathering individual names. “People freak out over retargeting. People think someone is watching them. No one is watching anyone. The machine has a number,” says Roland Cozzolino, chief technology officer at MediaMath, a digital advertising company that last year bought Tactads, a cross-device targeting agency. “I don’t know who you are, I don’t know any personal information about you. I just know that these devices are controlled by the same user.”
Companies that go too far risk the wrath of customers. Verizon generated headlines such as “Verizon’s super-cookies are a super privacy violation” earlier this year when the public learned that the carrier plants unique identifying codes dubbed “supercookies” on Web pages. Verizon now explains the process on its website and allows an opt-out.
Drawbridge recently started tracking smart televisions and cable boxes, but advertisers on the whole are cautiously approaching targeted TV commercials, even as many expect such ad personalization in the future. Industry officials say they want to turn up the temperature slowly on the frogs in the pot of advertising, lest they leap out and prod regulation."
[End of Article]
___________________________________________________________________________
Targeted Advertising (by Wikipedia)
Targeted advertising is a form of advertising where online advertisers can use sophisticated methods to target the most receptive audiences with certain traits, based on the product or person the advertiser is promoting. These traits can either be demographic which are focused on race, economic status, sex, age, the level of education, income level and employment or they can be psychographic focused which are based on the consumer's values, personality, attitudes, opinions, lifestyles and interests.
They can also be behavioral variables, such as browser history, purchase history, and other recent activity. Targeted advertising is focused on certain traits and the consumers who are likely to have a strong preference will receive the message instead of those who have no interest and whose preferences do not match a product's attribute. This eliminates wastage.
Traditional forms of advertising, including billboards, newspapers, magazines and radio, are progressively becoming replaced by online advertisements. Information and communication technology (ICT) space has transformed over recent years, resulting in targeted advertising to stretch across all ICT technologies, such as web, IPTV, and mobile environments.
In next generation advertising, the importance of targeted advertisements will radically increase, as it spreads across numerous ICT channels cohesively.
Through the emergence of new online channels, the need for targeted advertising is increasing because companies aim to minimize wasted advertising by means of information technology.
Most targeted new media advertising currently uses second-order proxies for targetings, such as tracking online or mobile web activities of consumers, associating historical web page consumer demographics with new consumer web page access, using a search word as the basis for implied interest, or contextual advertising.
Types of Targeted Advertising:
Web services are continually generating new business ventures and revenue opportunities for internet corporations. Companies have rapidly developing technological capabilities that allow them to gather information about web users. By tracking and monitoring what websites users visit, internet service providers can directly show ads that are relative to the consumer's preferences.
Most of the time, this consist of the last search done. For example, you search for a real estate, you will then be overloaded by real estate, that you care about or not and if you had buy the product or not. It's why Ads are totally bias these days. They just tend to suggest the last search you have done. Most of today's websites are using these targeting technology to track users' internet behavior and there is much debate over the privacy issues present.
Search engine marketing:
Further information: Search engine marketing
Search engine marketing uses search engines to reach target audiences. For example, Google's Google Re-marketing Campaigns are a type of targeted advertising where websites use the IP addresses of computers that have visited their websites to re-market their ad specifically to the user who has previously been on their website as they use websites that are a part of the Google display network, or when searching for keywords related to a product or service on the google search engine.
Dynamic remarketing can improve the targeted advertising as the ads are able to include the products or services that the consumers have previously viewed on the advertisers' website within the ads.
Google Adwords have different platforms how the ads appear. The Search Network displays the ads on 'Google Search, other Google sites such as Maps and Shopping, and hundreds of non-Google search partner websites that show AdWords ads matched to search results'.
'The Display Network includes a collection of Google websites (like Google Finance, Gmail, Blogger, and YouTube), partner sites, and mobile sites and apps that show AdWords ads matched to the content on a given page.' These two kinds of Advertising networks can be beneficial for each specific goal of the company, or type of company. For example, the search network can benefit a company with the goal of reaching consumers searching for a particular product or service.
Other ways Advertising campaigns are able to target the user is to use browser history and search history, for example, if the user typed in promotional pens in a search engine, such as Google; ads for promotional pens will appear at the top of the page above the organic pages, these ads will be targeted to the area of the users IP address, showing the product or service in the local area or surrounding regions, the higher ad position is a benefit of the ad having a higher quality score.
The ad quality is affected by the 6 components of the quality score:
- The ad's expected click-through rate
- The quality of the landing page
- The ad/search relevance
- Geographic performance
- The targeted devices
When ranked based on this criteria, will affect the advertiser by improving ad auction eligibility, actual cost per click (CPC), ad position, and ad position bid estimates; to summarize, the better the quality score, the better ad position, and lower costs.
Google uses its display network to track what users are looking at and to gather information about them. When a user goes onto a website that uses the google display network it will send a cookie to google, showing information on the user, what he or she searched, where they are from, found by the ip address, and then builds a profile around them, allowing google to easily target ads to the user more specifically.
For example, if a user went onto promotional companies' websites often, that sell promotional pens, google will gather data from the user such as age, gender, location and other demographic information as well as information on the websites visited, the user will then be put into a category of promotional products, allowing google to easily display ads on websites the user visits relating to promotional products. (Betrayed By Your Ads!) these types of adverts are also called behavioral advertisements as they track the website behaviour of the user and displays ads based on previous pages or searched terms. ("Examples Of Targeted Advertising")
Social media targeting:
Further information: Social media marketing
Social media targeting is a form of targeted advertising, that uses general targeting attributes such as geotargeting, behavioral targeting, socio-psychographic targeting, but gathers the information that consumer have provided on each social media platform. For example, on Facebook if a consumer has liked clothing pages they will receive ads based on those page likes and the area they have said they live in, this allows advertisers to target very specific consumers as they can specify cities and interests to their needs.
Social media also creates profiles of the consumer and only needs to look one place, one the users' profile to find all interests and 'likes'. E.g. Facebook lets advertisers target using broad characteristics like Gender, Age, and Location. Furthermore, they allow more narrow targeting based on Demographics, Behavior, and Interests (see a comprehensive list of Facebook's different types of targeting options).
TV and mobile targeting:
Another sphere targeted advertising occurs in is television. Advertisers can reach a consumer that is using digital cable, which is classified as Internet Protocol Television (IPTV). This is effective when information is collected about the user, their age, gender and location, and also their personal interests in films, etc. This data is then processed, optimized and then consumers are advertised to accordingly.
Since the early 2000s, advertising has been pervasive online and more recently in the mobile setting. Targeted advertising based on mobile devices allows more information about the consumer to be transmitted, not just their interests, but their information about their location and time.
A major concern about mobile users, when they don't have unlimited plan, they are force to download an Ads making them paying two times for these Ads (time and data). This allows advertisers to produce advertisements that could cater to their schedule and a more specific changing environment.
Content and contextual targeting:
Further information: Content marketing
The most straightforward method of targeting is content/contextual targeting. This is when advertisers put ads in a specific place, based on the relative content present (Schlee, 2013).
Another name used is content-oriented advertising, as it is corresponding the context being consumed. This targeting method can be used across different mediums, for example in an article online, about purchasing homes would have an advert associated with this context, like an insurance ad. This is usually achieved through an ad matching system which analyses the contents on a page or finds key words and presents a relevant advert, sometimes through pop-ups (Fan & Chang, 2010).
Though sometimes the ad matching system can fail, as it can neglect to tell the difference between positive and negative correlations. This can result in placing contradictory adverts, which are not appropriate to the content (Fan & Chang, 2010).
Technical targeting:
Technical targeting is associated with the user's own software or hardware status. The advertisement is altered depending on the user's available network bandwidth, for example if a user is on their mobile phone that has limited connection, the ad delivery system will display a version of the ad that is smaller for a faster data transfer rate, in theory but in practice they just spam you the same video, again and again.
Addressable advertising systems serve ads directly based on demographic, psychographic, or behavioral attributes associated with the consumer(s) exposed to the ad. These systems are always digital and must be addressable in that the end point which serves the ad (set-top box, website, or digital sign) must be capable of rendering an ad independently of any other end points based on consumer attributes specific to that end point at the time the ad is served.
Addressable advertising systems therefore must use consumer traits associated with the end points as the basis for selecting and serving ads.
Time targeting:
Time targeting is centered around time and focuses on the idea of fitting in around people's everyday lifestyles (Schlee, 2013). For example, scheduling specific ads at a timeframe from 5–7pm, when the typical commute home from work is.
Sociodemographic targeting:
Sociodemographic targeting focuses on the characteristics of consumers, including their age, gender, salary and nationality (Schlee, 2013). The idea is to target users specifically, using this data about them collected, for example, targeting a male in the age bracket of 18-24.
Facebook uses this form of targeting by showing advertisements relevant to the user's individual demographic on their account, this can show up in forms of banner ads, or commercial videos (Taylor et al., 2011).
Geographical and location-based targeting:
This type of advertising involves targeting different users based on their geographic location. IP addresses can signal the location of a user and can usually transfer the location through ZIP codes. (Schlee, 2013) Locations are then stored for users in static profiles, thus advertisers can easily target these individuals based on their geographic location.
A location-based service (LBS) is a mobile information service which allows spatial and temporal data transmission and can be used to an advertiser's advantage (Dhar & Varshney, 2011). This data can be harnessed from applications on the device that allow access to the location information (Peterson & Groot, 2009).
This type of targeted advertising focuses on localising content, for example a user could be prompted with options of activities in the area, for example places to eat, nearby shops etc. Although producing advertising off consumer's location-based services can improve the effectiveness of delivering ads, it can raise issues with the user's privacy (Li & Du, 2012).
Behavioral targeting:
Main article: Behavioral targeting
This form of targeted advertising is centered around the activity/actions of users, and is more easily achieved on web pages (Krumm, 2010). Information from browsing websites can be collected from data mining, which finds patterns in users search history.
Advertisers using this method believe it produces ads that will be more relevant to users, thus leading consumers be more likely influenced by them (Yan et al., 2009). If a consumer was frequently searching for plane ticket prices, the targeting system would recognise this and start showing related adverts across unrelated websites, such as airfare deals on Facebook. Its advantage is that it can target individual's interests, rather than target groups of people whose interests may vary (Schlee, 2013).
Re-targeting:
Retargeting is where advertisers use behavioural targeting to produce ads that follow users after users have looked at or purchased a particular item. An example of this is store catalogs, where stores subscribe customers to their email system after a purchase hoping that they draw attention to more items for continuous purchases. The main example of retargeting that has earned a reputation from most people are ads that follow users across the web, showing them the same items that they have looked at in the hope that they will purchase them.
Retargeting is a very effective process; by analysing consumers activities with the brand they can address their consumers' behaviour appropriately.
Through the emergence of new online channels, the need for targeted advertising is increasing because companies aim to minimize wasted advertising by means of information technology.
Most targeted new media advertising currently uses second-order proxies for targetings, such as tracking online or mobile web activities of consumers, associating historical web page consumer demographics with new consumer web page access, using a search word as the basis for implied interest, or contextual advertising.
Process:
Advertising provides advertisers with a direct line of communication to existing and prospective consumers.
By using a combination of words and/or pictures the general aim of the advertisement is to act as a "medium of information" (David Oglivy) making the means of delivery and to whom the information is delivered most important. Advertising should define how and when structural elements of advertisements influence receivers, knowing that all receivers are not the same and thus may not respond in a single, similar manner.
Targeted advertising serves the purpose of placing particular advertisements before specific groups so as to reach consumers who would be interested in the information. Advertisers aim to reach consumers as efficiently as possible with the belief that it will result in a more effective campaign.
By targeting, advertisers are able to identify when and where the ad should be positioned in order to achieve maximum profits. This requires an understanding of how customers' minds work (see also neuromarketing) so as to determine the best channel by which to communicate.
Types of targeting include, but are not limited to advertising based on demographics, psychographics, behavioral variables and contextual targeting.
Behavioral advertising is the most common form of targeting used online. Internet cookies are sent back and forth between an internet server and the browser, that allows a user to be identified or to track their progressions. Cookies provide detail on what pages a consumer visits, the amount of time spent viewing each page, the links clicked on; and searches and interactions made.
From this information, the cookie issuer gathers an understanding of the user's browsing tendencies and interests generating a profile. Analysing the profile, advertisers are able to create defined audience segments based upon users with similar returned similar information, hence profiles. Tailored advertising is then placed in front of the consumer based upon what organisations working on behalf of the advertisers assume are the interests of the consumer.
These advertisements have been formatted so as to appear on pages and in front of users that it would most likely appeal to based on their profiles. For example, under behavioral targeting if a user is known to have recently visited a number of automotive shopping and comparison sites based on the data recorded by cookies stored on the user's computer, the user can then be served automotive related advertisements when visiting other sites.
So behavioral advertising is reliant on data both wittingly and unwittingly provided by users and is made up of two different forms: one involving the delivery of advertising based on assessment of user's web movements; the second involving the examination of communication and information as it passes through the gateways of internet service providers.
Demographic targeting was the first and most basic form of targeting used online. involves segmenting an audience into more specific groups using parameters such as gender, age, ethnicity, annual income, parental status etc. All members in the group share the common trait.
So, when an advertiser wishes to run a campaign aimed at a specific group of people then that campaign is intended only for the group that contains those traits at which the campaign is targeted. Having finalized the advertiser's demographic target, a website or a website section is chosen as a medium because a large proportion of the targeted audience utilizes that form of media.
Segmentation using psychographics Is based on an individual's personality, values, interests and lifestyles. A recent study concerning what forms of media people use- conducted by the Entertainment Technology Center at the University of Southern California, the Hallmark Channel, and E-Poll Market Research- concludes that a better predictor of media usage is the user's lifestyle.
Researchers concluded that while cohorts of these groups may have similar demographic profiles, they may have different attitudes and media usage habits. Psychographics can provide further insight by distinguishing an audience into specific groups by using their personal traits.
Once acknowledging this is the case, advertisers can begin to target customers having recognized that factors other than age for example provides greater insight into the customer.
Contextual advertising is a strategy to place advertisements on media vehicles, such as specific websites or print magazines, whose themes are relevant to the promoted products (Joeng & King, 2005, p. 2). Advertisers apply this strategy in order to narrow-target their audiences (Belch & Belch, 2009, p. 2; Jeong and King, 2005). Advertisements are selected and served by automated systems based on the identity of the user and the displayed content of the media.
The advertisements will be displayed across the user's different platforms and are chosen based on searches for key words; appearing as either a web page or pop up ads. It is a form of targeted advertising in which the content of an ad is in direct correlation to the content of the webpage the user is viewing.
The major psychographic segments:
Personality: Every brand, service or product has itself a personality, how it is viewed by the public and the community and marketers will create these personalities to match the personality traits of their target market. Marketers and advertisers create these personalities because when a consumer can relate to the characteristics of a brand, service or product they are more likely to feel connected towards the product and purchase it.
Lifestyle: Everyone is different and advertisers compensate for this, they know different people lead different lives, have different lifestyles and different wants and needs at different times in their consumers lives ("Psychographic Market Segmentation | Local Directive", 2016).
Advertisers who base their segmentation on psychographic characteristics promote their product as the solution to these wants and needs. Segmentation by lifestyle considers where the consumer is in their life cycle and what is important to them at that exact time.
Opinions, attitudes, interests and hobbies: Psychographic segmentation also includes opinions on religious, gender and politics, sporting and recreational activities, views on the environment and arts and cultural issues. The views that the market segments hold and the activities they participate in will have a massive impact on the products and services they purchase and it will even affect how they respond to the message.
Alternatives to behavioral advertising and psychographic targeting include geographic targeting and demographic targeting
When advertisers want to reach as many consumers as efficiently as possible they use a six step process:
- identify the objectives the advertisers do this by setting benchmarks, identifying products or proposals, identifying the core values and strategic objectives. This step also includes listing and monitoring competitors content and creating objectives for the next 12-18 months.
- The second step understanding buyers, is all about identifying what types of buyers the advertiser wants to target and identifying the buying process for the consumers.
- Identifying gaps is key as this illustrates all of the gaps in the content and finds what is important for the buying process and the stages of the content.
- Stage 4 is where the content is created and the stage where the key messages are identified and the quality bench line is discussed.
- Organizing distribution is key for maximising the potential of the content, these can be social media, blogs or google display networks.
- The last step is vital for an advertiser as they need to measure the return on the investment (ROI) there are multiple ways to measure performance, these can be tracking web traffic, sales lead quality, and/ or social media sharing.
Alternatives to behavioral advertising include audience targeting, contextual targeting, and psychographic targeting.
Effectiveness:
Targeting improves the effectiveness of advertising it reduces the wastage created by sending advertising to consumers who are unlikely to purchase that product, target advertising or improved targeting will lead to lower advertising costs and expenditures.
The effects of advertising on society and those targeted are all implicitly underpinned by consideration of whether advertising compromises autonomous choice (Sneddon, 2001).
Those arguing for the ethical acceptability of advertising claim either that, because of the commercially competitive context of advertising, the consumer has a choice over what to accept and what to reject.
Humans have the cognitive competence and are equipped with the necessary faculties to decide whether to be affected by adverts (Shiffman, 1990). Those arguing against note, for example, that advertising can make us buy things we do not want or that, as advertising is enmeshed in a capitalist system, it only presents choices based on consumerist-centered reality thus limiting the exposure to non-materialist lifestyles.
Although the effects of target advertising are mainly focused on those targeted it also has an effect on those not targeted. Its unintended audiences often view an advertisement targeted at other groups and start forming judgments and decisions regarding the advertisement and even the brand and company behind the advertisement, these judgments may affect future consumer behavior (Cyril de Run, 2007).
The Network Advertising Initiative conducted a study in 2009 measuring the pricing and effectiveness of targeted advertising. It revealed that targeted advertising:
- Secured an average of 2.7 times as much revenue per ad as non-targeted "run of network" advertising.
- Twice as effective at converting users who click on the ads into buyers
However, other studies show that targeted advertising, at least by gender, is not effective.
One of the major difficulties in measuring the economic efficiency of targeting, however, is being able to observe what would have happened in the absence of targeting since the users targeted by advertisers are more likely to convert than the general population.
Farahat and Bailey exploit a large-scale natural experiment on Yahoo! allowing them to measure the true economic impact of targeted advertising on brand searches and clicks. They find, assuming the cost per 1000 ad impressions (CPM) is $1, that:
- The marginal cost of a brand-related search resulting from ads is $15.65 per search, but is only $1.69 per search from a targeted campaign.
- The marginal cost of a click is 72 cents, but only 16 cents from a targeted campaign.
- The variation in CTR lifts from targeted advertising campaigns is mostly determined by pre-existing brand interest.
Research shows that Content marketing in 2015 generates 3 times as many leads as traditional outbound marketing, but costs 62% less (Plus) showing how being able to advertise to targeted consumers is becoming the ideal way to advertise to the public.
As other stats show how 86% of people skip television adverts and 44% of people ignore direct mail, which also displays how advertising to the wrong group of people can be a waste of resources.
Benefits and Disadvantages:
Benefits:
There are many benefits of targeted advertising for both consumers and advertisers:
Consumers:
Targeted advertising benefits consumers because advertisers are able to effectively attract the consumers by using their purchasing and browsing habits this enables ads to be more apparent and useful for customers. Having ads that are related to the interests of the consumers allow the message to be received in a direct manner through effective touch points.
An example of how targeted advertising is beneficial to consumers if that if someone sees an ad targeted to them for something similar to an item they have previously viewed online and were interested in, they are more likely to buy it.
Consumers can benefit from targeted advertising in the following ways:
- More effective delivery of desired product or service directly to the consumer (Keating, n.d): having assumed the traits or interests of the consumer from their targeting, advertisements that will appeal and engage the customer are used.
- More direct delivery of a message that relates to the consumer's interest (Keating, n.d): advertisements are delivered to the customer in a manner that is comfortable, whether it be jargon or a certain medium, the delivery of the message is part of the consumer's 'lifestyle'
Advertiser:
Advertisers benefit with target advertising are reduced resource costs and creation of more effective ads by attracting consumers with a strong appeal to these products. Targeted advertising allows advertisers in reduced cost of advertisement by minimising "wasted" advertisements to non interested consumers. Targeted advertising captivate the attention of consumers they were aimed at resulting in higher return on investment for the company.
Because behavioral advertising enables advertisers to more easily determine user preference and purchasing habit, the ads will be more pertinent and useful for the consumers. By creating a more efficient and effective manner of advertising to the consumer, an advertiser benefits greatly and in the following ways:
- More efficient campaign development (Keating, n.d): by having information about the consumer an advertiser is able to make more concise decisions on how to best communicate with them.
- Better use of advertising dollar (Keating, n.d): A greater understanding of the targeted audience will allow an advertiser to achieve better results with an advertising campaign
- Increased return on investment: Targeted advertisements will yield higher results for lower costs.
Using information from consumers can benefit the advertiser by developing a more efficient campaign, targeted advertising is proven to work both effectively and efficiently (Gallagher & Parsons, 1997). They don't want to waste time and money advertising to the "wrong people".
Through technological advances, the internet has allowed advertisers to target consumers beyond the capabilities of traditional media, and target significantly larger amount (Bergemann & Bonatti, 2011). The main advantage of using targeted advertising is how it can help minimize wasted advertising by using detailed information about individuals who are intended for a product.
If consumers are produced these ads that are targeted for them, it is more likely they will be interested and click on them. 'Know thy consumer', is a simple principle used by advertisers, when businesses know information about consumers, it can be easier to target them and get them to purchase their product.
Some consumers do not mind if their information being used, and are more accepting to ads with easily accessible links. This is because they may appreciate adverts tailored to their preferences, rather than just generic ads. They are more likely to be directed to products they want, and possibly purchase them, in return generating more income for the business advertising.
Disadvantages:
Consumers: Targeted advertising raises privacy concerns. Targeted advertising is performed by analyzing consumers' activities through online services such as cookies and data-mining, both of which can be seen as detrimental to consumers' privacy. Marketers research consumers' online activity for targeted advertising campaigns like programmatic and SEO.
Consumers' privacy concerns revolve around today's unprecedented tracking capabilities and whether to trust their trackers. Targeted advertising aims to increase promotions' relevance to potential buyers, delivering ad campaign executions to specified consumers at critical stages in the buying decision process. This potentially limits a consumer's awareness of alternatives and reinforces selective exposure.
Advertiser: Targeting advertising is not a process performed overnight, it takes time and effort to analyse the behavior of consumers. This results in more expenses than the traditional advertising processes. As targeted advertising is seen more effective this is not always a disadvantage but there are cases where advertisers have not received the profit expected.
Targeted advertising has a limited reach to consumers, advertisers are not always aware that consumers change their minds and purchases which will no longer mean ads are apparent to them. Another disadvantage is that while using Cookies to track activity advertisers are unable to depict whether 1 or more consumers are using the same computer. This is apparent in family homes where multiple people from a broad age range are using the same device.
Controversies:
Targeted advertising has raised controversies, most particularly towards the privacy rights and policies. With behavioral targeting focusing in on specific user actions such as site history, browsing history, and buying behavior, this has raised user concern that all activity is being tracked.
Privacy International is a UK based registered charity that defends and promotes the right to privacy across the world. This organization is fighting in order to make Governments legislate in a way that protects the rights of the general public. According to them, from any ethical standpoint such interception of web traffic must be conditional on the basis of explicit and informed consent. And action must be taken where organisations can be shown to have acted unlawfully.
A survey conducted in the United States by the Pew Internet & American Life Project between January 20 and February 19, 2012 revealed that most of Americans are not in favor of targeted advertising, seeing it as an invasion of privacy. Indeed, 68% of those surveyed said they are "not okay" with targeted advertising because they do not like having their online behavior tracked and analyzed.
Another issue with targeted advertising is the lack of 'new' advertisements of goods or services. Seeing as all ads are tailored to be based on user preferences, no different products will be introduced to the consumer. Hence, in this case the consumer will be at a loss as they are not exposed to anything new.
Advertisers concentrate their resources on the consumer, which can be very effective when done right (Goldfarb & Tucker, 2011). When advertising doesn't work, consumer can find this creepy and start wondering how the advertiser learnt the information about them (Taylor et al., 2011).
Consumers can have concerns over ads targeted at them, which are basically too personal for comfort, feeling a need for control over their own data (Tucker, 2014).
In targeted advertising privacy is a complicated issue due to the type of protected user information and the number of parties involved. The three main parties involved in online advertising are the advertiser, the publisher and the network. People tend to want to keep their previously browsed websites private, although user's 'clickstreams' are being transferred to advertisers who work with ad networks.
The user's preferences and interests are visible through their clickstream and their behavioural profile is generated (Toubiana et al., 2010).
Many find this form of advertising to be concerning and see these tactics as manipulative and a sense of discrimination (Toubiana et al., 2010). As a result of this, a number of methods have been introduced in order to avoid advertising (Johnson, 2013). Internet users employing ad blockers are rapidly growing in numbers. A study conducted by PageFair found that from 2013 to 2014, there was a 41% increase of people using ad blocking software globally (PageFair, 2015).
See Also:
Comparison Shopping Websites, including a List
YouTube Video of Best Comparison Shopping Websites - Top 10 List
Pictured below: Best online shopping comparison websites

Click here for a List of Comparison Shopping Websites.
A comparison shopping website, sometimes called a price comparison website, Price Analysis tool, comparison shopping agent, shopbot or comparison shopping engine, is a vertical search engine that shoppers use to filter and compare products based on price, features, reviews and other criteria.
Most comparison shopping sites aggregate product listings from many different retailers but do not directly sell products themselves, instead earning money from affiliate marketing agreements.
Click on any of the following blue hyperlinks for more about Comparison Shopping Websites:
A comparison shopping website, sometimes called a price comparison website, Price Analysis tool, comparison shopping agent, shopbot or comparison shopping engine, is a vertical search engine that shoppers use to filter and compare products based on price, features, reviews and other criteria.
Most comparison shopping sites aggregate product listings from many different retailers but do not directly sell products themselves, instead earning money from affiliate marketing agreements.
Click on any of the following blue hyperlinks for more about Comparison Shopping Websites:
- History
- Comparison shopping agent including Services
- Technology
- Comparison of sites
- Business models
- Google Panda and price comparison
- Niche players, fake test sites and fraud
- Google EU Court Case
- See also:
Timeline of Internet Conflicts
YouTube Video: What are DDoS attacks? DDoS Explained - Radware
Pictured below: Conflict, Friendships and Technology by PEW Research

The Internet has a long history of turbulent relations, major maliciously designed disruptions (such as wide scale computer virus incidents, DOS and DDOS attacks that cripple services, and organized attacks that cripple major online communities), and other conflicts.
This is a list of known and documented Internet, Usenet, virtual community and World Wide Web related conflicts, and of conflicts that touch on both offline and online worlds with possibly wider reaching implications.
Spawned from the original ARPANET, the modern Internet, World Wide Web and other services on it, such as virtual communities (bulletin boards, forums, and Massively multiplayer online games) have grown exponentially.
Such prolific growth of population, mirroring "offline" society, contributes to the amount of conflicts and problems online growing each year. Today, billions of people in nearly all countries use various parts of the Internet.
Inevitably, as in "brick and mortar" or offline society, the virtual equivalent of major turning points, conflicts, and disruptions—the online equivalents of the falling of the Berlin Wall, the creation of the United Nations, spread of disease, and events like the Iraqi invasion of Kuwait will occur.
Click on any of the following blue hyperlinks for more about Internet Conflicts for any specified period of time:
This is a list of known and documented Internet, Usenet, virtual community and World Wide Web related conflicts, and of conflicts that touch on both offline and online worlds with possibly wider reaching implications.
Spawned from the original ARPANET, the modern Internet, World Wide Web and other services on it, such as virtual communities (bulletin boards, forums, and Massively multiplayer online games) have grown exponentially.
Such prolific growth of population, mirroring "offline" society, contributes to the amount of conflicts and problems online growing each year. Today, billions of people in nearly all countries use various parts of the Internet.
Inevitably, as in "brick and mortar" or offline society, the virtual equivalent of major turning points, conflicts, and disruptions—the online equivalents of the falling of the Berlin Wall, the creation of the United Nations, spread of disease, and events like the Iraqi invasion of Kuwait will occur.
Click on any of the following blue hyperlinks for more about Internet Conflicts for any specified period of time:
Global Internet Usage
YouTube Video: We're building a dystopia just to make people click on ads
by Zeynep Tufekci (TED) (For more, see below)
Pictured Below: World Internet Users Statistics and 2018 World Population Stats
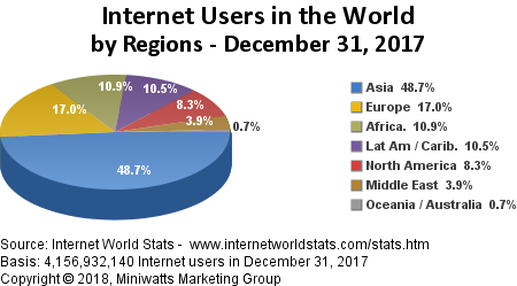
Expansion of above TED YouTube Video:
"We're building an artificial intelligence-powered dystopia, one click at a time, says technosociologist Zeynep Tufecki.
In an eye-opening talk, she details how the same algorithms companies like Facebook, Google and Amazon use to get you to click on ads are also used to organize your access to political and social information. And the machines aren't even the real threat. What we need to understand is how the powerful might use AI to control us -- and what we can do in response."
Global Internet usage refers to the number of people who use the Internet worldwide, which can be displayed using tables, charts, maps and articles which contain more detailed information on a wide range of usage measures.
Click on any of the following blue hyperlinks for more about Global Internet Usage:
"We're building an artificial intelligence-powered dystopia, one click at a time, says technosociologist Zeynep Tufecki.
In an eye-opening talk, she details how the same algorithms companies like Facebook, Google and Amazon use to get you to click on ads are also used to organize your access to political and social information. And the machines aren't even the real threat. What we need to understand is how the powerful might use AI to control us -- and what we can do in response."
Global Internet usage refers to the number of people who use the Internet worldwide, which can be displayed using tables, charts, maps and articles which contain more detailed information on a wide range of usage measures.
Click on any of the following blue hyperlinks for more about Global Internet Usage:
- Internet users
- Broadband usage
- Internet hosts
- Web index
- IPv4 addresses
- Languages
- Censorship and surveillance
- See also:
- Digital rights
- Fiber to the premises by country
- Internet access
- Internet traffic
- List of countries by Internet connection speeds
- List of countries by number of mobile phones in use
- List of social networking websites
- Zettabyte Era
- "ICT Data and Statistics", International Telecommunications Union (ITU).
- Internet Live Stats, Real Time Statistics Project.
- Internet World Stats: Usage and Population Statistics, Miniwatts Marketing Group.
- "40 maps that explain the internet", Timothy B. Lee, Vox Media, 2 June 2014.
- "Information Geographies", Oxford Internet Institute.
- "Internet Monitor", a research project of the Berkman Center for Internet & Society at Harvard University to evaluate, describe, and summarize the means, mechanisms, and extent of Internet access, content controls and activity around the world.
Wiki, including a List of Wiki Websites
YouTue Video: Interview with Ward Cunningham, inventor of the wiki
Pictured Below: Ward Cunningham

Click here for a List of Wiki Websites.
A wiki is a website on which users collaboratively modify content and structure directly from the web browser. In a typical wiki, text is written using a simplified markup language and often edited with the help of a rich-text editor.
A wiki is run using wiki software, otherwise known as a wiki engine. A wiki engine is a type of content management system, but it differs from most other such systems, including blog software, in that the content is created without any defined owner or leader, and wikis have little implicit structure, allowing structure to emerge according to the needs of the users.
There are dozens of different wiki engines in use, both standalone and part of other software, such as bug tracking systems. Some wiki engines are open source, whereas others are proprietary. Some permit control over different functions (levels of access); for example, editing rights may permit changing, adding or removing material. Others may permit access without enforcing access control. Other rules may be imposed to organize content.
The online encyclopedia project Wikipedia is by far the most popular wiki-based website, and is one of the most widely viewed sites of any kind in the world, having been ranked in the top ten since 2007.
Wikipedia is not a single wiki but rather a collection of hundreds of wikis, one for each language. There are tens of thousands of other wikis in use, both public and private, including wikis functioning as knowledge management resources, notetaking tools, community websites and intranets. The English-language
Wikipedia has the largest collection of articles; as of September 2016, it had over five million articles. Ward Cunningham, the developer of the first wiki software, WikiWikiWeb, originally described it as "the simplest online database that could possibly work". "Wiki" is a Hawaiian word meaning "quick".
Click on any of the following blue hyperlinks for more about Wiki:
A wiki is a website on which users collaboratively modify content and structure directly from the web browser. In a typical wiki, text is written using a simplified markup language and often edited with the help of a rich-text editor.
A wiki is run using wiki software, otherwise known as a wiki engine. A wiki engine is a type of content management system, but it differs from most other such systems, including blog software, in that the content is created without any defined owner or leader, and wikis have little implicit structure, allowing structure to emerge according to the needs of the users.
There are dozens of different wiki engines in use, both standalone and part of other software, such as bug tracking systems. Some wiki engines are open source, whereas others are proprietary. Some permit control over different functions (levels of access); for example, editing rights may permit changing, adding or removing material. Others may permit access without enforcing access control. Other rules may be imposed to organize content.
The online encyclopedia project Wikipedia is by far the most popular wiki-based website, and is one of the most widely viewed sites of any kind in the world, having been ranked in the top ten since 2007.
Wikipedia is not a single wiki but rather a collection of hundreds of wikis, one for each language. There are tens of thousands of other wikis in use, both public and private, including wikis functioning as knowledge management resources, notetaking tools, community websites and intranets. The English-language
Wikipedia has the largest collection of articles; as of September 2016, it had over five million articles. Ward Cunningham, the developer of the first wiki software, WikiWikiWeb, originally described it as "the simplest online database that could possibly work". "Wiki" is a Hawaiian word meaning "quick".
Click on any of the following blue hyperlinks for more about Wiki:
- Characteristics
- History
- Alternative definitions
- Implementations
- Trust and security
- Communities
- Conferences
- Rules
- Legal environment
- See also:
- Comparison of wiki software
- Content management system
- CURIE
- Dispersed knowledge
- Mass collaboration
- Universal Edit Button
- Wikis and education
- Exploring with Wiki, an interview with Ward Cunningham by Bill Verners
- WikiIndex and WikiApiary, directories of wikis
- WikiMatrix, a website for comparing wiki software and hosts
- WikiPapers, a wiki about publications about wikis
- WikiTeam, a volunteer group to preserve wikis
- Murphy, Paula (April 2006). Topsy-turvy World of Wiki. University of California.
- Ward Cunningham's correspondence with etymologists
The Internet Corporation for Assigned Names and Numbers (ICANN)
YouTube Video: What does ICANN Do?
Pictured below: DNS and WHOIS - How it Works: WHOIS services are mainly run by registrars and registries; for example Public Interest Registry (PIR) maintains the .ORG registry and associated WHOIS service. ICANN organization coordinates the central registry for Internet resources, which includes a reference to the WHOIS server of the responsible registry as well as the contact details of this registry.
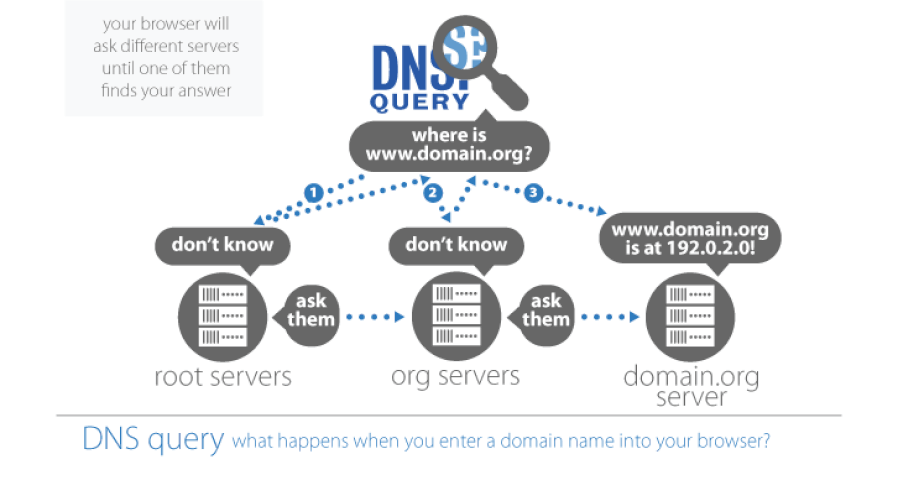
The Internet Corporation for Assigned Names and Numbers (ICANN) is a nonprofit organization responsible for coordinating the maintenance and procedures of several databases related to the namespaces and numerical spaces of the Internet, ensuring the network's stable and secure operation.
ICANN performs the actual technical maintenance work of the Central Internet Address pools and DNS root zone registries pursuant to the Internet Assigned Numbers Authority (IANA) function contract.
The contract regarding the IANA stewardship functions between ICANN and the National Telecommunications and Information Administration (NTIA) of the United States Department of Commerce ended on October 1, 2016, formally transitioning the functions to the global multistakeholder community.
Much of its work has concerned the Internet's global Domain Name System (DNS), including policy development for internationalization of the DNS system, introduction of new generic top-level domains (TLDs), and the operation of root name servers. The numbering facilities ICANN manages include the Internet Protocol address spaces for IPv4 and IPv6, and assignment of address blocks to regional Internet registries. ICANN also maintains registries of Internet Protocol identifiers.
ICANN's primary principles of operation have been described as helping preserve the operational stability of the Internet; to promote competition; to achieve broad representation of the global Internet community; and to develop policies appropriate to its mission through bottom-up, consensus-based processes.
ICANN's creation was announced publicly on September 17, 1998, and it formally came into being on September 30, 1998, incorporated in the U.S. state of California.
Originally headquartered in Marina del Rey in the same building as the University of Southern California's Information Sciences Institute (ISI)], its offices are now in the Playa Vista neighborhood of Los Angeles.
Click on any of the following blue hyperlinks for more about ICANN:
ICANN performs the actual technical maintenance work of the Central Internet Address pools and DNS root zone registries pursuant to the Internet Assigned Numbers Authority (IANA) function contract.
The contract regarding the IANA stewardship functions between ICANN and the National Telecommunications and Information Administration (NTIA) of the United States Department of Commerce ended on October 1, 2016, formally transitioning the functions to the global multistakeholder community.
Much of its work has concerned the Internet's global Domain Name System (DNS), including policy development for internationalization of the DNS system, introduction of new generic top-level domains (TLDs), and the operation of root name servers. The numbering facilities ICANN manages include the Internet Protocol address spaces for IPv4 and IPv6, and assignment of address blocks to regional Internet registries. ICANN also maintains registries of Internet Protocol identifiers.
ICANN's primary principles of operation have been described as helping preserve the operational stability of the Internet; to promote competition; to achieve broad representation of the global Internet community; and to develop policies appropriate to its mission through bottom-up, consensus-based processes.
ICANN's creation was announced publicly on September 17, 1998, and it formally came into being on September 30, 1998, incorporated in the U.S. state of California.
Originally headquartered in Marina del Rey in the same building as the University of Southern California's Information Sciences Institute (ISI)], its offices are now in the Playa Vista neighborhood of Los Angeles.
Click on any of the following blue hyperlinks for more about ICANN:
- History
- Notable events
- Structure
- Activities
- Criticism
- See also:
- Official website
- Alternative DNS root
- Domain name scams
- Domain Name System
- IEEE Registration Authority
- Internet Assigned Numbers Authority (IANA)
- InterNIC
- List of ICANN meetings
- Montevideo Statement on the Future of Internet Cooperation
- NetMundial Initiative, a plan for international governance of the Internet first proposed at the Global Multistakeholder Meeting on the Future of Internet Governance (GMMFIG) conference, April 23–24, 2014).
- Network Solutions
- OneWebDay
- OpenNIC
- Trademark Clearinghouse
- Uniform Domain-Name Dispute-Resolution Policy
- Wikimedia Commons has media related to ICANN.
- ICANN DNS Operations
- "ICANN Wiki". ICANN. People and companies related to ICANN
- Ball, James; Mathieu-Leger, Laurence (February 28, 2014). "Who holds the seven keys to the internet?" (video). Technology.
Web Design
YouTube Video of Top 10 Web Moments of 2015 by WatchMojo
YouTube Video of Top web design trends in 2022
YouTube Video: How does Google Search work?
Pictured below: Example of the Home Page for "Our Generation USA!"
YouTube Video of Top 10 Web Moments of 2015 by WatchMojo
YouTube Video of Top web design trends in 2022
YouTube Video: How does Google Search work?
Pictured below: Example of the Home Page for "Our Generation USA!"
Web design encompasses many different skills and disciplines in the production and maintenance of websites.
The different areas of web design include:
Often many individuals will work in teams covering different aspects of the design process, although some designers will cover them all. The term web design is normally used to describe the design process relating to the front-end (client side) design of a website including writing mark up.
Web design partially overlaps web engineering in the broader scope of web development. Web designers are expected to have an awareness of usability and if their role involves creating mark up then they are also expected to be up to date with web accessibility guidelines.
Tools and Technologies:
Web designers use a variety of different tools depending on what part of the production process they are involved in. These tools are updated over time by newer standards and software but the principles behind them remain the same. Web designers use both vector and raster graphics editors to create web-formatted imagery or design prototypes.
Technologies used to create websites include W3C standards like HTML and CSS, which can be hand-coded or generated by WYSIWYG editing software. Other tools web designers might use include mark up validators and other testing tools for usability and accessibility to ensure their websites meet web accessibility guidelines.
Skills and techniques include:
Marketing and communication design
Marketing and communication design on a website may identify what works for its target market. This can be an age group or particular strand of culture; thus the designer may understand the trends of its audience.
Designers may also understand the type of website they are designing, meaning, for example, that (B2B) business-to-business website design considerations might differ greatly from a consumer targeted website such as a retail or entertainment website. Careful consideration might be made to ensure that the aesthetics or overall design of a site do not clash with the clarity and accuracy of the content or the ease of web navigation, especially on a B2B website.
Designers may also consider the reputation of the owner or business the site is representing to make sure they are portrayed favorably.
User experience design and interactive design
User understanding of the content of a website often depends on user understanding of how the website works. This is part of the user experience design.
User experience is related to layout, clear instructions and labeling on a website. How well a user understands how they can interact on a site may also depend on the interactive design of the site. If a user perceives the usefulness of the website, they are more likely to continue using it.
Users who are skilled and well versed with website use may find a more distinctive, yet less intuitive or less user-friendly website interface useful nonetheless. However, users with less experience are less likely to see the advantages or usefulness of a less intuitive website interface. This drives the trend for a more universal user experience and ease of access to accommodate as many users as possible regardless of user skill.
Much of the user experience design and interactive design are considered in the user interface design.
Advanced interactive functions may require plug-ins if not advanced coding language skills.
Choosing whether or not to use interactivity that requires plug-ins is a critical decision in user experience design. If the plug-in doesn't come pre-installed with most browsers, there's a risk that the user will have neither the know how or the patience to install a plug-in just to access the content. If the function requires advanced coding language skills, it may be too costly in either time or money to code compared to the amount of enhancement the function will add to the user experience.
There's also a risk that advanced interactivity may be incompatible with older browsers or hardware configurations. Publishing a function that doesn't work reliably is potentially worse for the user experience than making no attempt. It depends on the target audience if it's likely to be needed or worth any risks.
Page layout:
Part of the user interface design is affected by the quality of the page layout. For example, a designer may consider whether the site's page layout should remain consistent on different pages when designing the layout.
Page pixel width may also be considered vital for aligning objects in the layout design. The most popular fixed-width websites generally have the same set width to match the current most popular browser window, at the current most popular screen resolution, on the current most popular monitor size. Most pages are also center-aligned for concerns of aesthetics on larger screens.
Fluid layouts increased in popularity around 2000 as an alternative to HTML-table-based layouts and grid-based design in both page layout design principle and in coding technique, but were very slow to be adopted. This was due to considerations of screen reading devices and varying windows sizes which designers have no control over.
Accordingly, a design may be broken down into units (sidebars, content blocks, embedded advertising areas, navigation areas) that are sent to the browser and which will be fitted into the display window by the browser, as best it can.
As the browser does recognize the details of the reader's screen (window size, font size relative to window etc.) the browser can make user-specific layout adjustments to fluid layouts, but not fixed-width layouts. Although such a display may often change the relative position of major content units, sidebars may be displaced below body text rather than to the side of it.
This is a more flexible display than a hard-coded grid-based layout that doesn't fit the device window. In particular, the relative position of content blocks may change while leaving the content within the block unaffected. This also minimizes the user's need to horizontally scroll the page.
Responsive Web Design is a newer approach, based on CSS3, and a deeper level of per-device specification within the page's stylesheet through an enhanced use of the CSS @media rule.
In March 2018 Google announced they would be rolling out mobile-first indexing. Sites using responsive design are well placed to ensure they meet this new approach.
Typography:
Web designers may choose to limit the variety of website typefaces to only a few which are of a similar style, instead of using a wide range of typefaces or type styles. Most browsers recognize a specific number of safe fonts, which designers mainly use in order to avoid complications.
Font downloading was later included in the CSS3 fonts module and has since been implemented in Safari 3.1, Opera 10 and Mozilla Firefox 3.5. This has subsequently increased interest in web typography, as well as the usage of font downloading.
Most site layouts incorporate negative space to break the text up into paragraphs and also avoid center-aligned text.
Motion graphics
The page layout and user interface may also be affected by the use of motion graphics. The choice of whether or not to use motion graphics may depend on the target market for the website. Motion graphics may be expected or at least better received with an entertainment-oriented website.
However, a website target audience with a more serious or formal interest (such as business, community, or government) might find animations unnecessary and distracting if only for entertainment or decoration purposes. This doesn't mean that more serious content couldn't be enhanced with animated or video presentations that is relevant to the content. In either case, motion graphic design may make the difference between more effective visuals or distracting visuals.
Motion graphics that are not initiated by the site visitor can produce accessibility issues. The World Wide Web consortium accessibility standards require that site visitors be able to disable the animations.
Quality of code:
Website designers may consider it to be good practice to conform to standards. This is usually done via a description specifying what the element is doing. Failure to conform to standards may not make a website unusable or error prone, but standards can relate to the correct layout of pages for readability as well making sure coded elements are closed appropriately.
This includes errors in code, more organized layout for code, and making sure IDs and classes are identified properly. Poorly-coded pages are sometimes colloquially called tag soup.
Validating via W3C can only be done when a correct DOCTYPE declaration is made, which is used to highlight errors in code. The system identifies the errors and areas that do not conform to web design standards. This information can then be corrected by the user.
Generated content:
There are two ways websites are generated: statically or dynamically:
Static websites:
Main article: Static web page
A static website stores a unique file for every page of a static website. Each time that page is requested, the same content is returned. This content is created once, during the design of the website. It is usually manually authored, although some sites use an automated creation process, similar to a dynamic website, whose results are stored long-term as completed pages. These automatically-created static sites became more popular around 2015, with generators such as Jekyll and Adobe Muse.
The benefits of a static website are that they were simpler to host, as their server only needed to serve static content, not execute server-side scripts. This required less server administration and had less chance of exposing security holes. They could also serve pages more quickly, on low-cost server hardware. These advantage became less important as cheap web hosting expanded to also offer dynamic features, and virtual servers offered high performance for short intervals at low cost.
Almost all websites have some static content, as supporting assets such as images and stylesheets are usually static, even on a website with highly dynamic pages.
Dynamic websites:
Main article: Dynamic web page
Dynamic websites are generated on the fly and use server-side technology to generate webpages. They typically extract their content from one or more back-end databases: some are database queries across a relational database to query a catalogue or to summarise numeric information, others may use a document database such as MongoDB or NoSQL to store larger units of content, such as blog posts or wiki articles.
In the design process, dynamic pages are often mocked-up or wire-framed using static pages.
The skillset needed to develop dynamic web pages is much broader than for a static pages, involving server-side and database coding as well as client-side interface design. Even medium-sized dynamic projects are thus almost always a team effort.
When dynamic web pages first developed, they were typically coded directly in languages such as Perl, PHP or ASP. Some of these, notably PHP and ASP, used a 'template' approach where a server-side page resembled the structure of the completed client-side page and data was inserted into places defined by 'tags'. This was a quicker means of development than coding in a purely procedural coding language such as Perl.
Both of these approaches have now been supplanted for many websites by higher-level application-focused tools such as content management systems. These build on top of general purpose coding platforms and assume that a website exists to offer content according to one of several well recognized models, such as a time-sequenced blog, a thematic magazine or news site, a wiki or a user forum.
These tools make the implementation of such a site very easy, and a purely organisational and design-based task, without requiring any coding.
Editing the content itself (as well as the template page) can be done both by means of the site itself, and with the use of third-party software. The ability to edit all pages is provided only to a specific category of users (for example, administrators, or registered users). In some cases, anonymous users are allowed to edit certain web content, which is less frequent (for example, on forums - adding messages). An example of a site with an anonymous change is Wikipedia.
Homepage design:
Usability experts, including Jakob Nielsen and Kyle Soucy, have often emphasized homepage design for website success and asserted that the homepage is the most important page on a website.
However practitioners into the 2000s were starting to find that a growing number of website traffic was bypassing the homepage, going directly to internal content pages through search engines, e-newsletters and RSS feeds. Leading many practitioners to argue that homepages are less important than most people think. Jared Spool argued in 2007 that a site's homepage was actually the least important page on a website.
In 2012 and 2013, carousels (also called 'sliders' and 'rotating banners') have become an extremely popular design element on homepages, often used to showcase featured or recent content in a confined space. Many practitioners argue that carousels are an ineffective design element and hurt a website's search engine optimization and usability.
Occupations:
There are two primary jobs involved in creating a website: the web designer and web developer, who often work closely together on a website. The web designers are responsible for the visual aspect, which includes the layout, coloring and typography of a web page.
Web designers will also have a working knowledge of markup languages such as HTML and CSS, although the extent of their knowledge will differ from one web designer to another.
Particularly in smaller organizations one person will need the necessary skills for designing and programming the full web page, while larger organizations may have a web designer responsible for the visual aspect alone.
Further jobs which may become involved in the creation of a website include:
Click on any of the following blue hyperlinks for more about Web Design:
The different areas of web design include:
- web graphic design;
- interface design;
- authoring,
- including standardized code and proprietary software;
- user experience design;
- and search engine optimization.
Often many individuals will work in teams covering different aspects of the design process, although some designers will cover them all. The term web design is normally used to describe the design process relating to the front-end (client side) design of a website including writing mark up.
Web design partially overlaps web engineering in the broader scope of web development. Web designers are expected to have an awareness of usability and if their role involves creating mark up then they are also expected to be up to date with web accessibility guidelines.
Tools and Technologies:
Web designers use a variety of different tools depending on what part of the production process they are involved in. These tools are updated over time by newer standards and software but the principles behind them remain the same. Web designers use both vector and raster graphics editors to create web-formatted imagery or design prototypes.
Technologies used to create websites include W3C standards like HTML and CSS, which can be hand-coded or generated by WYSIWYG editing software. Other tools web designers might use include mark up validators and other testing tools for usability and accessibility to ensure their websites meet web accessibility guidelines.
Skills and techniques include:
Marketing and communication design
Marketing and communication design on a website may identify what works for its target market. This can be an age group or particular strand of culture; thus the designer may understand the trends of its audience.
Designers may also understand the type of website they are designing, meaning, for example, that (B2B) business-to-business website design considerations might differ greatly from a consumer targeted website such as a retail or entertainment website. Careful consideration might be made to ensure that the aesthetics or overall design of a site do not clash with the clarity and accuracy of the content or the ease of web navigation, especially on a B2B website.
Designers may also consider the reputation of the owner or business the site is representing to make sure they are portrayed favorably.
User experience design and interactive design
User understanding of the content of a website often depends on user understanding of how the website works. This is part of the user experience design.
User experience is related to layout, clear instructions and labeling on a website. How well a user understands how they can interact on a site may also depend on the interactive design of the site. If a user perceives the usefulness of the website, they are more likely to continue using it.
Users who are skilled and well versed with website use may find a more distinctive, yet less intuitive or less user-friendly website interface useful nonetheless. However, users with less experience are less likely to see the advantages or usefulness of a less intuitive website interface. This drives the trend for a more universal user experience and ease of access to accommodate as many users as possible regardless of user skill.
Much of the user experience design and interactive design are considered in the user interface design.
Advanced interactive functions may require plug-ins if not advanced coding language skills.
Choosing whether or not to use interactivity that requires plug-ins is a critical decision in user experience design. If the plug-in doesn't come pre-installed with most browsers, there's a risk that the user will have neither the know how or the patience to install a plug-in just to access the content. If the function requires advanced coding language skills, it may be too costly in either time or money to code compared to the amount of enhancement the function will add to the user experience.
There's also a risk that advanced interactivity may be incompatible with older browsers or hardware configurations. Publishing a function that doesn't work reliably is potentially worse for the user experience than making no attempt. It depends on the target audience if it's likely to be needed or worth any risks.
Page layout:
Part of the user interface design is affected by the quality of the page layout. For example, a designer may consider whether the site's page layout should remain consistent on different pages when designing the layout.
Page pixel width may also be considered vital for aligning objects in the layout design. The most popular fixed-width websites generally have the same set width to match the current most popular browser window, at the current most popular screen resolution, on the current most popular monitor size. Most pages are also center-aligned for concerns of aesthetics on larger screens.
Fluid layouts increased in popularity around 2000 as an alternative to HTML-table-based layouts and grid-based design in both page layout design principle and in coding technique, but were very slow to be adopted. This was due to considerations of screen reading devices and varying windows sizes which designers have no control over.
Accordingly, a design may be broken down into units (sidebars, content blocks, embedded advertising areas, navigation areas) that are sent to the browser and which will be fitted into the display window by the browser, as best it can.
As the browser does recognize the details of the reader's screen (window size, font size relative to window etc.) the browser can make user-specific layout adjustments to fluid layouts, but not fixed-width layouts. Although such a display may often change the relative position of major content units, sidebars may be displaced below body text rather than to the side of it.
This is a more flexible display than a hard-coded grid-based layout that doesn't fit the device window. In particular, the relative position of content blocks may change while leaving the content within the block unaffected. This also minimizes the user's need to horizontally scroll the page.
Responsive Web Design is a newer approach, based on CSS3, and a deeper level of per-device specification within the page's stylesheet through an enhanced use of the CSS @media rule.
In March 2018 Google announced they would be rolling out mobile-first indexing. Sites using responsive design are well placed to ensure they meet this new approach.
Typography:
Web designers may choose to limit the variety of website typefaces to only a few which are of a similar style, instead of using a wide range of typefaces or type styles. Most browsers recognize a specific number of safe fonts, which designers mainly use in order to avoid complications.
Font downloading was later included in the CSS3 fonts module and has since been implemented in Safari 3.1, Opera 10 and Mozilla Firefox 3.5. This has subsequently increased interest in web typography, as well as the usage of font downloading.
Most site layouts incorporate negative space to break the text up into paragraphs and also avoid center-aligned text.
Motion graphics
The page layout and user interface may also be affected by the use of motion graphics. The choice of whether or not to use motion graphics may depend on the target market for the website. Motion graphics may be expected or at least better received with an entertainment-oriented website.
However, a website target audience with a more serious or formal interest (such as business, community, or government) might find animations unnecessary and distracting if only for entertainment or decoration purposes. This doesn't mean that more serious content couldn't be enhanced with animated or video presentations that is relevant to the content. In either case, motion graphic design may make the difference between more effective visuals or distracting visuals.
Motion graphics that are not initiated by the site visitor can produce accessibility issues. The World Wide Web consortium accessibility standards require that site visitors be able to disable the animations.
Quality of code:
Website designers may consider it to be good practice to conform to standards. This is usually done via a description specifying what the element is doing. Failure to conform to standards may not make a website unusable or error prone, but standards can relate to the correct layout of pages for readability as well making sure coded elements are closed appropriately.
This includes errors in code, more organized layout for code, and making sure IDs and classes are identified properly. Poorly-coded pages are sometimes colloquially called tag soup.
Validating via W3C can only be done when a correct DOCTYPE declaration is made, which is used to highlight errors in code. The system identifies the errors and areas that do not conform to web design standards. This information can then be corrected by the user.
Generated content:
There are two ways websites are generated: statically or dynamically:
Static websites:
Main article: Static web page
A static website stores a unique file for every page of a static website. Each time that page is requested, the same content is returned. This content is created once, during the design of the website. It is usually manually authored, although some sites use an automated creation process, similar to a dynamic website, whose results are stored long-term as completed pages. These automatically-created static sites became more popular around 2015, with generators such as Jekyll and Adobe Muse.
The benefits of a static website are that they were simpler to host, as their server only needed to serve static content, not execute server-side scripts. This required less server administration and had less chance of exposing security holes. They could also serve pages more quickly, on low-cost server hardware. These advantage became less important as cheap web hosting expanded to also offer dynamic features, and virtual servers offered high performance for short intervals at low cost.
Almost all websites have some static content, as supporting assets such as images and stylesheets are usually static, even on a website with highly dynamic pages.
Dynamic websites:
Main article: Dynamic web page
Dynamic websites are generated on the fly and use server-side technology to generate webpages. They typically extract their content from one or more back-end databases: some are database queries across a relational database to query a catalogue or to summarise numeric information, others may use a document database such as MongoDB or NoSQL to store larger units of content, such as blog posts or wiki articles.
In the design process, dynamic pages are often mocked-up or wire-framed using static pages.
The skillset needed to develop dynamic web pages is much broader than for a static pages, involving server-side and database coding as well as client-side interface design. Even medium-sized dynamic projects are thus almost always a team effort.
When dynamic web pages first developed, they were typically coded directly in languages such as Perl, PHP or ASP. Some of these, notably PHP and ASP, used a 'template' approach where a server-side page resembled the structure of the completed client-side page and data was inserted into places defined by 'tags'. This was a quicker means of development than coding in a purely procedural coding language such as Perl.
Both of these approaches have now been supplanted for many websites by higher-level application-focused tools such as content management systems. These build on top of general purpose coding platforms and assume that a website exists to offer content according to one of several well recognized models, such as a time-sequenced blog, a thematic magazine or news site, a wiki or a user forum.
These tools make the implementation of such a site very easy, and a purely organisational and design-based task, without requiring any coding.
Editing the content itself (as well as the template page) can be done both by means of the site itself, and with the use of third-party software. The ability to edit all pages is provided only to a specific category of users (for example, administrators, or registered users). In some cases, anonymous users are allowed to edit certain web content, which is less frequent (for example, on forums - adding messages). An example of a site with an anonymous change is Wikipedia.
Homepage design:
Usability experts, including Jakob Nielsen and Kyle Soucy, have often emphasized homepage design for website success and asserted that the homepage is the most important page on a website.
However practitioners into the 2000s were starting to find that a growing number of website traffic was bypassing the homepage, going directly to internal content pages through search engines, e-newsletters and RSS feeds. Leading many practitioners to argue that homepages are less important than most people think. Jared Spool argued in 2007 that a site's homepage was actually the least important page on a website.
In 2012 and 2013, carousels (also called 'sliders' and 'rotating banners') have become an extremely popular design element on homepages, often used to showcase featured or recent content in a confined space. Many practitioners argue that carousels are an ineffective design element and hurt a website's search engine optimization and usability.
Occupations:
There are two primary jobs involved in creating a website: the web designer and web developer, who often work closely together on a website. The web designers are responsible for the visual aspect, which includes the layout, coloring and typography of a web page.
Web designers will also have a working knowledge of markup languages such as HTML and CSS, although the extent of their knowledge will differ from one web designer to another.
Particularly in smaller organizations one person will need the necessary skills for designing and programming the full web page, while larger organizations may have a web designer responsible for the visual aspect alone.
Further jobs which may become involved in the creation of a website include:
- Graphic designers to create visuals for the site such as logos, layouts and buttons
- Internet marketing specialists to help maintain web presence through strategic solutions on targeting viewers to the site, by using marketing and promotional techniques on the internet
- SEO writers to research and recommend the correct words to be incorporated into a particular website and make the website more accessible and found on numerous search engines
- Internet copywriter to create the written content of the page to appeal to the targeted viewers of the site
- User experience (UX) designer incorporates aspects of user focused design considerations which include information architecture, user centered design, user testing, interaction design, and occasionally visual design.
Click on any of the following blue hyperlinks for more about Web Design:
- History
- See also:
- Aesthetics
- Color theory
- Composition (visual arts)
- Cross-browser
- Design education
- Design principles and elements
- Drawing
- Dark pattern
- European Design Awards
- First Things First 2000 manifesto
- Graphic art software
- Graphic design occupations
- Graphics
- Information graphics
- List of graphic design institutions
- List of notable graphic designers
- Logotype
- Progressive Enhancement
- Style guide
- Web 2.0
- Web colors
- Web safe fonts
- Web usability
- Web application framework
- Website builder
- Website wireframe
- Related disciplines
- Communication design
- Copywriting
- Desktop publishing
- Digital illustration
- Graphic design
- Interaction design
- Information design
- Light-on-dark color scheme
- Marketing communications
- Motion graphic design
- New media
- Search engine optimization (SEO)
- Technical Writer
- Typography
- User experience
- User interface design
- Web development
- Web animations
- W3C consortium for web standards
- Web design and development at Curlie
Google Maps
- YouTube Video: How to use the new Google Maps: Directions
- YouTube Video: How Google Maps Works
- YouTube Video of the Top 10 tips for using Google Maps
Google Maps is a web mapping service developed by Google. It offers satellite imagery, street maps, 360° panoramic views of streets (Street View), real-time traffic conditions (Google Traffic), and route planning for traveling by foot, car, bicycle and air (in beta), or public transportation.
Google Maps began as a C++ desktop program at Where 2 Technologies. In October 2004, the company was acquired by Google, which converted it into a web application. After additional acquisitions of a geospatial data visualization company and a realtime traffic analyzer, Google Maps was launched in February 2005.
The service's front end utilizes JavaScript, XML, and Ajax. Google Maps offers an API that allows maps to be embedded on third-party websites, and offers a locator for urban businesses and other organizations in numerous countries around the world. Google Map Maker allowed users to collaboratively expand and update the service's mapping worldwide but was discontinued from March 2017.
However, crowdsourced contributions to Google Maps were not discontinued as the company announced those features will be transferred to the Google Local Guides program.
Google Maps' satellite view is a "top-down" or "birds eye" view; most of the high-resolution imagery of cities is aerial photography taken from aircraft flying at 800 to 1,500 feet (240 to 460 m), while most other imagery is from satellites.
Much of the available satellite imagery is no more than three years old and is updated on a regular basis. Google Maps used a variant of the Mercator projection, and therefore cannot accurately show areas around the poles. However, in August 2018, the desktop version of Google Maps was updated to show a 3D globe.
The current redesigned version of the desktop application was made available in 2013, alongside the "classic" (pre-2013) version. Google Maps for Android and iOS devices was released in September 2008 and features GPS turn-by-turn navigation along with dedicated parking assistance features.
In August 2013, it was determined to be the world's most popular app for smartphones, with over 54% of global smartphone owners using it at least once.
In 2012, Google reported having over 7,100 employees and contractors directly working in mapping.
Directions:
Google Maps provides a route planner, allowing users to find available directions through driving, public transportation, walking, or biking. Google has partnered globally with over 800 public transportation providers to adopt General Transit Feed Specification (GTFS), making the data available to 3rd parties.
Google Traffic offers traffic data in real-time, using a colored map overlay to display the speed of vehicles on particular roads. Crowdsourcing is used to obtain the GPS-determined locations of a large number of cellphone users, from which live traffic maps are produced.
Implementation:
As the user drags the map, the grid squares are downloaded from the server and inserted into the page. When a user searches for a business, the results are downloaded in the background for insertion into the side panel and map; the page is not reloaded.
Locations are drawn dynamically by positioning a red pin (composed of several partially transparent PNGs) on top of the map images. A hidden IFrame with form submission is used because it preserves browser history.
Like many other Google web applications, Google Maps uses JavaScript extensively. The site also uses JSON for data transfer rather than XML, for performance reasons.
These techniques both fall under the broad Ajax umbrella. The result is termed a slippy map and is implemented elsewhere in projects such as OpenLayers.
Users who are logged into a Google Account can save locations indefinitely so that they are overlaid on the map with various colored "pins" whenever they browse the application. These "Saved places" can be organised into user named lists and shared with other users. One default list "Starred places" also automatically creates a record in another google product, Google Bookmarks.
The related Google "My Maps" service allows users to save maps with a specific set of location overlays containing personalized notes, images and travel pathways. These "My Maps" overlays can be selectively chosen to display or not within the standard Google Maps system both on desktop and mobile devices.
In October 2011, Google announced MapsGL, a WebGL version of Maps with better renderings and smoother transitions.
The version of Google Street View for classic Google Maps requires Adobe Flash.
Google Indoor Maps uses JPG, .PNG, .PDF, .BMP, or .GIF, for floor plan.
Extensibility and customization:
As Google Maps is coded almost entirely in JavaScript and XML, some end users have reverse-engineered the tool and produced client-side scripts and server-side hooks which allowed a user or website to introduce expanded or customized features into the Google Maps interface.
Using the core engine and the map/satellite images hosted by Google, such tools can introduce custom location icons, location coordinates and metadata, and even custom map image sources into the Google Maps interface. The script-insertion tool Greasemonkey provides a large number of client-side scripts to customize Google Maps data.
Combinations with photo sharing websites, such as Flickr, are used to create "memory maps". Using copies of the Keyhole satellite photos, users have taken advantage of image annotation features to provide personal histories and information regarding particular points of the area.
Google Maps API:
After the success of reverse-engineered mashups such as chicagocrime.org and housingmaps.com, Google launched the Google Maps API in June 2005 to allow developers to integrate Google Maps into their websites. It was a free service that didn't require an API key until June 2018 (changes went into effect on July 16), when it was announced that an API key linked to a Google Cloud account with billing enabled would be required to access the API.
The API currently does not contain ads, but Google states in their terms of use that they reserve the right to display ads in the future.
By using the Google Maps API, it is possible to embed Google Maps into an external website, on to which site-specific data can be overlaid.
Although initially only a JavaScript API, the Maps API was expanded to include an API for Adobe Flash applications (but this has been deprecated), a service for retrieving static map images, and web services for performing geocoding, generating driving directions, and obtaining elevation profiles.
Over 1,000,000 web sites use the Google Maps API, making it the most heavily used web application development API.
The Google Maps API is free for commercial use, provided that the site on which it is being used is publicly accessible and does not charge for access, and is not generating more than 25,000 map accesses a day. Sites that do not meet these requirements can purchase the Google Maps API for Business.
The success of the Google Maps API has spawned a number of competing alternatives, including the HERE Maps API, Bing Maps Platform, Leaflet and OpenLayers via self-hosting. The Yahoo! Maps API is in the process of being shut down.
In September 2011, Google announced it would discontinue a number of its products, including Google Maps API for Flash.
Google Maps for Android and iOS devices:
Main article: Google Maps (app)
Google Maps is available as a mobile app for the Android and iOS mobile operating systems.
The Android app was first released in September 2008, though the GPS-localization feature had been in testing on cellphones since 2007.
Google Maps was Apple's solution for its mapping service on iOS until the release of iOS 6 in September 2012, at which point it was replaced by Apple Maps, with Google releasing its own Google Maps standalone app on the iOS platform the following December.
The Google Maps apps on Android and iOS have many features in common, including turn-by-turn navigation, street view, and public transit information.
Updates in June 2012 and May 2014 enabled functionality to let users save certain map regions for offline access, while updates in 2017 have included features to actively help U.S. users find available parking spots in cities, and to give Indian users a two-wheeler transportation mode for improved traffic accessibility.
Google Maps on iOS received significant praise after its standalone app release in December 2012, with critics highlighting its detailed information and design as positives.
However, the apps have received criticism over privacy concerns, particularly a location history tracking page that offers "step by step" location logging, with privacy advocates advising users to disable the feature, and that an April 2014 privacy policy change enabled Google to have a unified login throughout its iOS apps, helping it identify each user's interactions within each app.
Google Maps and Street View parameters:
In Google Maps, URL parameters are sometimes data-driven in their limits and the user interface presented by the web may or may not reflect those limits. In particular, the zoom level (denoted by the z parameter) supported varies. In less populated regions, the supported zoom levels might stop at around 18.
In earlier versions of the API, specifying these higher values might result in no image being displayed. In Western cities, the supported zoom level generally stops at about 20. In some isolated cases, the data supports up to 23 or greater, as in these elephants or this view of people at a well in Chad, Africa.
Different versions of the API and web interfaces may or may not fully support these higher levels.
As of October 2010, the Google map viewer updates its zoom bar to allow the user to zoom all the way when centered over areas that support higher zoom levels. A customized split view, with Map above and Street View below it (and its rotation) can be saved as parametrized URL link and shared by users.
Google's use of classic Google Maps:
Google Street View:
Main article: Google Street View
On May 25, 2007, Google released Google Street View, a new feature of Google Maps which provides 360° panoramic street-level views of various locations. On the date of release, the feature only included five cities in the US. It has since expanded to thousands of locations around the world. In July 2009, Google began mapping college campuses and surrounding paths and trails.
Street View garnered much controversy after its release because of privacy concerns about the uncensored nature of the panoramic photographs, although the views are only taken on public streets. Since then, Google has begun blurring faces and license plates through automated facial recognition.
In late 2014, Google launched Google Underwater Street View, including 2,300 kilometres (1,400 mi) of the Australian Great Barrier Reef in 3D. The images are taken by special cameras which turn 360 degrees and take shots every 3 seconds.
Google Latitude:
Main article: Google Latitude
Google Latitude was a feature from Google that lets users share their physical locations with other people. This service was based on Google Maps, specifically on mobile devices. There was an iGoogle widget for Desktops and Laptops as well.
Some concerns were expressed about the privacy issues raised by the use of the service. On August 9, 2013, this service was discontinued, and in March 22, 2017, Google incorporated the features from Latitude into the Google Maps app.
Indoor Google Maps:
In March 2011, indoor maps were added to Google Maps, giving users the ability to navigate themselves within buildings such as airports, museums, shopping malls, big-box stores, universities, transit stations, and other public spaces (including underground facilities).
Google encourages owners of public facilities to submit floor plans of their buildings in order to add them to the service. Map users can view different floors of a building or subway station by clicking on a level selector that is displayed near any structures which are mapped on multiple levels.
Google Local Guides:
Google Local Guides is a program launched by Google Maps to enable its users to contribute to Google Maps and provide them additional perks and benefits for the work. The program is partially a successor to Google Map Maker as features from the former program became integrated into the website and app.
The program consists of adding reviews, photos, basic information, videos and correcting information such as wheelchair accessibility.
Click on any of the following blue hyperlinks for more about Google Maps:
Google Maps began as a C++ desktop program at Where 2 Technologies. In October 2004, the company was acquired by Google, which converted it into a web application. After additional acquisitions of a geospatial data visualization company and a realtime traffic analyzer, Google Maps was launched in February 2005.
The service's front end utilizes JavaScript, XML, and Ajax. Google Maps offers an API that allows maps to be embedded on third-party websites, and offers a locator for urban businesses and other organizations in numerous countries around the world. Google Map Maker allowed users to collaboratively expand and update the service's mapping worldwide but was discontinued from March 2017.
However, crowdsourced contributions to Google Maps were not discontinued as the company announced those features will be transferred to the Google Local Guides program.
Google Maps' satellite view is a "top-down" or "birds eye" view; most of the high-resolution imagery of cities is aerial photography taken from aircraft flying at 800 to 1,500 feet (240 to 460 m), while most other imagery is from satellites.
Much of the available satellite imagery is no more than three years old and is updated on a regular basis. Google Maps used a variant of the Mercator projection, and therefore cannot accurately show areas around the poles. However, in August 2018, the desktop version of Google Maps was updated to show a 3D globe.
The current redesigned version of the desktop application was made available in 2013, alongside the "classic" (pre-2013) version. Google Maps for Android and iOS devices was released in September 2008 and features GPS turn-by-turn navigation along with dedicated parking assistance features.
In August 2013, it was determined to be the world's most popular app for smartphones, with over 54% of global smartphone owners using it at least once.
In 2012, Google reported having over 7,100 employees and contractors directly working in mapping.
Directions:
Google Maps provides a route planner, allowing users to find available directions through driving, public transportation, walking, or biking. Google has partnered globally with over 800 public transportation providers to adopt General Transit Feed Specification (GTFS), making the data available to 3rd parties.
Google Traffic offers traffic data in real-time, using a colored map overlay to display the speed of vehicles on particular roads. Crowdsourcing is used to obtain the GPS-determined locations of a large number of cellphone users, from which live traffic maps are produced.
Implementation:
As the user drags the map, the grid squares are downloaded from the server and inserted into the page. When a user searches for a business, the results are downloaded in the background for insertion into the side panel and map; the page is not reloaded.
Locations are drawn dynamically by positioning a red pin (composed of several partially transparent PNGs) on top of the map images. A hidden IFrame with form submission is used because it preserves browser history.
Like many other Google web applications, Google Maps uses JavaScript extensively. The site also uses JSON for data transfer rather than XML, for performance reasons.
These techniques both fall under the broad Ajax umbrella. The result is termed a slippy map and is implemented elsewhere in projects such as OpenLayers.
Users who are logged into a Google Account can save locations indefinitely so that they are overlaid on the map with various colored "pins" whenever they browse the application. These "Saved places" can be organised into user named lists and shared with other users. One default list "Starred places" also automatically creates a record in another google product, Google Bookmarks.
The related Google "My Maps" service allows users to save maps with a specific set of location overlays containing personalized notes, images and travel pathways. These "My Maps" overlays can be selectively chosen to display or not within the standard Google Maps system both on desktop and mobile devices.
In October 2011, Google announced MapsGL, a WebGL version of Maps with better renderings and smoother transitions.
The version of Google Street View for classic Google Maps requires Adobe Flash.
Google Indoor Maps uses JPG, .PNG, .PDF, .BMP, or .GIF, for floor plan.
Extensibility and customization:
As Google Maps is coded almost entirely in JavaScript and XML, some end users have reverse-engineered the tool and produced client-side scripts and server-side hooks which allowed a user or website to introduce expanded or customized features into the Google Maps interface.
Using the core engine and the map/satellite images hosted by Google, such tools can introduce custom location icons, location coordinates and metadata, and even custom map image sources into the Google Maps interface. The script-insertion tool Greasemonkey provides a large number of client-side scripts to customize Google Maps data.
Combinations with photo sharing websites, such as Flickr, are used to create "memory maps". Using copies of the Keyhole satellite photos, users have taken advantage of image annotation features to provide personal histories and information regarding particular points of the area.
Google Maps API:
After the success of reverse-engineered mashups such as chicagocrime.org and housingmaps.com, Google launched the Google Maps API in June 2005 to allow developers to integrate Google Maps into their websites. It was a free service that didn't require an API key until June 2018 (changes went into effect on July 16), when it was announced that an API key linked to a Google Cloud account with billing enabled would be required to access the API.
The API currently does not contain ads, but Google states in their terms of use that they reserve the right to display ads in the future.
By using the Google Maps API, it is possible to embed Google Maps into an external website, on to which site-specific data can be overlaid.
Although initially only a JavaScript API, the Maps API was expanded to include an API for Adobe Flash applications (but this has been deprecated), a service for retrieving static map images, and web services for performing geocoding, generating driving directions, and obtaining elevation profiles.
Over 1,000,000 web sites use the Google Maps API, making it the most heavily used web application development API.
The Google Maps API is free for commercial use, provided that the site on which it is being used is publicly accessible and does not charge for access, and is not generating more than 25,000 map accesses a day. Sites that do not meet these requirements can purchase the Google Maps API for Business.
The success of the Google Maps API has spawned a number of competing alternatives, including the HERE Maps API, Bing Maps Platform, Leaflet and OpenLayers via self-hosting. The Yahoo! Maps API is in the process of being shut down.
In September 2011, Google announced it would discontinue a number of its products, including Google Maps API for Flash.
Google Maps for Android and iOS devices:
Main article: Google Maps (app)
Google Maps is available as a mobile app for the Android and iOS mobile operating systems.
The Android app was first released in September 2008, though the GPS-localization feature had been in testing on cellphones since 2007.
Google Maps was Apple's solution for its mapping service on iOS until the release of iOS 6 in September 2012, at which point it was replaced by Apple Maps, with Google releasing its own Google Maps standalone app on the iOS platform the following December.
The Google Maps apps on Android and iOS have many features in common, including turn-by-turn navigation, street view, and public transit information.
Updates in June 2012 and May 2014 enabled functionality to let users save certain map regions for offline access, while updates in 2017 have included features to actively help U.S. users find available parking spots in cities, and to give Indian users a two-wheeler transportation mode for improved traffic accessibility.
Google Maps on iOS received significant praise after its standalone app release in December 2012, with critics highlighting its detailed information and design as positives.
However, the apps have received criticism over privacy concerns, particularly a location history tracking page that offers "step by step" location logging, with privacy advocates advising users to disable the feature, and that an April 2014 privacy policy change enabled Google to have a unified login throughout its iOS apps, helping it identify each user's interactions within each app.
Google Maps and Street View parameters:
In Google Maps, URL parameters are sometimes data-driven in their limits and the user interface presented by the web may or may not reflect those limits. In particular, the zoom level (denoted by the z parameter) supported varies. In less populated regions, the supported zoom levels might stop at around 18.
In earlier versions of the API, specifying these higher values might result in no image being displayed. In Western cities, the supported zoom level generally stops at about 20. In some isolated cases, the data supports up to 23 or greater, as in these elephants or this view of people at a well in Chad, Africa.
Different versions of the API and web interfaces may or may not fully support these higher levels.
As of October 2010, the Google map viewer updates its zoom bar to allow the user to zoom all the way when centered over areas that support higher zoom levels. A customized split view, with Map above and Street View below it (and its rotation) can be saved as parametrized URL link and shared by users.
Google's use of classic Google Maps:
Google Street View:
Main article: Google Street View
On May 25, 2007, Google released Google Street View, a new feature of Google Maps which provides 360° panoramic street-level views of various locations. On the date of release, the feature only included five cities in the US. It has since expanded to thousands of locations around the world. In July 2009, Google began mapping college campuses and surrounding paths and trails.
Street View garnered much controversy after its release because of privacy concerns about the uncensored nature of the panoramic photographs, although the views are only taken on public streets. Since then, Google has begun blurring faces and license plates through automated facial recognition.
In late 2014, Google launched Google Underwater Street View, including 2,300 kilometres (1,400 mi) of the Australian Great Barrier Reef in 3D. The images are taken by special cameras which turn 360 degrees and take shots every 3 seconds.
Google Latitude:
Main article: Google Latitude
Google Latitude was a feature from Google that lets users share their physical locations with other people. This service was based on Google Maps, specifically on mobile devices. There was an iGoogle widget for Desktops and Laptops as well.
Some concerns were expressed about the privacy issues raised by the use of the service. On August 9, 2013, this service was discontinued, and in March 22, 2017, Google incorporated the features from Latitude into the Google Maps app.
Indoor Google Maps:
In March 2011, indoor maps were added to Google Maps, giving users the ability to navigate themselves within buildings such as airports, museums, shopping malls, big-box stores, universities, transit stations, and other public spaces (including underground facilities).
Google encourages owners of public facilities to submit floor plans of their buildings in order to add them to the service. Map users can view different floors of a building or subway station by clicking on a level selector that is displayed near any structures which are mapped on multiple levels.
Google Local Guides:
Google Local Guides is a program launched by Google Maps to enable its users to contribute to Google Maps and provide them additional perks and benefits for the work. The program is partially a successor to Google Map Maker as features from the former program became integrated into the website and app.
The program consists of adding reviews, photos, basic information, videos and correcting information such as wheelchair accessibility.
Click on any of the following blue hyperlinks for more about Google Maps:
- History
- Maps of areas other than Earth
- Mashups
- Copyright
- Errors
- Potential misuse
- Comparable services
- See also:
- Google Maps
- Google Maps Development
- Google Maps for Work
- Google Maps parameters
- Bhuvan
- Comparison of web map services
- GeoGuessr
- Google Apps for Work
- Google Maps Road Trip (live-streaming documentary)
- Historypin
- Indoor positioning system
- MUSCULAR
- PlaceSpotting
- Wikiloc, a mashup that shows trails and waypoints on Google Maps
- WikiMapia, a mashup combining Google Maps and a wiki aimed at "describing the whole planet earth"
- Wikipediavision
Microblogging
YouTube Video: How to Pick the Best Blogging Platform in 2022
Pictured below: Is Microblogging Better?
YouTube Video: How to Pick the Best Blogging Platform in 2022
Pictured below: Is Microblogging Better?

Microblogging is an online broadcast medium that exists as a specific form of blogging. A microblog differs from a traditional blog in that its content is typically smaller in both actual and aggregated file size.
Microblogs "allow users to exchange small elements of content such as short sentences, individual images, or video links", which may be the major reason for their popularity. These small messages are sometimes called microposts.
As with traditional blogging, microbloggers post about topics ranging from the simple, such as "what I'm doing right now," to the thematic, such as "sports cars." Commercial microblogs also exist to promote websites, services and products, and to promote collaboration within an organization.
Some microblogging services offer features such as privacy settings, which allow users to control who can read their microblogs, or alternative ways of publishing entries besides the web-based interface. These may include text messaging, instant messaging, E-mail, digital audio or digital video.
Origin:
The first microblogs were known as tumblelogs. The term was coined by why the lucky stiff in a blog post on April 12, 2005, while describing Leah Neukirchen's Anarchaia.
“Blogging has mutated into simpler forms (specifically, link- and mob- and aud- and vid- variant), but I don’t think I’ve seen a blog like Chris Neukirchen’s [sic] Anarchaia, which fudges together a bunch of disparate forms of citation (links, quotes, flickrings) into a very long and narrow and distracted tumblelog.”Jason Kottke described tumblelogs on October 19, 2005:
“A tumblelog is a quick and dirty stream of consciousness, a bit like a remaindered links style linklog but with more than just links. They remind me of an older style of blogging, back when people did sites by hand, before Movable Type made post titles all but mandatory, blog entries turned into short magazine articles, and posts belonged to a conversation distributed throughout the entire blogosphere.
Robot Wisdom and Bifurcated Rivets are two older style weblogs that feel very much like these tumblelogs with minimal commentary, little cross-blog chatter, the barest whiff of a finished published work, almost pure editing...really just a way to quickly publish the "stuff" that you run across every day on the web”.
However, by 2006 and 2007, the term microblog was used more widely for services provided by established sites like Tumblr and Twitter. Twitter for one is especially popular in China, with over 35 million users tweeting in 2012, according to a survey by GlobalWebIndex.
As of May 2007, there were 111 microblogging sites in various countries.
Among the most notable services are Twitter, Tumblr, FriendFeed, Plurk, Jaiku and identi.ca. Different versions of services and software with microblogging features have been developed. Plurk has a timeline view that integrates video and picture sharing.
Flipter uses microblogging as a platform for people to post topics and gather audience's opinions.
PingGadget is a location-based microblogging service.
Pownce, developed by Digg founder Kevin Rose among others, integrated microblogging with file sharing and event invitations. Pownce was merged into SixApart in December 2008.
Other leading social networking websites Facebook, MySpace, LinkedIn, Diaspora*, JudgIt, Yahoo Pulse, Google Buzz, Google+ and XING, also have their own microblogging feature, better known as "status updates". Although status updates are usually more restricted than actual microblogging in terms of writing, it seems any kind of activity involving posting, be it on a social network site or a microblogging site, can be classified as microblogging.
Services such as Lifestream and SnapChat will aggregate microblogs from multiple social networks into a single list, while other services, such as Ping.fm, will send out your microblog to multiple social networks.
Internet users in China are facing a different situation. Foreign microblogging services like Twitter, Facebook, Plurk, and Google+ are censored in China. The users use Chinese weibo services such as Sina Weibo and Tencent Weibo. Tailored to Chinese people, these weibos are like hybrids of Twitter and Facebook. They implement basic features of Twitter and allow users to comment to others' posts, as well as post with graphical emoticons, attach an image, music and video files. A survey by the Data Center of China Internet from 2010 showed that Chinese microblog users most often pursued content created by friends, experts in a specific field or related to celebrities.
Usage:
Several studies, most notably by the Harvard Business School and by Sysomos, have tried to analyze user behaviour on microblogging services. Several of these studies show that for services such as Twitter a small group of active users contributes to most of the activity.
Sysomos' Inside Twitter survey, based on more than 11 million users, shows that 10% of Twitter users account for 86% of all activity.
Twitter, Facebook, and other microblogging services have become platforms for marketing and public relations, with a sharp growth in the number of social-media marketers.
The Sysomos study shows that this specific group of marketers on Twitter is much more active than the general user population, with 15% of marketers following over 2,000 people and only 0.29% of the Twitter public following more than 2,000 people.
Microblogging has also become an important source of real-time news updates during socio-political revolutions and crisis situations, such as the 2008 Mumbai terror attacks or the 2009 Iran protests.
The short nature of updates allow users to post news items quickly, reaching an audience in seconds. Clay Shirky argues that these services have the potential to result in an information cascade, prompting fence-sitters to turn activist.
Microblogging has noticeably revolutionized the way information is consumed. It has empowered citizens themselves to act as sensors or sources of information that could lead to consequences and influence, or even cause, media coverage. People share what they observe in their surroundings, information about events, and their opinions about topics from a wide range of fields.
Moreover, these services store various metadata from these posts, such as location and time. Aggregated analysis of this data includes different dimensions like space, time, theme, sentiment, network structure etc., and gives researchers an opportunity to understand social perceptions of people in the context of certain events of interest. Microblogging also promotes authorship. On the microblogging platform Tumblr, the reblogging feature links the post back to the original creator.
The findings of a study by Emily Pronin of Princeton University and Harvard University's Daniel Wegner may explain the rapid growth of microblogging. The study suggests a link between short bursts of activity and feelings of elation, power and creativity.
While the general appeal and influence of microblogging seem to be growing continuously, mobile microblogging is moving at a slower pace. Among the most popular activities carried out by mobile internet users on their devices in 2012, mobile blogging or tweeting was last on the list, with only 27% of users engaging in it.
Organizational usage:
Users and organizations often set up their own microblogging service – free and open source software is available for this purpose. Hosted microblogging platforms are also available for commercial and organizational use.
Considering the smaller amount of time and effort to make a post this way or share an update, microblogging has the potential to become a new, informal communication medium, especially for collaborative work within organizations.
Over the last few years communication patterns have shifted primarily from face-to-face to online in email, IM, text messaging, and other tools.
However, some argue that email is now a slow and inefficient way to communicate. For instance, time-consuming "email chains" can develop, whereby two or more people are involved in lengthy communications for simple matters, such as arranging a meeting. The one-to-many broadcasting offered by microblogs is thought to increase productivity by circumventing this.
Another implication of remote collaboration is that there are fewer opportunities for face-to-face informal conversations. Workplace schedules in particular have become much busier and allow little room for real socializing or exchange.
However, microblogging has the potential to support informal communication among coworkers and help it grow when people actually do meet afterwards. Many individuals like sharing their whereabouts and status updates through microblogging.
Microblogging is therefore expected to improve the social and emotional welfare of the workforce, as well as streamline the information flow within an organization. It can increase opportunities to share information, help realize and utilize expertise within the workforce, and help build and maintain common ground between coworkers. As microblogging use continues to grow every year, it is quickly becoming a core component of Enterprise Social Software.
Dr. Gregory D. Saxton and Kristen Lovejoy at the University at Buffalo, SUNY have done a study on how nonprofit organizations use microblogging to meet their company needs and missions, with an emphasis on Twitter use. Their sample included 100 nonprofit organizations, 73 of which had Twitter accounts, and 59 that were considered “active,” or sent out a tweet at least three times a week. In a one-month time period 4,655 tweets were collected for analysis from these organizations.
They developed three categories with a total of 12 sub categories in which to place tweets based on their functions, and classify organizations based on the purpose of the majority of their tweets. The three head categories include information, community, and action. Information includes one-way interactions that inform the public of the organization's activities, events, and news.
The community head category can also be broken down into two sub categories of community building and dialogue intended tweets. Community building tweets are meant to strengthen ties and create an online community, such as tweets giving thanks or showing acknowledgement of current events.
Tweets meant to create dialogue are often interactive responses to other Twitter users or tweets invoking a response from users. Action tweets are used to promote events, ask people for donations, selling products, asking for volunteers, lobbying, or requests to join another cite.
Through their analysis, Saxton and Lovejoy were able to identify nonprofit organizations’ main purpose in using the microblogging site, Twitter, and break down organizations into three categories based on purpose of tweets: 1. “Information Sources,” 2. “Community Builders,” and 3. “Promoters & Mobilizers.” In their discussion of the study, they stated that they believe their findings are generalizable to other microblogging and social media sites.
Issues:
Microblogging is not without issues, such as privacy, security, and integration.
Privacy is arguably a major issue because users may broadcast sensitive personal information to anyone who views their public feed. Microblog platform providers can also cause privacy issues through altering or presetting users' privacy options in a way users feel compromises their personal information.
An example would be Google’s Buzz platform which incited controversy in 2010 by automatically publicizing users’ email contacts as ‘followers’. Google later amended these settings.
On centralized services, where all of the Microblog's information flows through one point (e.g. servers operated by Twitter), privacy has been a concern in that user information has sometimes been exposed to governments and courts without the prior consent of the user who generated such supposedly private information, usually through subpoenas or court orders.
Examples can be found in Wikileaks related Twitter subpoenas, as well as various other cases.
Security concerns have been voiced within the business world, since there is potential for sensitive work information to be publicized on microblogging sites such as Twitter. This includes information which may be subject to a super-injunction.
Integration could be the hardest issue to overcome, since it can be argued that corporate culture must change to accommodate microblogging.
Related Concepts:
Live blogging is a derivative of microblogging that generates a continuous feed on a specific web page.
Instant messaging and IRC display status, but generally only one of a few choices, such as: available, off-line, away, busy. Away messages (messages displayed when the user is away) form a kind of microblogging.
In the Finger protocol, the .project and .plan files are sometimes used for status updates similar to microblogging.
See also:
Microblogs "allow users to exchange small elements of content such as short sentences, individual images, or video links", which may be the major reason for their popularity. These small messages are sometimes called microposts.
As with traditional blogging, microbloggers post about topics ranging from the simple, such as "what I'm doing right now," to the thematic, such as "sports cars." Commercial microblogs also exist to promote websites, services and products, and to promote collaboration within an organization.
Some microblogging services offer features such as privacy settings, which allow users to control who can read their microblogs, or alternative ways of publishing entries besides the web-based interface. These may include text messaging, instant messaging, E-mail, digital audio or digital video.
Origin:
The first microblogs were known as tumblelogs. The term was coined by why the lucky stiff in a blog post on April 12, 2005, while describing Leah Neukirchen's Anarchaia.
“Blogging has mutated into simpler forms (specifically, link- and mob- and aud- and vid- variant), but I don’t think I’ve seen a blog like Chris Neukirchen’s [sic] Anarchaia, which fudges together a bunch of disparate forms of citation (links, quotes, flickrings) into a very long and narrow and distracted tumblelog.”Jason Kottke described tumblelogs on October 19, 2005:
“A tumblelog is a quick and dirty stream of consciousness, a bit like a remaindered links style linklog but with more than just links. They remind me of an older style of blogging, back when people did sites by hand, before Movable Type made post titles all but mandatory, blog entries turned into short magazine articles, and posts belonged to a conversation distributed throughout the entire blogosphere.
Robot Wisdom and Bifurcated Rivets are two older style weblogs that feel very much like these tumblelogs with minimal commentary, little cross-blog chatter, the barest whiff of a finished published work, almost pure editing...really just a way to quickly publish the "stuff" that you run across every day on the web”.
However, by 2006 and 2007, the term microblog was used more widely for services provided by established sites like Tumblr and Twitter. Twitter for one is especially popular in China, with over 35 million users tweeting in 2012, according to a survey by GlobalWebIndex.
As of May 2007, there were 111 microblogging sites in various countries.
Among the most notable services are Twitter, Tumblr, FriendFeed, Plurk, Jaiku and identi.ca. Different versions of services and software with microblogging features have been developed. Plurk has a timeline view that integrates video and picture sharing.
Flipter uses microblogging as a platform for people to post topics and gather audience's opinions.
PingGadget is a location-based microblogging service.
Pownce, developed by Digg founder Kevin Rose among others, integrated microblogging with file sharing and event invitations. Pownce was merged into SixApart in December 2008.
Other leading social networking websites Facebook, MySpace, LinkedIn, Diaspora*, JudgIt, Yahoo Pulse, Google Buzz, Google+ and XING, also have their own microblogging feature, better known as "status updates". Although status updates are usually more restricted than actual microblogging in terms of writing, it seems any kind of activity involving posting, be it on a social network site or a microblogging site, can be classified as microblogging.
Services such as Lifestream and SnapChat will aggregate microblogs from multiple social networks into a single list, while other services, such as Ping.fm, will send out your microblog to multiple social networks.
Internet users in China are facing a different situation. Foreign microblogging services like Twitter, Facebook, Plurk, and Google+ are censored in China. The users use Chinese weibo services such as Sina Weibo and Tencent Weibo. Tailored to Chinese people, these weibos are like hybrids of Twitter and Facebook. They implement basic features of Twitter and allow users to comment to others' posts, as well as post with graphical emoticons, attach an image, music and video files. A survey by the Data Center of China Internet from 2010 showed that Chinese microblog users most often pursued content created by friends, experts in a specific field or related to celebrities.
Usage:
Several studies, most notably by the Harvard Business School and by Sysomos, have tried to analyze user behaviour on microblogging services. Several of these studies show that for services such as Twitter a small group of active users contributes to most of the activity.
Sysomos' Inside Twitter survey, based on more than 11 million users, shows that 10% of Twitter users account for 86% of all activity.
Twitter, Facebook, and other microblogging services have become platforms for marketing and public relations, with a sharp growth in the number of social-media marketers.
The Sysomos study shows that this specific group of marketers on Twitter is much more active than the general user population, with 15% of marketers following over 2,000 people and only 0.29% of the Twitter public following more than 2,000 people.
Microblogging has also become an important source of real-time news updates during socio-political revolutions and crisis situations, such as the 2008 Mumbai terror attacks or the 2009 Iran protests.
The short nature of updates allow users to post news items quickly, reaching an audience in seconds. Clay Shirky argues that these services have the potential to result in an information cascade, prompting fence-sitters to turn activist.
Microblogging has noticeably revolutionized the way information is consumed. It has empowered citizens themselves to act as sensors or sources of information that could lead to consequences and influence, or even cause, media coverage. People share what they observe in their surroundings, information about events, and their opinions about topics from a wide range of fields.
Moreover, these services store various metadata from these posts, such as location and time. Aggregated analysis of this data includes different dimensions like space, time, theme, sentiment, network structure etc., and gives researchers an opportunity to understand social perceptions of people in the context of certain events of interest. Microblogging also promotes authorship. On the microblogging platform Tumblr, the reblogging feature links the post back to the original creator.
The findings of a study by Emily Pronin of Princeton University and Harvard University's Daniel Wegner may explain the rapid growth of microblogging. The study suggests a link between short bursts of activity and feelings of elation, power and creativity.
While the general appeal and influence of microblogging seem to be growing continuously, mobile microblogging is moving at a slower pace. Among the most popular activities carried out by mobile internet users on their devices in 2012, mobile blogging or tweeting was last on the list, with only 27% of users engaging in it.
Organizational usage:
Users and organizations often set up their own microblogging service – free and open source software is available for this purpose. Hosted microblogging platforms are also available for commercial and organizational use.
Considering the smaller amount of time and effort to make a post this way or share an update, microblogging has the potential to become a new, informal communication medium, especially for collaborative work within organizations.
Over the last few years communication patterns have shifted primarily from face-to-face to online in email, IM, text messaging, and other tools.
However, some argue that email is now a slow and inefficient way to communicate. For instance, time-consuming "email chains" can develop, whereby two or more people are involved in lengthy communications for simple matters, such as arranging a meeting. The one-to-many broadcasting offered by microblogs is thought to increase productivity by circumventing this.
Another implication of remote collaboration is that there are fewer opportunities for face-to-face informal conversations. Workplace schedules in particular have become much busier and allow little room for real socializing or exchange.
However, microblogging has the potential to support informal communication among coworkers and help it grow when people actually do meet afterwards. Many individuals like sharing their whereabouts and status updates through microblogging.
Microblogging is therefore expected to improve the social and emotional welfare of the workforce, as well as streamline the information flow within an organization. It can increase opportunities to share information, help realize and utilize expertise within the workforce, and help build and maintain common ground between coworkers. As microblogging use continues to grow every year, it is quickly becoming a core component of Enterprise Social Software.
Dr. Gregory D. Saxton and Kristen Lovejoy at the University at Buffalo, SUNY have done a study on how nonprofit organizations use microblogging to meet their company needs and missions, with an emphasis on Twitter use. Their sample included 100 nonprofit organizations, 73 of which had Twitter accounts, and 59 that were considered “active,” or sent out a tweet at least three times a week. In a one-month time period 4,655 tweets were collected for analysis from these organizations.
They developed three categories with a total of 12 sub categories in which to place tweets based on their functions, and classify organizations based on the purpose of the majority of their tweets. The three head categories include information, community, and action. Information includes one-way interactions that inform the public of the organization's activities, events, and news.
The community head category can also be broken down into two sub categories of community building and dialogue intended tweets. Community building tweets are meant to strengthen ties and create an online community, such as tweets giving thanks or showing acknowledgement of current events.
Tweets meant to create dialogue are often interactive responses to other Twitter users or tweets invoking a response from users. Action tweets are used to promote events, ask people for donations, selling products, asking for volunteers, lobbying, or requests to join another cite.
Through their analysis, Saxton and Lovejoy were able to identify nonprofit organizations’ main purpose in using the microblogging site, Twitter, and break down organizations into three categories based on purpose of tweets: 1. “Information Sources,” 2. “Community Builders,” and 3. “Promoters & Mobilizers.” In their discussion of the study, they stated that they believe their findings are generalizable to other microblogging and social media sites.
Issues:
Microblogging is not without issues, such as privacy, security, and integration.
Privacy is arguably a major issue because users may broadcast sensitive personal information to anyone who views their public feed. Microblog platform providers can also cause privacy issues through altering or presetting users' privacy options in a way users feel compromises their personal information.
An example would be Google’s Buzz platform which incited controversy in 2010 by automatically publicizing users’ email contacts as ‘followers’. Google later amended these settings.
On centralized services, where all of the Microblog's information flows through one point (e.g. servers operated by Twitter), privacy has been a concern in that user information has sometimes been exposed to governments and courts without the prior consent of the user who generated such supposedly private information, usually through subpoenas or court orders.
Examples can be found in Wikileaks related Twitter subpoenas, as well as various other cases.
Security concerns have been voiced within the business world, since there is potential for sensitive work information to be publicized on microblogging sites such as Twitter. This includes information which may be subject to a super-injunction.
Integration could be the hardest issue to overcome, since it can be argued that corporate culture must change to accommodate microblogging.
Related Concepts:
Live blogging is a derivative of microblogging that generates a continuous feed on a specific web page.
Instant messaging and IRC display status, but generally only one of a few choices, such as: available, off-line, away, busy. Away messages (messages displayed when the user is away) form a kind of microblogging.
In the Finger protocol, the .project and .plan files are sometimes used for status updates similar to microblogging.
See also:
- Microblogging portal
- Articles:
- Platforms:
- Services:
ISP Bandwidth Throttling including its negative impact on fighting 2018 California Wildfires
YouTube Video: Verizon THROTTLED Cell Data For First Responders Fighting WILDFIRES
Pictured below: Is your ISP secretly throttling your internet speed? Here’s how to find out
YouTube Video: Verizon THROTTLED Cell Data For First Responders Fighting WILDFIRES
Pictured below: Is your ISP secretly throttling your internet speed? Here’s how to find out
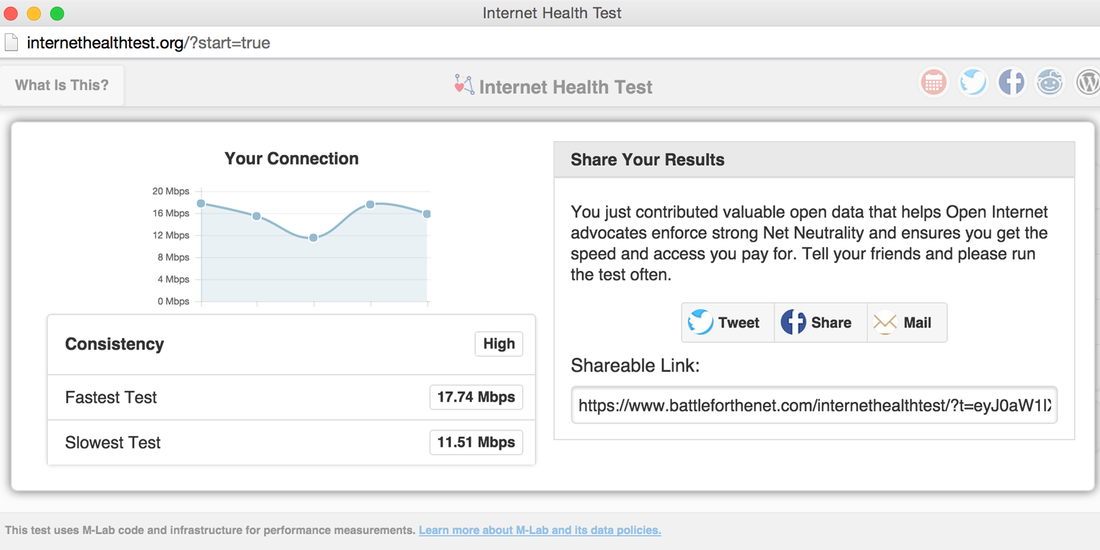
Verizon Throttled California Firefighters’ Internet Speeds Amid Blaze (They Were Out of Data)" (New York Times, 8/22/18)
"As the largest fire on record in California continued to carve
its destructive path through the northern part of the state, firefighters sent a mobile command center to the scene. With thousands of personnel, multiple aircraft and hundreds of fire engines battling the blaze, officials needed the “incident support unit” to help them track and organize all those resources.
But in the midst of the response efforts, fire officials discovered a problem: The data connection for their support unit had been slowed to about one two-hundredth of the speed it had previously enjoyed. Like a teenager who streamed too many YouTube videos and pushed his family’s usage above the limits of its data plan, the Santa Clara County Central Fire Protection District was being throttled by its internet service provider, Verizon. But in this case, officials have emphasized, homes and even lives were at stake.
The county fire district had no choice but to to use other agencies’ internet, rely on personal devices to transfer data and ultimately subscribe to a new, more expensive data plan, as Verizon officials urged them to do, according to court documents filed this week.
“In light of our experience, County Fire believes it is likely that Verizon will continue to use the exigent nature of public safety emergencies and catastrophic events to coerce public agencies into higher-cost plans ultimately paying significantly more for mission critical service — even if that means risking harm to public safety during negotiations,” Chief Anthony Bowden said in a sworn declaration.
Bandwidth throttling is the intentional slowing or speeding of an internet service by an Internet service provider (ISP). It is a reactive measure employed in communication networks to regulate network traffic and minimize bandwidth congestion. Bandwidth throttling can occur at different locations on the network. On a local area network (LAN), a system administrator ("sysadmin") may employ bandwidth throttling to help limit network congestion and server crashes.
On a broader level, the Internet service provider may use bandwidth throttling to help reduce a user's usage of bandwidth that is supplied to the local network. Bandwidth throttling is also used to speed up the Internet on speed test websites.
Throttling can be used to actively limit a user's upload and download rates on programs such as video streaming, BitTorrent protocols and other file sharing applications, as well as even out the usage of the total bandwidth supplied across all users on the network.
Bandwidth throttling is also often used in Internet applications, in order to spread a load over a wider network to reduce local network congestion, or over a number of servers to avoid overloading individual ones, and so reduce their risk of the system crashing, and gain additional revenue by giving users an incentive to use more expensive tiered pricing schemes, where bandwidth is not throttled.
Click on any of the following blue hyperlinks for more about Bandwidth Throttling:
"As the largest fire on record in California continued to carve
its destructive path through the northern part of the state, firefighters sent a mobile command center to the scene. With thousands of personnel, multiple aircraft and hundreds of fire engines battling the blaze, officials needed the “incident support unit” to help them track and organize all those resources.
But in the midst of the response efforts, fire officials discovered a problem: The data connection for their support unit had been slowed to about one two-hundredth of the speed it had previously enjoyed. Like a teenager who streamed too many YouTube videos and pushed his family’s usage above the limits of its data plan, the Santa Clara County Central Fire Protection District was being throttled by its internet service provider, Verizon. But in this case, officials have emphasized, homes and even lives were at stake.
The county fire district had no choice but to to use other agencies’ internet, rely on personal devices to transfer data and ultimately subscribe to a new, more expensive data plan, as Verizon officials urged them to do, according to court documents filed this week.
“In light of our experience, County Fire believes it is likely that Verizon will continue to use the exigent nature of public safety emergencies and catastrophic events to coerce public agencies into higher-cost plans ultimately paying significantly more for mission critical service — even if that means risking harm to public safety during negotiations,” Chief Anthony Bowden said in a sworn declaration.
Bandwidth throttling is the intentional slowing or speeding of an internet service by an Internet service provider (ISP). It is a reactive measure employed in communication networks to regulate network traffic and minimize bandwidth congestion. Bandwidth throttling can occur at different locations on the network. On a local area network (LAN), a system administrator ("sysadmin") may employ bandwidth throttling to help limit network congestion and server crashes.
On a broader level, the Internet service provider may use bandwidth throttling to help reduce a user's usage of bandwidth that is supplied to the local network. Bandwidth throttling is also used to speed up the Internet on speed test websites.
Throttling can be used to actively limit a user's upload and download rates on programs such as video streaming, BitTorrent protocols and other file sharing applications, as well as even out the usage of the total bandwidth supplied across all users on the network.
Bandwidth throttling is also often used in Internet applications, in order to spread a load over a wider network to reduce local network congestion, or over a number of servers to avoid overloading individual ones, and so reduce their risk of the system crashing, and gain additional revenue by giving users an incentive to use more expensive tiered pricing schemes, where bandwidth is not throttled.
Click on any of the following blue hyperlinks for more about Bandwidth Throttling:
- Operation
- Application
- Network neutrality
- Throttling vs. capping
- Court cases
- ISP bandwidth throttling
- Metrics for ISPs
- User responses
- See also:
Top Level Internet Domains, including a List of Top Level Domains
- YouTube Video: What is a Top Level Domain (TLD)?
- YouTube Video: ICANN New gTLDs (new generic Top Level Domains)
Click here for a List of Internet top-level domains.
A top-level domain (TLD) is one of the domains at the highest level in the hierarchical Domain Name System of the Internet.
The top-level domain names are installed in the root zone of the name space. For all domains in lower levels, it is the last part of the domain name, that is, the last label of a fully qualified domain name.
For example, in the domain name www.example.com, the top-level domain is com.
Responsibility for management of most top-level domains is delegated to specific organizations by the Internet Corporation for Assigned Names and Numbers (ICANN), which operates the Internet Assigned Numbers Authority (IANA), and is in charge of maintaining the DNS root zone.
IANA currently distinguishes the following groups of top-level domains:
Click on any of the following blue hyperlinks for more about Top-level Domain Names:
A top-level domain (TLD) is one of the domains at the highest level in the hierarchical Domain Name System of the Internet.
The top-level domain names are installed in the root zone of the name space. For all domains in lower levels, it is the last part of the domain name, that is, the last label of a fully qualified domain name.
For example, in the domain name www.example.com, the top-level domain is com.
Responsibility for management of most top-level domains is delegated to specific organizations by the Internet Corporation for Assigned Names and Numbers (ICANN), which operates the Internet Assigned Numbers Authority (IANA), and is in charge of maintaining the DNS root zone.
IANA currently distinguishes the following groups of top-level domains:
- country-code top-level domains (ccTLD)
Click on any of the following blue hyperlinks for more about Top-level Domain Names:
- History
- Types
- Internationalized country code TLDs
- Infrastructure domain
- Reserved domains
- Historical domains
- Proposed domains
- Alternative DNS roots
- Pseudo-domains
- See also:
Wireless Networks
- YouTube Video: Understanding Different Wireless Technologies
- YouTube Video: Wired vs. WiFi Connections. The differences explained.
A wireless network is a computer network that uses wireless data connections between network nodes.
Wireless networking is a method by which homes, telecommunications networks and business installations avoid the costly process of introducing cables into a building, or as a connection between various equipment locations.
Wireless telecommunications networks are generally implemented and administered using radio communication. This implementation takes place at the physical level (layer) of the OSI model network structure.
Examples of wireless networks include:
The first professional wireless network was developed under the brand ALOHAnet in 1969 at the University of Hawaii and became operational in June 1971. The first commercial wireless network was the WaveLAN product family, developed by NCR in 1986.
Wireless Links:
Types of wireless networks:
Wireless PAN:
Wireless personal area networks (WPANs) connect devices within a relatively small area, that is generally within a person's reach. For example, both Bluetooth radio and invisible infrared light provides a WPAN for interconnecting a headset to a laptop.
ZigBee also supports WPAN applications.
Wi-Fi PANs are becoming commonplace (2010) as equipment designers start to integrate Wi-Fi into a variety of consumer electronic devices. Intel "My WiFi" and Windows 7 "virtual Wi-Fi" capabilities have made Wi-Fi PANs simpler and easier to set up and configure.
Wireless LAN:
A wireless local area network (WLAN) links two or more devices over a short distance using a wireless distribution method, usually providing a connection through an access point for internet access. The use of spread-spectrum or OFDM technologies may allow users to move around within a local coverage area, and still remain connected to the network.
Products using the IEEE 802.11 WLAN standards are marketed under the Wi-Fi brand name.
Fixed wireless technology implements point-to-point links between computers or networks at two distant locations, often using dedicated microwave or modulated laser light beams over line of sight paths. It is often used in cities to connect networks in two or more buildings without installing a wired link. To connect to Wi-Fi, sometimes are used devices like a router or connecting HotSpot using mobile smartphones.
Wireless ad hoc network:
A wireless ad hoc network, also known as a wireless mesh network or mobile ad hoc network (MANET), is a wireless network made up of radio nodes organized in a mesh topology.
Each node forwards messages on behalf of the other nodes and each node performs routing. Ad hoc networks can "self-heal", automatically re-routing around a node that has lost power.
Various network layer protocols are needed to realize ad hoc mobile networks, including:
Wireless MAN:
Wireless metropolitan area networks are a type of wireless network that connects several wireless LANs.
WiMAX is a type of Wireless MAN and is described by the IEEE 802.16 standard.
Wireless WAN:
Wireless wide area networks are wireless networks that typically cover large areas, such as between neighboring towns and cities, or city and suburb. These networks can be used to connect branch offices of business or as a public Internet access system.
The wireless connections between access points are usually point to point microwave links using parabolic dishes on the 2.4 GHz and 5.8Ghz band, rather than omnidirectional antennas used with smaller networks. A typical system contains base station gateways, access points and wireless bridging relays.
Other configurations are mesh systems where each access point acts as a relay also. When combined with renewable energy systems such as photovoltaic solar panels or wind systems they can be stand alone systems.
Cellular network:
Main article: cellular network
A cellular network or mobile network is a radio network distributed over land areas called cells, each served by at least one fixed-location transceiver, known as a cell site or base station.
In a cellular network, each cell characteristically uses a different set of radio frequencies from all their immediate neighbouring cells to avoid any interference.
When joined together these cells provide radio coverage over a wide geographic area. This enables a large number of portable transceivers (e.g., mobile phones, pagers, etc.) to communicate with each other and with fixed transceivers and telephones anywhere in the network, via base stations, even if some of the transceivers are moving through more than one cell during transmission.
Although originally intended for cell phones, with the development of smartphones, cellular telephone networks routinely carry data in addition to telephone conversations:
Global area network:
A global area network (GAN) is a network used for supporting mobile across an arbitrary number of wireless LANs, satellite coverage areas, etc.
The key challenge in mobile communications is handing off user communications from one local coverage area to the next. In IEEE Project 802, this involves a succession of terrestrial wireless LANs.
Space network:
Space networks are networks used for communication between spacecraft, usually in the vicinity of the Earth. The example of this is NASA's Space Network.
Different Uses:
Some examples of usage include cellular phones which are part of everyday wireless networks, allowing easy personal communications. Another example, Intercontinental network systems, use radio satellites to communicate across the world.
Emergency services such as the police utilize wireless networks to communicate effectively as well. Individuals and businesses use wireless networks to send and share data rapidly, whether it be in a small office building or across the world.
Properties:
General:
In a general sense, wireless networks offer a vast variety of uses by both business and home users.
Now, the industry accepts a handful of different wireless technologies. Each wireless technology is defined by a standard that describes unique functions at both the Physical and the Data Link layers of the OSI model. These standards differ in their specified signaling methods, geographic ranges, and frequency usages, among other things.
Such differences can make certain technologies better suited to home networks and others better suited to network larger organizations.
Performance:
Each standard varies in geographical range, thus making one standard more ideal than the next depending on what it is one is trying to accomplish with a wireless network.
The performance of wireless networks satisfies a variety of applications such as voice and video. The use of this technology also gives room for expansions, such as from 2G to 3G and, 4G and 5G technologies, which stand for the fourth and fifth generation of cell phone mobile communications standards.
As wireless networking has become commonplace, sophistication increases through configuration of network hardware and software, and greater capacity to send and receive larger amounts of data, faster, is achieved. Now the wireless network has been running on LTE, which is a 4G mobile communication standard. Users of an LTE network should have data speeds that are 10x faster than a 3G network.
Space:
Space is another characteristic of wireless networking. Wireless networks offer many advantages when it comes to difficult-to-wire areas trying to communicate such as across a street or river, a warehouse on the other side of the premises or buildings that are physically separated but operate as one.
Wireless networks allow for users to designate a certain space which the network will be able to communicate with other devices through that network.
Space is also created in homes as a result of eliminating clutters of wiring. This technology allows for an alternative to installing physical network mediums such as TPs, coaxes, or fiber-optics, which can also be expensive.
Home:
For homeowners, wireless technology is an effective option compared to Ethernet for sharing printers, scanners, and high-speed Internet connections. WLANs help save the cost of installation of cable mediums, save time from physical installation, and also creates mobility for devices connected to the network. Wireless networks are simple and require as few as one single wireless access point connected directly to the Internet via a router.
Wireless Network Elements:
The telecommunications network at the physical layer also consists of many interconnected wireline network elements (NEs). These NEs can be stand-alone systems or products that are either supplied by a single manufacturer or are assembled by the service provider (user) or system integrator with parts from several different manufacturers.
Wireless NEs are the products and devices used by a wireless carrier to provide support for the backhaul network as well as a mobile switching center (MSC).
Reliable wireless service depends on the network elements at the physical layer to be protected against all operational environments and applications (see GR-3171, Generic Requirements for Network Elements Used in Wireless Networks – Physical Layer Criteria).
What are especially important are the NEs that are located on the cell tower to the base station (BS) cabinet. The attachment hardware and the positioning of the antenna and associated closures and cables are required to have adequate strength, robustness, corrosion resistance, and resistance against wind, storms, icing, and other weather conditions.
Requirements for individual components, such as hardware, cables, connectors, and closures, shall take into consideration the structure to which they are attached.
Difficulties:
Interference:
Compared to wired systems, wireless networks are frequently subject to electromagnetic interference. This can be caused by other networks or other types of equipment that generate radio waves that are within, or close, to the radio bands used for communication. Interference can degrade the signal or cause the system to fail.
Absorption and reflection:
Some materials cause absorption of electromagnetic waves, preventing it from reaching the receiver, in other cases, particularly with metallic or conductive materials reflection occurs.
This can cause dead zones where no reception is available. Aluminium foiled thermal isolation in modern homes can easily reduce indoor mobile signals by 10 dB frequently leading to complaints about the bad reception of long-distance rural cell signals.
Multipath fading:
In multipath fading two or more different routes taken by the signal, due to reflections, can cause the signal to cancel out at certain locations, and to be stronger in other places (upfade).
Hidden node problem:
The hidden node problem occurs in some types of network when a node is visible from a wireless access point (AP), but not from other nodes communicating with that AP. This leads to difficulties in media access control (collisions).
Exposed terminal node problem:
The exposed terminal problem is when a node on one network is unable to send because of interference from a node that is on a different network.
Shared resource problem:The wireless spectrum is a limited resource and shared by all nodes in the range of its transmitters.
Bandwidth allocation becomes complex with multiple participating users. Often users are not aware that advertised numbers (e.g., for IEEE 802.11 equipment or LTE networks) are not their capacity, but shared with all other users and thus the individual user rate is far lower.
With increasing demand, the capacity crunch is more and more likely to happen. User-in-the-loop (UIL) may be an alternative solution to ever upgrading to newer technologies for over-provisioning.
Capacity:
Channel:
Main article: Channel capacity in wireless communications
Shannon's theorem can describe the maximum data rate of any single wireless link, which relates to the bandwidth in hertz and to the noise on the channel.
One can greatly increase channel capacity by using MIMO techniques, where multiple aerials or multiple frequencies can exploit multiple paths to the receiver to achieve much higher throughput – by a factor of the product of the frequency and aerial diversity at each end.
Under Linux, the Central Regulatory Domain Agent (CRDA) controls the setting of channels.
Network:
The total network bandwidth depends on how dispersive the medium is (more dispersive medium generally has better total bandwidth because it minimises interference), how many frequencies are available, how noisy those frequencies are, how many aerials are used and whether a directional antenna is in use, whether nodes employ power control and so on.
Cellular wireless networks generally have good capacity, due to their use of directional aerials, and their ability to reuse radio channels in non-adjacent cells. Additionally, cells can be made very small using low power transmitters this is used in cities to give network capacity that scales linearly with population density
Safety:
See also: Wireless electronic devices and health
Wireless access points are also often close to humans, but the drop off in power over distance is fast, following the inverse-square law.
The position of the United Kingdom's Health Protection Agency (HPA) is that “...radio frequency (RF) exposures from WiFi are likely to be lower than those from mobile phones.” It also saw “...no reason why schools and others should not use WiFi equipment.”
In October 2007, the HPA launched a new “systematic” study into the effects of WiFi networks on behalf of the UK government, in order to calm fears that had appeared in the media in a recent period up to that time". Dr Michael Clark, of the HPA, says published research on mobile phones and masts does not add up to an indictment of WiFi.
See also:
Wireless networking is a method by which homes, telecommunications networks and business installations avoid the costly process of introducing cables into a building, or as a connection between various equipment locations.
Wireless telecommunications networks are generally implemented and administered using radio communication. This implementation takes place at the physical level (layer) of the OSI model network structure.
Examples of wireless networks include:
- cell phone networks,
- wireless local area networks (WLANs),
- wireless sensor networks,
- satellite communication networks,
- and terrestrial microwave networks.
The first professional wireless network was developed under the brand ALOHAnet in 1969 at the University of Hawaii and became operational in June 1971. The first commercial wireless network was the WaveLAN product family, developed by NCR in 1986.
- 1991 2G cell phone network
- June 1997 802.11 "Wi-Fi" protocol first release
- 1999 803.11 VoIP integration
Wireless Links:
- Terrestrial microwave – Terrestrial microwave communication uses Earth-based transmitters and receivers resembling satellite dishes. Terrestrial microwaves are in the low gigahertz range, which limits all communications to line-of-sight. Relay stations are spaced approximately 48 km (30 mi) apart.
- Communications satellites – Satellites communicate via microwave radio waves, which are not deflected by the Earth's atmosphere. The satellites are stationed in space, typically in geosynchronous orbit 35,400 km (22,000 mi) above the equator. These Earth-orbiting systems are capable of receiving and relaying voice, data, and TV signals.
- Cellular and PCS systems use several radio communications technologies. The systems divide the region covered into multiple geographic areas. Each area has a low-power transmitter or radio relay antenna device to relay calls from one area to the next area.
- Radio and spread spectrum technologies – Wireless local area networks use a high-frequency radio technology similar to digital cellular and a low-frequency radio technology. Wireless LANs use spread spectrum technology to enable communication between multiple devices in a limited area. IEEE 802.11 defines a common flavor of open-standards wireless radio-wave technology known as .
- Free-space optical communication uses visible or invisible light for communications. In most cases, line-of-sight propagation is used, which limits the physical positioning of communicating devices.
Types of wireless networks:
Wireless PAN:
Wireless personal area networks (WPANs) connect devices within a relatively small area, that is generally within a person's reach. For example, both Bluetooth radio and invisible infrared light provides a WPAN for interconnecting a headset to a laptop.
ZigBee also supports WPAN applications.
Wi-Fi PANs are becoming commonplace (2010) as equipment designers start to integrate Wi-Fi into a variety of consumer electronic devices. Intel "My WiFi" and Windows 7 "virtual Wi-Fi" capabilities have made Wi-Fi PANs simpler and easier to set up and configure.
Wireless LAN:
A wireless local area network (WLAN) links two or more devices over a short distance using a wireless distribution method, usually providing a connection through an access point for internet access. The use of spread-spectrum or OFDM technologies may allow users to move around within a local coverage area, and still remain connected to the network.
Products using the IEEE 802.11 WLAN standards are marketed under the Wi-Fi brand name.
Fixed wireless technology implements point-to-point links between computers or networks at two distant locations, often using dedicated microwave or modulated laser light beams over line of sight paths. It is often used in cities to connect networks in two or more buildings without installing a wired link. To connect to Wi-Fi, sometimes are used devices like a router or connecting HotSpot using mobile smartphones.
Wireless ad hoc network:
A wireless ad hoc network, also known as a wireless mesh network or mobile ad hoc network (MANET), is a wireless network made up of radio nodes organized in a mesh topology.
Each node forwards messages on behalf of the other nodes and each node performs routing. Ad hoc networks can "self-heal", automatically re-routing around a node that has lost power.
Various network layer protocols are needed to realize ad hoc mobile networks, including:
- Distance Sequenced Distance Vector routing,
- Associativity-Based Routing,
- Ad hoc on-demand Distance Vector routing,
- and Dynamic source routing.
Wireless MAN:
Wireless metropolitan area networks are a type of wireless network that connects several wireless LANs.
WiMAX is a type of Wireless MAN and is described by the IEEE 802.16 standard.
Wireless WAN:
Wireless wide area networks are wireless networks that typically cover large areas, such as between neighboring towns and cities, or city and suburb. These networks can be used to connect branch offices of business or as a public Internet access system.
The wireless connections between access points are usually point to point microwave links using parabolic dishes on the 2.4 GHz and 5.8Ghz band, rather than omnidirectional antennas used with smaller networks. A typical system contains base station gateways, access points and wireless bridging relays.
Other configurations are mesh systems where each access point acts as a relay also. When combined with renewable energy systems such as photovoltaic solar panels or wind systems they can be stand alone systems.
Cellular network:
Main article: cellular network
A cellular network or mobile network is a radio network distributed over land areas called cells, each served by at least one fixed-location transceiver, known as a cell site or base station.
In a cellular network, each cell characteristically uses a different set of radio frequencies from all their immediate neighbouring cells to avoid any interference.
When joined together these cells provide radio coverage over a wide geographic area. This enables a large number of portable transceivers (e.g., mobile phones, pagers, etc.) to communicate with each other and with fixed transceivers and telephones anywhere in the network, via base stations, even if some of the transceivers are moving through more than one cell during transmission.
Although originally intended for cell phones, with the development of smartphones, cellular telephone networks routinely carry data in addition to telephone conversations:
- Global System for Mobile Communications (GSM): The GSM network is divided into three major systems: the switching system, the base station system, and the operation and support system. The cell phone connects to the base system station which then connects to the operation and support station; it then connects to the switching station where the call is transferred to where it needs to go. GSM is the most common standard and is used for a majority of cell phones.
- Personal Communications Service (PCS): PCS is a radio band that can be used by mobile phones in North America and South Asia. Sprint happened to be the first service to set up a PCS.
- D-AMPS: Digital Advanced Mobile Phone Service, an upgraded version of AMPS, is being phased out due to advancement in technology. The newer GSM networks are replacing the older system.
Global area network:
A global area network (GAN) is a network used for supporting mobile across an arbitrary number of wireless LANs, satellite coverage areas, etc.
The key challenge in mobile communications is handing off user communications from one local coverage area to the next. In IEEE Project 802, this involves a succession of terrestrial wireless LANs.
Space network:
Space networks are networks used for communication between spacecraft, usually in the vicinity of the Earth. The example of this is NASA's Space Network.
Different Uses:
Some examples of usage include cellular phones which are part of everyday wireless networks, allowing easy personal communications. Another example, Intercontinental network systems, use radio satellites to communicate across the world.
Emergency services such as the police utilize wireless networks to communicate effectively as well. Individuals and businesses use wireless networks to send and share data rapidly, whether it be in a small office building or across the world.
Properties:
General:
In a general sense, wireless networks offer a vast variety of uses by both business and home users.
Now, the industry accepts a handful of different wireless technologies. Each wireless technology is defined by a standard that describes unique functions at both the Physical and the Data Link layers of the OSI model. These standards differ in their specified signaling methods, geographic ranges, and frequency usages, among other things.
Such differences can make certain technologies better suited to home networks and others better suited to network larger organizations.
Performance:
Each standard varies in geographical range, thus making one standard more ideal than the next depending on what it is one is trying to accomplish with a wireless network.
The performance of wireless networks satisfies a variety of applications such as voice and video. The use of this technology also gives room for expansions, such as from 2G to 3G and, 4G and 5G technologies, which stand for the fourth and fifth generation of cell phone mobile communications standards.
As wireless networking has become commonplace, sophistication increases through configuration of network hardware and software, and greater capacity to send and receive larger amounts of data, faster, is achieved. Now the wireless network has been running on LTE, which is a 4G mobile communication standard. Users of an LTE network should have data speeds that are 10x faster than a 3G network.
Space:
Space is another characteristic of wireless networking. Wireless networks offer many advantages when it comes to difficult-to-wire areas trying to communicate such as across a street or river, a warehouse on the other side of the premises or buildings that are physically separated but operate as one.
Wireless networks allow for users to designate a certain space which the network will be able to communicate with other devices through that network.
Space is also created in homes as a result of eliminating clutters of wiring. This technology allows for an alternative to installing physical network mediums such as TPs, coaxes, or fiber-optics, which can also be expensive.
Home:
For homeowners, wireless technology is an effective option compared to Ethernet for sharing printers, scanners, and high-speed Internet connections. WLANs help save the cost of installation of cable mediums, save time from physical installation, and also creates mobility for devices connected to the network. Wireless networks are simple and require as few as one single wireless access point connected directly to the Internet via a router.
Wireless Network Elements:
The telecommunications network at the physical layer also consists of many interconnected wireline network elements (NEs). These NEs can be stand-alone systems or products that are either supplied by a single manufacturer or are assembled by the service provider (user) or system integrator with parts from several different manufacturers.
Wireless NEs are the products and devices used by a wireless carrier to provide support for the backhaul network as well as a mobile switching center (MSC).
Reliable wireless service depends on the network elements at the physical layer to be protected against all operational environments and applications (see GR-3171, Generic Requirements for Network Elements Used in Wireless Networks – Physical Layer Criteria).
What are especially important are the NEs that are located on the cell tower to the base station (BS) cabinet. The attachment hardware and the positioning of the antenna and associated closures and cables are required to have adequate strength, robustness, corrosion resistance, and resistance against wind, storms, icing, and other weather conditions.
Requirements for individual components, such as hardware, cables, connectors, and closures, shall take into consideration the structure to which they are attached.
Difficulties:
Interference:
Compared to wired systems, wireless networks are frequently subject to electromagnetic interference. This can be caused by other networks or other types of equipment that generate radio waves that are within, or close, to the radio bands used for communication. Interference can degrade the signal or cause the system to fail.
Absorption and reflection:
Some materials cause absorption of electromagnetic waves, preventing it from reaching the receiver, in other cases, particularly with metallic or conductive materials reflection occurs.
This can cause dead zones where no reception is available. Aluminium foiled thermal isolation in modern homes can easily reduce indoor mobile signals by 10 dB frequently leading to complaints about the bad reception of long-distance rural cell signals.
Multipath fading:
In multipath fading two or more different routes taken by the signal, due to reflections, can cause the signal to cancel out at certain locations, and to be stronger in other places (upfade).
Hidden node problem:
The hidden node problem occurs in some types of network when a node is visible from a wireless access point (AP), but not from other nodes communicating with that AP. This leads to difficulties in media access control (collisions).
Exposed terminal node problem:
The exposed terminal problem is when a node on one network is unable to send because of interference from a node that is on a different network.
Shared resource problem:The wireless spectrum is a limited resource and shared by all nodes in the range of its transmitters.
Bandwidth allocation becomes complex with multiple participating users. Often users are not aware that advertised numbers (e.g., for IEEE 802.11 equipment or LTE networks) are not their capacity, but shared with all other users and thus the individual user rate is far lower.
With increasing demand, the capacity crunch is more and more likely to happen. User-in-the-loop (UIL) may be an alternative solution to ever upgrading to newer technologies for over-provisioning.
Capacity:
Channel:
Main article: Channel capacity in wireless communications
Shannon's theorem can describe the maximum data rate of any single wireless link, which relates to the bandwidth in hertz and to the noise on the channel.
One can greatly increase channel capacity by using MIMO techniques, where multiple aerials or multiple frequencies can exploit multiple paths to the receiver to achieve much higher throughput – by a factor of the product of the frequency and aerial diversity at each end.
Under Linux, the Central Regulatory Domain Agent (CRDA) controls the setting of channels.
Network:
The total network bandwidth depends on how dispersive the medium is (more dispersive medium generally has better total bandwidth because it minimises interference), how many frequencies are available, how noisy those frequencies are, how many aerials are used and whether a directional antenna is in use, whether nodes employ power control and so on.
Cellular wireless networks generally have good capacity, due to their use of directional aerials, and their ability to reuse radio channels in non-adjacent cells. Additionally, cells can be made very small using low power transmitters this is used in cities to give network capacity that scales linearly with population density
Safety:
See also: Wireless electronic devices and health
Wireless access points are also often close to humans, but the drop off in power over distance is fast, following the inverse-square law.
The position of the United Kingdom's Health Protection Agency (HPA) is that “...radio frequency (RF) exposures from WiFi are likely to be lower than those from mobile phones.” It also saw “...no reason why schools and others should not use WiFi equipment.”
In October 2007, the HPA launched a new “systematic” study into the effects of WiFi networks on behalf of the UK government, in order to calm fears that had appeared in the media in a recent period up to that time". Dr Michael Clark, of the HPA, says published research on mobile phones and masts does not add up to an indictment of WiFi.
See also:
- Rendezvous delay
- Wireless access point
- Wireless community network
- Wireless LAN client comparison
- Wireless site survey
- Network simulation
- Wireless at Curlie
Optical Fiber
- YouTube Video: Optical Fiber Communications
- YouTube Video: How It’s Made: Corning Fiber Optic Cable – Corning Optical Fiber Cable Manufacturing Process
* -- Excerpted from Optics and Photonics News, March, 2015 Issue:
Increases in consumer demand and machine-to-machine network traffic are creating big challenges for letting optical communications continue to scale cost-effectively. Meeting those demands will require new forms of optical parallelism.
Virtually every phone call we make today, every text message we send, every movie we download, every Internet-based application and service we use is at some point converted to photons that travel down a vast network of optical fibers. More than two billion kilometers of optical fibers have been deployed, a string of glass that could be wrapped around the globe more than 50,000 times.
Well over 100 million people now enjoy fiber optic connections directly to their homes. Optical fibers also link up the majority of cell towers, where the radio frequency photons picked up from billions of mobile phone users are immediately converted to infrared photons for efficient fiber optic backhaul into all-fiber metropolitan, regional, long-haul and submarine networks that connect cities, span countries and bridge continents.
Driven by a continual succession of largely unanticipated emerging applications and technologies, network traffic has grown exponentially over decades. More recently, it is no longer just the human ability to consume information that may ultimately set limits to required network bandwidth, but the by now dominant amount of machine-to-machine traffic arising from data-centric applications, sensor networks and the growing penetration of the Internet of Things, whose limits are primarily based on the economic value that these services can provide to society.
While historical data and forecasts of network traffic vary widely among service providers, geographic regions and application spaces, annual traffic growth rates between 20 percent and 90 percent are frequently reported, with close to 60 percent being a typical value observed for the expansion of North American Internet traffic since the late 1990s.
The role of optical fiber communication technologies is to ensure that cost-effective network traffic scaling can continue to enable future communications services as an underpinning of today’s digital information society. This article overviews the scaling of optical fiber communications, highlights practical as well as fundamental problems in network scalability, and points to some solutions currently being explored by the global fiber optic communications community.
Click here for full article.
___________________________________________________________________________
An optical fiber is a flexible, transparent fiber made by drawing glass (silica) or plastic to a diameter slightly thicker than that of a human hair.
Optical fibers are used most often as a means to transmit light between the two ends of the fiber and find wide usage in fiber-optic communications, where they permit transmission over longer distances and at higher bandwidths (data rates) than electrical cables.
Fibers are used instead of metal wires because signals travel along them with less loss; in addition, fibers are immune to electromagnetic interference, a problem from which metal wires suffer excessively.
Fibers are also used for illumination and imaging, and are often wrapped in bundles so they may be used to carry light into, or images out of confined spaces, as in the case of a fiberscope. Specially designed fibers are also used for a variety of other applications, some of them being fiber optic sensors and fiber lasers.
Optical fibers typically include a core surrounded by a transparent cladding material with a lower index of refraction. Light is kept in the core by the phenomenon of total internal reflection which causes the fiber to act as a waveguide.
Fibers that support many propagation paths or transverse modes are called multi-mode fibers, while those that support a single mode are called single-mode fibers (SMF). Multi-mode fibers generally have a wider core diameter and are used for short-distance communication links and for applications where high power must be transmitted. Single-mode fibers are used for most communication links longer than 1,000 meters (3,300 ft).
Being able to join optical fibers with low loss is important in fiber optic communication. This is more complex than joining electrical wire or cable and involves careful cleaving of the fibers, precise alignment of the fiber cores, and the coupling of these aligned cores. For applications that demand a permanent connection a fusion splice is common.
In this technique, an electric arc is used to melt the ends of the fibers together. Another common technique is a mechanical splice, where the ends of the fibers are held in contact by mechanical force. Temporary or semi-permanent connections are made by means of specialized optical fiber connectors.
The field of applied science and engineering concerned with the design and application of optical fibers is known as fiber optics. The term was coined by Indian physicist Narinder Singh Kapany, who is widely acknowledged as the father of fiber optics.
Click on any of the following blue hyperlinks for more about Optical Fiber Networking:
Increases in consumer demand and machine-to-machine network traffic are creating big challenges for letting optical communications continue to scale cost-effectively. Meeting those demands will require new forms of optical parallelism.
Virtually every phone call we make today, every text message we send, every movie we download, every Internet-based application and service we use is at some point converted to photons that travel down a vast network of optical fibers. More than two billion kilometers of optical fibers have been deployed, a string of glass that could be wrapped around the globe more than 50,000 times.
Well over 100 million people now enjoy fiber optic connections directly to their homes. Optical fibers also link up the majority of cell towers, where the radio frequency photons picked up from billions of mobile phone users are immediately converted to infrared photons for efficient fiber optic backhaul into all-fiber metropolitan, regional, long-haul and submarine networks that connect cities, span countries and bridge continents.
Driven by a continual succession of largely unanticipated emerging applications and technologies, network traffic has grown exponentially over decades. More recently, it is no longer just the human ability to consume information that may ultimately set limits to required network bandwidth, but the by now dominant amount of machine-to-machine traffic arising from data-centric applications, sensor networks and the growing penetration of the Internet of Things, whose limits are primarily based on the economic value that these services can provide to society.
While historical data and forecasts of network traffic vary widely among service providers, geographic regions and application spaces, annual traffic growth rates between 20 percent and 90 percent are frequently reported, with close to 60 percent being a typical value observed for the expansion of North American Internet traffic since the late 1990s.
The role of optical fiber communication technologies is to ensure that cost-effective network traffic scaling can continue to enable future communications services as an underpinning of today’s digital information society. This article overviews the scaling of optical fiber communications, highlights practical as well as fundamental problems in network scalability, and points to some solutions currently being explored by the global fiber optic communications community.
Click here for full article.
___________________________________________________________________________
An optical fiber is a flexible, transparent fiber made by drawing glass (silica) or plastic to a diameter slightly thicker than that of a human hair.
Optical fibers are used most often as a means to transmit light between the two ends of the fiber and find wide usage in fiber-optic communications, where they permit transmission over longer distances and at higher bandwidths (data rates) than electrical cables.
Fibers are used instead of metal wires because signals travel along them with less loss; in addition, fibers are immune to electromagnetic interference, a problem from which metal wires suffer excessively.
Fibers are also used for illumination and imaging, and are often wrapped in bundles so they may be used to carry light into, or images out of confined spaces, as in the case of a fiberscope. Specially designed fibers are also used for a variety of other applications, some of them being fiber optic sensors and fiber lasers.
Optical fibers typically include a core surrounded by a transparent cladding material with a lower index of refraction. Light is kept in the core by the phenomenon of total internal reflection which causes the fiber to act as a waveguide.
Fibers that support many propagation paths or transverse modes are called multi-mode fibers, while those that support a single mode are called single-mode fibers (SMF). Multi-mode fibers generally have a wider core diameter and are used for short-distance communication links and for applications where high power must be transmitted. Single-mode fibers are used for most communication links longer than 1,000 meters (3,300 ft).
Being able to join optical fibers with low loss is important in fiber optic communication. This is more complex than joining electrical wire or cable and involves careful cleaving of the fibers, precise alignment of the fiber cores, and the coupling of these aligned cores. For applications that demand a permanent connection a fusion splice is common.
In this technique, an electric arc is used to melt the ends of the fibers together. Another common technique is a mechanical splice, where the ends of the fibers are held in contact by mechanical force. Temporary or semi-permanent connections are made by means of specialized optical fiber connectors.
The field of applied science and engineering concerned with the design and application of optical fibers is known as fiber optics. The term was coined by Indian physicist Narinder Singh Kapany, who is widely acknowledged as the father of fiber optics.
Click on any of the following blue hyperlinks for more about Optical Fiber Networking:
- History
- Uses
- Principle of operation
- Mechanisms of attenuation
- Manufacturing
- Practical issues
- See also:
- Borescope
- Cable jetting
- Data cable
- Distributed acoustic sensing
- Endoscopy
- Fiber amplifier
- Fiber Bragg grating
- Fiber laser
- Fiber management system
- Fiber pigtail
- Fiberscope
- Fibre Channel
- Gradient-index optics
- Interconnect bottleneck
- Leaky mode
- Li-Fi
- Light Peak
- Modal bandwidth
- Optical amplifier
- Optical communication
- Optical mesh network
- Optical power meter
- Optical time-domain reflectometer
- Optoelectronics
- Parallel optical interface
- Photonic-crystal fiber
- Return loss
- Small form-factor pluggable transceiver
- Soliton, Vector soliton
- Submarine communications cables
- Subwavelength-diameter optical fibre
- Surround optical-fiber immunoassay (SOFIA)
- XENPAK
- The Fiber Optic Association The Fiber Optic Association
- FOA color code for connectors
- Lennie Lightwave's Guide To Fiber Optics
- "Fibers", article in RP Photonics' Encyclopedia of Laser Physics and Technology
- "Fibre optic technologies", Mercury Communications Ltd, August 1992.
- "Photonics & the future of fibre", Mercury Communications Ltd, March 1993.
- "Fiber Optic Tutorial" Educational site from Arc Electronics
- MIT Video Lecture: Understanding Lasers and Fiberoptics
- Fundamentals of Photonics: Module on Optical Waveguides and Fibers
- webdemo for chromatic dispersion Institute of Telecommunicatons, University of Stuttgart
Distributed Computing, including Peer-to-Peer Networks
Top: Challenges for a Distributed System
Bottom: A Peer-to-Peer network has no dedicated Servers.
- YouTube Video about Distributed Computing
- YouTube Video: What is P2P?
- YouTube Video: Difference between client server and peer to peer network
Top: Challenges for a Distributed System
Bottom: A Peer-to-Peer network has no dedicated Servers.
Distributed computing is a field of computer science that studies distributed systems. A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another.
The components interact with one another in order to achieve a common goal. Three significant characteristics of distributed systems are: concurrency of components, lack of a global clock, and independent failure of components. Examples of distributed systems vary from SOA-based systems to massively multiplayer online games to peer-to-peer applications.
A computer program that runs within a distributed system is called a distributed program (and distributed programming is the process of writing such programs). There are many different types of implementations for the message passing mechanism, including pure HTTP, RPC-like connectors and message queues.
Distributed computing also refers to the use of distributed systems to solve computational problems. In distributed computing, a problem is divided into many tasks, each of which is solved by one or more computers, which communicate with each other via message passing.
Click on any of the following blue hyperlinks more more about Distributed Computing:
Peer-to-peer (P2P) computing or networking is a distributed application architecture that partitions tasks or workloads between peers.
Peers are equally privileged, equipotent participants in the application. They are said to form a peer-to-peer network of nodes.Peers make a portion of their resources, such as processing power, disk storage or network bandwidth, directly available to other network participants, without the need for central coordination by servers or stable hosts.
Peers are both suppliers and consumers of resources, in contrast to the traditional client-server model in which the consumption and supply of resources is divided. Emerging collaborative P2P systems are going beyond the era of peers doing similar things while sharing resources, and are looking for diverse peers that can bring in unique resources and capabilities to a virtual community thereby empowering it to engage in greater tasks beyond those that can be accomplished by individual peers, yet that are beneficial to all the peers.
While P2P systems had previously been used in many application domains, the architecture was popularized by the file sharing system Napster, originally released in 1999.
The concept has inspired new structures and philosophies in many areas of human interaction. In such social contexts, peer-to-peer as a meme refers to the egalitarian social networking that has emerged throughout society, enabled by Internet technologies in general.
Click on any of the following blue hyperlinks for more about Peer-to-peer Networking:
The components interact with one another in order to achieve a common goal. Three significant characteristics of distributed systems are: concurrency of components, lack of a global clock, and independent failure of components. Examples of distributed systems vary from SOA-based systems to massively multiplayer online games to peer-to-peer applications.
A computer program that runs within a distributed system is called a distributed program (and distributed programming is the process of writing such programs). There are many different types of implementations for the message passing mechanism, including pure HTTP, RPC-like connectors and message queues.
Distributed computing also refers to the use of distributed systems to solve computational problems. In distributed computing, a problem is divided into many tasks, each of which is solved by one or more computers, which communicate with each other via message passing.
Click on any of the following blue hyperlinks more more about Distributed Computing:
- Introduction
- Parallel and distributed computing
- History
- Architectures
- Applications
- Examples
- Theoretical foundations
- See also:
- AppScale
- BOINC
- Code mobility
- Decentralized computing
- Distributed algorithm
- Distributed algorithmic mechanism design
- Distributed cache
- Distributed operating system
- Edsger W. Dijkstra Prize in Distributed Computing
- Fog computing
- Folding@home
- Grid computing
- Inferno
- Jungle computing
- Layered queueing network
- Library Oriented Architecture (LOA)
- List of distributed computing conferences
- List of distributed computing projects
- List of important publications in concurrent, parallel, and distributed computing
- Model checking
- Parallel distributed processing
- Parallel programming model
- Plan 9 from Bell Labs
- Shared nothing architecture
Peer-to-peer (P2P) computing or networking is a distributed application architecture that partitions tasks or workloads between peers.
Peers are equally privileged, equipotent participants in the application. They are said to form a peer-to-peer network of nodes.Peers make a portion of their resources, such as processing power, disk storage or network bandwidth, directly available to other network participants, without the need for central coordination by servers or stable hosts.
Peers are both suppliers and consumers of resources, in contrast to the traditional client-server model in which the consumption and supply of resources is divided. Emerging collaborative P2P systems are going beyond the era of peers doing similar things while sharing resources, and are looking for diverse peers that can bring in unique resources and capabilities to a virtual community thereby empowering it to engage in greater tasks beyond those that can be accomplished by individual peers, yet that are beneficial to all the peers.
While P2P systems had previously been used in many application domains, the architecture was popularized by the file sharing system Napster, originally released in 1999.
The concept has inspired new structures and philosophies in many areas of human interaction. In such social contexts, peer-to-peer as a meme refers to the egalitarian social networking that has emerged throughout society, enabled by Internet technologies in general.
Click on any of the following blue hyperlinks for more about Peer-to-peer Networking:
- Historical development
- Architecture
- Applications
- Social implications
- Political implications
- Current research
- See also:
Google including Search and Images
- YouTube Video: How Google Search Works
- YouTube Video: How Google makes improvements to its search algorithm
- YouTube Video: How Search by Image works
Google LLC is an United States based multinational technology company that specializes in Internet-related services and products, which include online advertising technologies, a search engine, cloud computing, software, and hardware. It is considered one of the Big Four technology companies alongside Amazon, Apple, and Microsoft.
Google was founded in September 1998 by Larry Page and Sergey Brin while they were Ph.D. students at Stanford University in California. Together they own about 14 percent of its shares and control 56 percent of the stockholder voting power through supervoting stock.
They incorporated Google as a California privately held company on September 4, 1998, in California. Google was then reincorporated in Delaware on October 22, 2002. An initial public offering (IPO) took place on August 19, 2004, and Google moved to its headquarters in Mountain View, California, nicknamed the Googleplex.
In August 2015, Google announced plans to reorganize its various interests as a conglomerate called Alphabet Inc. Google is Alphabet's leading subsidiary and will continue to be the umbrella company for Alphabet's Internet interests. Sundar Pichai was appointed CEO of Google, replacing Larry Page who became the CEO of Alphabet.
The company's rapid growth since incorporation has triggered a chain of products, acquisitions, and partnerships beyond Google's core search engine (Google Search below). It offers the following:
The company leads the development of the Android mobile operating system, the Google Chrome web browser, and Chrome OS, a lightweight operating system based on the Chrome browser.
Google has moved increasingly into hardware; from 2010 to 2015, it partnered with major electronics manufacturers in the production of its Nexus devices, and it released multiple hardware products in October 2016, including the Google Pixel smartphone, Google Home smart speaker, Google Wifi mesh wireless router, and Google Daydream virtual reality headset. Google has also experimented with becoming an Internet carrier (Google Fiber, Google Fi, and Google Station).
Google.com is the most visited website in the world. Several other Google services also figure in the top 100 most visited websites, including YouTube and Blogger. Google was the most valuable brand in the world in 2017 (surpassed by Amazon), but has received significant criticism involving issues such as privacy concerns, tax avoidance, antitrust, censorship, and search neutrality.
Click on any of the following blue hyperlinks for more about Google:
Google Search:
Google Search, also referred to as Google Web Search or simply Google, is a web search engine developed by Google. It is the most used search engine on the World Wide Web across all platforms, with 92.62% market share as of June 2019, handling more than 5.4 billion searches each day.
The order of search results returned by Google is based, in part, on a priority rank system called "PageRank".
Google Search also provides many different options for customized search, using symbols to include, exclude, specify or require certain search behavior, and offers specialized interactive experiences, such as flight status and package tracking, weather forecasts, currency, unit and time conversions, word definitions, and more.
The main purpose of Google Search is to search for text in publicly accessible documents offered by web servers, as opposed to other data, such as images or data contained in databases. It was originally developed in 1997 by Larry Page, Sergey Brin, and Scott Hassan.
In June 2011, Google introduced "Google Voice Search" to search for spoken, rather than typed, words. In May 2012, Google introduced a Knowledge Graph semantic search feature in the U.S.
Analysis of the frequency of search terms may indicate economic, social and health trends. Data about the frequency of use of search terms on Google can be openly inquired via Google Trends and have been shown to correlate with flu outbreaks and unemployment levels, and provide the information faster than traditional reporting methods and surveys. As of mid-2016, Google's search engine has begun to rely on deep neural networks.
Competitors of Google include:
Some smaller search engines offer facilities not available with Google, e.g. not storing any private or tracking information.
Within the U.S., as of July 2018, Bing handled 24.2 percent of all search queries. During the same period of time, Oath (formerly known as Yahoo) had a search market share of 11.5 percent. Market leader Google generated 63.2 percent of all core search queries in the U.S.
Click on any of the following blue hyperlinks for more about Google Search:
Google Images:
Google Images is a search service owned by Google that allows users to search the World Wide Web for image content. It was introduced on July 12, 2001 due to a demand for pictures of Jennifer Lopez's green Versace dress that the regular Google search couldn't handle. In 2011, reverse image search functionality was added.
When searching for an image, a thumbnail of each matching image is displayed. When the user clicks on a thumbnail, the image is displayed in a larger size, and users may visit the page on which the image is used.
Click on any of the following blue hyperlinks for more about Google Images:
Google was founded in September 1998 by Larry Page and Sergey Brin while they were Ph.D. students at Stanford University in California. Together they own about 14 percent of its shares and control 56 percent of the stockholder voting power through supervoting stock.
They incorporated Google as a California privately held company on September 4, 1998, in California. Google was then reincorporated in Delaware on October 22, 2002. An initial public offering (IPO) took place on August 19, 2004, and Google moved to its headquarters in Mountain View, California, nicknamed the Googleplex.
In August 2015, Google announced plans to reorganize its various interests as a conglomerate called Alphabet Inc. Google is Alphabet's leading subsidiary and will continue to be the umbrella company for Alphabet's Internet interests. Sundar Pichai was appointed CEO of Google, replacing Larry Page who became the CEO of Alphabet.
The company's rapid growth since incorporation has triggered a chain of products, acquisitions, and partnerships beyond Google's core search engine (Google Search below). It offers the following:
- services designed for work and productivity (Google Docs, Google Sheets, and Google Slides),
- email (Gmail),
- scheduling and time management (Google Calendar),
- cloud storage (Google Drive),
- instant messaging and video chat (Duo, Hangouts, and Meet), language translation (Google Translate),
- mapping and navigation (Google Maps, Waze, Google Earth, and Street View),
- podcast hosting (Google Podcasts),
- video sharing (YouTube),
- blog publishing (Blogger),
- note-taking (Google Keep, and Google Jamboard),
- and photo organizing and editing (Google Photos).
The company leads the development of the Android mobile operating system, the Google Chrome web browser, and Chrome OS, a lightweight operating system based on the Chrome browser.
Google has moved increasingly into hardware; from 2010 to 2015, it partnered with major electronics manufacturers in the production of its Nexus devices, and it released multiple hardware products in October 2016, including the Google Pixel smartphone, Google Home smart speaker, Google Wifi mesh wireless router, and Google Daydream virtual reality headset. Google has also experimented with becoming an Internet carrier (Google Fiber, Google Fi, and Google Station).
Google.com is the most visited website in the world. Several other Google services also figure in the top 100 most visited websites, including YouTube and Blogger. Google was the most valuable brand in the world in 2017 (surpassed by Amazon), but has received significant criticism involving issues such as privacy concerns, tax avoidance, antitrust, censorship, and search neutrality.
Click on any of the following blue hyperlinks for more about Google:
- History
- Products and services
- Corporate affairs
- Criticism and controversy
- See also:
- Official website
- "Google website". Archived from the original on November 11, 1998. Retrieved September 28, 2010.
- Carr, David F. (2006). "How Google Works". Baseline Magazine. 6 (6).
- Google at Crunchbase
- Google companies grouped at OpenCorporates
- Business data for Google, Inc.:
- Outline of Google
- History of Google
- List of mergers and acquisitions by Alphabet
- List of Google products
- Google China
- Google logo
- Googlization
- Google.org
- Google ATAP
Google Search:
Google Search, also referred to as Google Web Search or simply Google, is a web search engine developed by Google. It is the most used search engine on the World Wide Web across all platforms, with 92.62% market share as of June 2019, handling more than 5.4 billion searches each day.
The order of search results returned by Google is based, in part, on a priority rank system called "PageRank".
Google Search also provides many different options for customized search, using symbols to include, exclude, specify or require certain search behavior, and offers specialized interactive experiences, such as flight status and package tracking, weather forecasts, currency, unit and time conversions, word definitions, and more.
The main purpose of Google Search is to search for text in publicly accessible documents offered by web servers, as opposed to other data, such as images or data contained in databases. It was originally developed in 1997 by Larry Page, Sergey Brin, and Scott Hassan.
In June 2011, Google introduced "Google Voice Search" to search for spoken, rather than typed, words. In May 2012, Google introduced a Knowledge Graph semantic search feature in the U.S.
Analysis of the frequency of search terms may indicate economic, social and health trends. Data about the frequency of use of search terms on Google can be openly inquired via Google Trends and have been shown to correlate with flu outbreaks and unemployment levels, and provide the information faster than traditional reporting methods and surveys. As of mid-2016, Google's search engine has begun to rely on deep neural networks.
Competitors of Google include:
- Baidu and Soso.com in China;
- Naver.com and Daum.net in South Korea;
- Yandex in Russia;
- Seznam.cz in the Czech Republic;
- Qwant in France;
- Yahoo in Japan, Taiwan and the US,
- as well as Bing and DuckDuckGo.
Some smaller search engines offer facilities not available with Google, e.g. not storing any private or tracking information.
Within the U.S., as of July 2018, Bing handled 24.2 percent of all search queries. During the same period of time, Oath (formerly known as Yahoo) had a search market share of 11.5 percent. Market leader Google generated 63.2 percent of all core search queries in the U.S.
Click on any of the following blue hyperlinks for more about Google Search:
- Search indexing
- Performing a search
- Search results
- Ranking of results
- Google Doodles
- Smartphone apps
- Discontinued features
- Privacy
- Redesign
- Search products
- Energy consumption
- Criticism
- Trademark
- See also:
- Official website
- The Original Google!
- Google search trends
- Timeline of Google Search
- Censorship by Google § Google Search
- Google (verb)
- Dragonfly (search engine)
- Google bomb
- Google Panda
- Google Penguin
- Googlewhack
- Halalgoogling
- Reunion
- List of search engines
- Comparison of web search engines
- History of Google
- List of Google products
Google Images:
Google Images is a search service owned by Google that allows users to search the World Wide Web for image content. It was introduced on July 12, 2001 due to a demand for pictures of Jennifer Lopez's green Versace dress that the regular Google search couldn't handle. In 2011, reverse image search functionality was added.
When searching for an image, a thumbnail of each matching image is displayed. When the user clicks on a thumbnail, the image is displayed in a larger size, and users may visit the page on which the image is used.
Click on any of the following blue hyperlinks for more about Google Images:
- History
- Search by Image feature
- See also:
Analytics allows portal managers and business owners to track and analyze portal usage.
Analytics provides the following basic functionality:
Note:You must understand star schema database concepts in order to use Analytics’ custom event tracking features.
Components of Analytics:
Analytics is comprised of the following components:
Image below: Overview of Analytics
Analytics provides the following basic functionality:
- Usage Tracking Metrics: Analytics collects and reports metrics of common portal functions, including community, portlet and document hits.
- Behavior Tracking: Users of Analytics reports can analyze portal metrics to determine usage patterns, such as portal visit duration and usage over time.
- User Profile Correlation: Users of Analytics reports can correlate metric information with user profile information. Usage tracking reports can be viewed and filtered by user profile data such as country, company or title.
- Custom Event Tracking: Portal Administrators and developers can register custom portal and non-portal events that are sent to Analytics using the OpenUsage API. Event data is saved to the Analytics database, which can then be queried for reporting to a portal or non-portal application.
Note:You must understand star schema database concepts in order to use Analytics’ custom event tracking features.
Components of Analytics:
Analytics is comprised of the following components:
Image below: Overview of Analytics
Overview of Analytics Components
Click here for the following table that describes the components that are delivered with Analytics.
___________________________________________________________________________
Four Main Components of Google Analytics: see image below.
The four Main Components of Google Analytics include the following:
Courtesy of: PPC Success Center
Most of us, nowadays , are using maps to get the right directions with minimum troubles when we’re trying to head to a destination. Also, most of times we are using user guides or manuals when we are trying to figure out and to overview how things are working with a certain system, tool, machine or hardware just a few examples to mention.
This post is designed to identify and to overview –without complications – the four components that form Google Analytics, in addition to overviewing how those four components are working together nicely to generate required data that we need to meet our online marketing goals.
The recipe of the valuable reports that we see on our Google Analytics is made up of :
Click here for the following table that describes the components that are delivered with Analytics.
___________________________________________________________________________
Four Main Components of Google Analytics: see image below.
The four Main Components of Google Analytics include the following:
Courtesy of: PPC Success Center
Most of us, nowadays , are using maps to get the right directions with minimum troubles when we’re trying to head to a destination. Also, most of times we are using user guides or manuals when we are trying to figure out and to overview how things are working with a certain system, tool, machine or hardware just a few examples to mention.
This post is designed to identify and to overview –without complications – the four components that form Google Analytics, in addition to overviewing how those four components are working together nicely to generate required data that we need to meet our online marketing goals.
The recipe of the valuable reports that we see on our Google Analytics is made up of :
- Collection
- Configuration
- Processing
- Reporting
For your better reading experience, I preferred to discuss each of the four main components of Google Analytics in separate posts. So, stay tuned! Let’s begin with the first main component of Google Analytics: Collection.
Here are post short-cuts to other main components of Google Analytics:
Part-2 : Processing and Configuration in Google Analytics
Part-3 : Reporting In Google Analytics
Collection: Collection of data makes up the first one of the four main components that Google analytics depends on to generate reports. Google analytics is a powerful platform as it helps you to collect and measure user engagements and activities across different devices and environment.
Google Analytics lets you collect users interactions if you own websites, Android, iOS, or any digitally connected environment, for example a point of sale system or a Kiosk.
Let’s explain in little more details
I – Collection of website data:
If you would like to track a website, you should generate a small piece of JavaScript code in order to gather information. The code is easy to be set up on Google Analytics interface. Only you will need to follow simple and easy steps to have that snippet.
When you are done with setting up the web-tracking code, you are going to copy and paste that code into every page of your website. Two things you should do keep in mind:
<!-- Google Analytics --> <script> (function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){ (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o), m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m) })(window,document,'script','//www.google-analytics.com/analytics.js','ga'); ga('create', 'UA-XXXX-Y', 'auto'); ga('send', 'pageview'); </script> <!-- End Google Analytics -->
The above basic Google analytics JavaScript is able to collect many information about your users. The code is working on your website 24/7 – 365 days a year to deliver intelligent information about every single visit that your website had.
To explain more, that piece of code (without further customization) is capable of collecting and recording information related to the behavior, language, location, technology, devices etc. of your website users.
If you are looking to collect more and more data about the usage of your website, you can customize the above JavaScript snippets to measure what you might think beneficial to your reports. For example, with further customization, you can collect data across domains; you can set custom Dimensions and Metrics; you can measure Event Tracking and Social Interaction; you can set User Timings and/or User ID etc.
Note here that Google Analytics never collects and delivers any personally identifiable information in its reports such as names, IPs. It is completely prohibited. That is against Google Analytics policies.
II – Collection of Mobile Application data:
As we said before, Google Analytics is able of collecting data across many devices and environments. Said that, the way to implement the code and how data will be collected will differ from website tracking. The collection process is different in measuring interactions on Mobile app from websites. Mobile tracking – opposed to website tracking that use JavaScript – uses SDK (Software Development Kit) to collect user engagements on a certain operating system.
You may need a good developer to set SDK for you as the process is more complicated than setting Google Analytics JavaScript on websites. If you have good coding skills, you can check Google Developers.
Tips:
Overview:
That’s it. As you can see the way Google Analytics collects data is greatly determined via how you set up the code, where and which devices. Website tracking code enables JavaScript to collect valuable data about users activities without any customization. On other hands, Google Analytics mobile SDKs offer an intelligent way to track users who are using Androids or iOS devices.
___________________________________________________________________________
Google Analytics (Wikipedia):
Google Analytics is a web analytics service offered by Google that tracks and reports website traffic, currently as a platform inside the Google Marketing Platform brand. Google launched the service in November 2005 after acquiring Urchin.
As of 2019, Google Analytics is the most widely used web analytics service on the web.
Google Analytics provides an SDK that allows gathering usage data from iOS and Android app, known as Google Analytics for Mobile Apps.
Google Analytics can be blocked by browsers, browser extensions, and firewalls and other means.
Features:
Google Analytics is used to track website activity such as session duration, pages per session, bounce rate etc. of individuals using the site, along with the information on the source of the traffic. It can be integrated with Google Ads, with which users can create and review online campaigns by tracking landing page quality and conversions (goals).
Goals might include sales, lead generation, viewing a specific page, or downloading a particular file. Google Analytics' approach is to show high-level, dashboard-type data for the casual user, and more in-depth data further into the report set.
Google Analytics analysis can identify poorly performing pages with techniques such as funnel visualization, where visitors came from (referrers), how long they stayed on the website and their geographical position. It also provides more advanced features, including custom visitor segmentation.
Google Analytics e-commerce reporting can track sales activity and performance. The e-commerce reports shows a site's transactions, revenue, and many other commerce-related metrics.
On September 29, 2011, Google Analytics launched Real Time analytics, enabling a user to have insight about visitors currently on the site. A user can have 100 site profiles.
Each profile generally corresponds to one website. It is limited to sites which have traffic of fewer than 5 million pageviews per month (roughly 2 pageviews per second) unless the site is linked to a Google Ads campaign. Google Analytics includes Google Website Optimizer, rebranded as Google Analytics Content Experiments.
Google Analytics' Cohort analysis helps in understanding the behaviour of component groups of users apart from your user population. It is beneficial to marketers and analysts for successful implementation of a marketing strategy.
History:
Google acquired Urchin Software Corp. in April 2005. Google's service was developed from Urchin on Demand. The system also brings ideas from Adaptive Path, whose product, Measure Map, was acquired and used in the redesign of Google Analytics in 2006.
Google continued to sell the standalone, installable Urchin WebAnalytics Software through a network of value-added resellers until discontinuation on March 28, 2012.
The Google-branded version was rolled out in November 2005 to anyone who wished to sign up. However, due to extremely high demand for the service, new sign-ups were suspended only a week later. As capacity was added to the system, Google began using a lottery-type invitation-code model.
Before August 2006, Google was sending out batches of invitation codes as server availability permitted; since mid-August 2006 the service has been fully available to all users – whether they use Google for advertising or not.
The newer version of Google Analytics tracking code is known as the asynchronous tracking code, which Google claims is significantly more sensitive and accurate, and is able to track even very short activities on the website. The previous version delayed page loading, and so, for performance reasons, it was generally placed just before the </body> body close HTML tag. The new code can be placed between the <head>...</head> HTML head tags because, once triggered, it runs in parallel with page loading.
In April 2011 Google announced the availability of a new version of Google Analytics featuring multiple dashboards, more custom report options, and a new interface design. This version was later updated with some other features such as real-time analytics and goal flow charts.
In October 2012 another new version of Google Analytics was announced, called Universal Analytics. The key differences from the previous versions were: cross-platform tracking, flexible tracking code to collect data from any device, and the introduction of custom dimensions and custom metrics.
In March 2016, Google released Google Analytics 360, which is a software suite that provides analytics on return on investment and other marketing indicators. Google Analytics 360 includes five main products:
In October 2017 a new version of Google Analytics was announced, called Global Site Tag. Its stated purpose was to unify the tagging system to simplify implementation.
In June 2018, Google introduced Google Marketing Platform, an online advertisement and analytics brand. It consists of two former brands of Google, DoubleClick Digital Marketing and Google Analytics 360.
Technology:
Google Analytics is implemented with "page tags", in this case, called the Google Analytics Tracking Code, which is a snippet of JavaScript code that the website owner adds to every page of the website.
The tracking code runs in the client browser when the client browses the page (if JavaScript is enabled in the browser) and collects visitor data and sends it to a Google data collection server as part of a request for a web beacon.
The tracking code loads a larger JavaScript file from the Google web server and then sets variables with the user's account number. The larger file (currently known as ga.js) was typically 40 kB as of May 2018.
The file does not usually have to be loaded, however, due to browser caching. Assuming caching is enabled in the browser, it downloads ga.js only once at the start of the visit.
Furthermore, as all websites that implement Google Analytics with the ga.js code use the same master file from Google, a browser that has previously visited any other website running Google Analytics will already have the file cached on their machine.
In addition to transmitting information to a Google server, the tracking code sets a first party cookie (If cookies are enabled in the browser) on each visitor's computer. This cookie stores anonymous information called the ClientId.
Before the launch of Universal Analytics, there were several cookies storing information such as whether the visitor had been to the site before (new or returning visitor), the timestamp of the current visit, and the referrer site or campaign that directed the visitor to the page (e.g., search engine, keywords, banner, or email).
If the visitor arrived at the site by clicking on a link tagged with UTM parameters (Urchin Tracking Module) such as:
https://www.example.com/page?utm_content=buffercf3b2&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
then the tag values are passed to the database too.
Limitations:
In addition, Google Analytics for Mobile Package allows Google Analytics to be applied to mobile websites. The Mobile Package contains server-side tracking codes that use PHP, JavaServer Pages, ASP.NET, or Perl for its server-side language.
However, many ad filtering programs and extensions such as Firefox's Enhanced Tracking Protection, the browser extension NoScript and the mobile phone app Disconnect Mobile can block the Google Analytics Tracking Code. This prevents some traffic and users from being tracked and leads to holes in the collected data.
Also, privacy networks like Tor will mask the user's actual location and present inaccurate geographical data. A small fraction of users don't have JavaScript-enabled/capable browsers or turn this feature off. These limitations, mainly ad filtering programs, can allow a significant amount of visitors to avoid the tracker, sometimes more than the majority.
One potential impact on data accuracy comes from users deleting or blocking Google Analytics cookies. Without cookies being set, Google Analytics cannot collect data.
Any individual web user can block or delete cookies resulting in the data loss of those visits for Google Analytics users. Website owners can encourage users not to disable cookies; for example, by making visitors more comfortable using the site through posting a privacy policy.
These limitations affect the majority of web analytics tools which use page tags (usually JavaScript programs) embedded in web pages to collect visitor data, store it in cookies on the visitor's computer, and transmit it to a remote database by pretending to load a tiny graphic "beacon".
Another limitation of Google Analytics for large websites is the use of sampling in the generation of many of its reports. To reduce the load on their servers and to provide users with a relatively quick response to their query, Google Analytics limits reports to 500,000 randomly sampled sessions at the profile level for its calculations.
While margins of error are indicated for the visits metric, margins of error are not provided for any other metrics in the Google Analytics reports. For small segments of data, the margin of error can be very large.
Performance:
There have been several online discussions about the impact of Google Analytics on site performance. However, Google introduced asynchronous JavaScript code in December 2009 to reduce the risk of slowing the loading of pages tagged with the ga.js script.
Privacy:
Main articles: Browser security and Privacy concerns regarding Google
Due to its ubiquity, Google Analytics raises some privacy concerns. Whenever someone visits a website that uses Google Analytics, Google tracks that visit via the users' IP address in order to determine the user's approximate geographic location. To meet German legal requirements,
Google Analytics can anonymize the IP address. Google has also released a browser plug-in that turns off data about a page visit being sent to Google, however this browser extension is not available for mobile browsers.
Since this plug-in is produced and distributed by Google itself, it has met much discussion and criticism. Furthermore, the realization of Google scripts tracking user behavior has spawned the production of multiple, often open-source, browser plug-ins to reject tracking cookies.
These plug-ins allow users to block Google Analytics and similar sites from tracking their activities. However, partially because of new European privacy laws, most modern browsers allow users to reject tracking cookies, though Flash cookies can be a separate problem.
It has been anecdotally reported that errors can occur behind proxy servers and multiple firewalls, changing timestamps and registering invalid searches. Webmasters who seek to mitigate Google Analytics' specific privacy issues can employ a number of alternatives having their backends hosted on their own machines.
Until its discontinuation, an example of such a product was Urchin WebAnalytics Software from Google itself. On January 20, 2015, the Associated Press reported that HealthCare.gov was providing access to enrollees' personal data to private companies that specialized in advertising, mentioning Google Analytics specifically.
Support and training:
Google offers free Google Analytics IQ Lessons, Google Analytics certification test, free Help Center FAQ and Google Groups forum for official Google Analytics product support. New product features are announced on the Google Analytics Blog.
Enterprise support is provided through Google Analytics Certified Partners or Google Academy for Ads.
Third-party support:
The Google Analytics API is used by third parties to build custom applications such as reporting tools. Many such applications exist. One was built to run on iOS (Apple) devices and is featured in Apple's app store.
There are some third party products that also provide Google Analytics-based tracking. The Management API, Core Reporting API, MCF Reporting API, and Real Time Reporting API are subject to limits and quotas.
Popularity:
Google Analytics is the most widely used website statistics service. In May 2008, Pingdom released a survey stating that 161 of the 500 (32%) biggest sites globally according to their Alexa rank were using Google Analytics.
A later piece of market share analysis claimed that Google Analytics was used by around 49.95% of the top 1,000,000 websites (as ranked in 2010 by Alexa Internet).
In 2012, its use was around 55% of the 10,000 most popular websites. And in August 2013, Google Analytics was used by 66.2% of the 10,000 most popular websites ordered by popularity, as reported by BuiltWith.
See also:
Here are post short-cuts to other main components of Google Analytics:
Part-2 : Processing and Configuration in Google Analytics
Part-3 : Reporting In Google Analytics
Collection: Collection of data makes up the first one of the four main components that Google analytics depends on to generate reports. Google analytics is a powerful platform as it helps you to collect and measure user engagements and activities across different devices and environment.
Google Analytics lets you collect users interactions if you own websites, Android, iOS, or any digitally connected environment, for example a point of sale system or a Kiosk.
Let’s explain in little more details
I – Collection of website data:
If you would like to track a website, you should generate a small piece of JavaScript code in order to gather information. The code is easy to be set up on Google Analytics interface. Only you will need to follow simple and easy steps to have that snippet.
When you are done with setting up the web-tracking code, you are going to copy and paste that code into every page of your website. Two things you should do keep in mind:
- Place the code in the header, i.e. before the closing </head>. Why? To ensure that browser rendered and run the code to capture users even if they tend to leave before the page fully loaded.
- The code should be located in every page. (if you want to collect meaningful and correct information)
<!-- Google Analytics --> <script> (function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){ (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o), m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m) })(window,document,'script','//www.google-analytics.com/analytics.js','ga'); ga('create', 'UA-XXXX-Y', 'auto'); ga('send', 'pageview'); </script> <!-- End Google Analytics -->
- UA-XXX-Y is your unique property Id. You are going to need it if you are going to use Google Tag Manager or WordPress Analytics Plugins. ( Think of it like a person ID)
- analytics.js means you are using the newest version of Google Analytics that called” Universal Analytics”. ( Not the classic Google Analytics :(ga.js) )
- pageview means the snippet is firing ”pageviews hits” on the pages that being tracked. That is the basic. You can customize Google Analytics JavaScript as per your needs to track more insightful data in your website like for example implementing Display Features.
- Tracking Code above is executed asynchronously which means the code is working hard in the background while the browser is reading the page.
- With Google Analytics website tracking, data is being sent to the collection Google Analytics servers in real time.(#Mobiles uses dispatching – see below)
- The Tracking Code can be customized if you look into collecting additional information about your website users.
The above basic Google analytics JavaScript is able to collect many information about your users. The code is working on your website 24/7 – 365 days a year to deliver intelligent information about every single visit that your website had.
To explain more, that piece of code (without further customization) is capable of collecting and recording information related to the behavior, language, location, technology, devices etc. of your website users.
If you are looking to collect more and more data about the usage of your website, you can customize the above JavaScript snippets to measure what you might think beneficial to your reports. For example, with further customization, you can collect data across domains; you can set custom Dimensions and Metrics; you can measure Event Tracking and Social Interaction; you can set User Timings and/or User ID etc.
Note here that Google Analytics never collects and delivers any personally identifiable information in its reports such as names, IPs. It is completely prohibited. That is against Google Analytics policies.
II – Collection of Mobile Application data:
As we said before, Google Analytics is able of collecting data across many devices and environments. Said that, the way to implement the code and how data will be collected will differ from website tracking. The collection process is different in measuring interactions on Mobile app from websites. Mobile tracking – opposed to website tracking that use JavaScript – uses SDK (Software Development Kit) to collect user engagements on a certain operating system.
You may need a good developer to set SDK for you as the process is more complicated than setting Google Analytics JavaScript on websites. If you have good coding skills, you can check Google Developers.
Tips:
- There are two SDKs. One is for Andriod and other one for iOS.
- Collection of mobile data uses Dispatching which means the data is stored for an amount of time to be re-sent later as ”hits” to Google Analytics Servers.
- Dispatching time may vary. Automatically, it is set for 30 min on Andriod devices and 2 min for iOS. The timings can be customized on the tracking code(SDK) to suit your mobile battery life.
- SDKs are customized to track more information about your visitors.
Overview:
That’s it. As you can see the way Google Analytics collects data is greatly determined via how you set up the code, where and which devices. Website tracking code enables JavaScript to collect valuable data about users activities without any customization. On other hands, Google Analytics mobile SDKs offer an intelligent way to track users who are using Androids or iOS devices.
___________________________________________________________________________
Google Analytics (Wikipedia):
Google Analytics is a web analytics service offered by Google that tracks and reports website traffic, currently as a platform inside the Google Marketing Platform brand. Google launched the service in November 2005 after acquiring Urchin.
As of 2019, Google Analytics is the most widely used web analytics service on the web.
Google Analytics provides an SDK that allows gathering usage data from iOS and Android app, known as Google Analytics for Mobile Apps.
Google Analytics can be blocked by browsers, browser extensions, and firewalls and other means.
Features:
Google Analytics is used to track website activity such as session duration, pages per session, bounce rate etc. of individuals using the site, along with the information on the source of the traffic. It can be integrated with Google Ads, with which users can create and review online campaigns by tracking landing page quality and conversions (goals).
Goals might include sales, lead generation, viewing a specific page, or downloading a particular file. Google Analytics' approach is to show high-level, dashboard-type data for the casual user, and more in-depth data further into the report set.
Google Analytics analysis can identify poorly performing pages with techniques such as funnel visualization, where visitors came from (referrers), how long they stayed on the website and their geographical position. It also provides more advanced features, including custom visitor segmentation.
Google Analytics e-commerce reporting can track sales activity and performance. The e-commerce reports shows a site's transactions, revenue, and many other commerce-related metrics.
On September 29, 2011, Google Analytics launched Real Time analytics, enabling a user to have insight about visitors currently on the site. A user can have 100 site profiles.
Each profile generally corresponds to one website. It is limited to sites which have traffic of fewer than 5 million pageviews per month (roughly 2 pageviews per second) unless the site is linked to a Google Ads campaign. Google Analytics includes Google Website Optimizer, rebranded as Google Analytics Content Experiments.
Google Analytics' Cohort analysis helps in understanding the behaviour of component groups of users apart from your user population. It is beneficial to marketers and analysts for successful implementation of a marketing strategy.
History:
Google acquired Urchin Software Corp. in April 2005. Google's service was developed from Urchin on Demand. The system also brings ideas from Adaptive Path, whose product, Measure Map, was acquired and used in the redesign of Google Analytics in 2006.
Google continued to sell the standalone, installable Urchin WebAnalytics Software through a network of value-added resellers until discontinuation on March 28, 2012.
The Google-branded version was rolled out in November 2005 to anyone who wished to sign up. However, due to extremely high demand for the service, new sign-ups were suspended only a week later. As capacity was added to the system, Google began using a lottery-type invitation-code model.
Before August 2006, Google was sending out batches of invitation codes as server availability permitted; since mid-August 2006 the service has been fully available to all users – whether they use Google for advertising or not.
The newer version of Google Analytics tracking code is known as the asynchronous tracking code, which Google claims is significantly more sensitive and accurate, and is able to track even very short activities on the website. The previous version delayed page loading, and so, for performance reasons, it was generally placed just before the </body> body close HTML tag. The new code can be placed between the <head>...</head> HTML head tags because, once triggered, it runs in parallel with page loading.
In April 2011 Google announced the availability of a new version of Google Analytics featuring multiple dashboards, more custom report options, and a new interface design. This version was later updated with some other features such as real-time analytics and goal flow charts.
In October 2012 another new version of Google Analytics was announced, called Universal Analytics. The key differences from the previous versions were: cross-platform tracking, flexible tracking code to collect data from any device, and the introduction of custom dimensions and custom metrics.
In March 2016, Google released Google Analytics 360, which is a software suite that provides analytics on return on investment and other marketing indicators. Google Analytics 360 includes five main products:
- Analytics,
- Tag Manager,
- Optimize,
- Data Studio,
- Surveys, Attribution, and Audience Center.
In October 2017 a new version of Google Analytics was announced, called Global Site Tag. Its stated purpose was to unify the tagging system to simplify implementation.
In June 2018, Google introduced Google Marketing Platform, an online advertisement and analytics brand. It consists of two former brands of Google, DoubleClick Digital Marketing and Google Analytics 360.
Technology:
Google Analytics is implemented with "page tags", in this case, called the Google Analytics Tracking Code, which is a snippet of JavaScript code that the website owner adds to every page of the website.
The tracking code runs in the client browser when the client browses the page (if JavaScript is enabled in the browser) and collects visitor data and sends it to a Google data collection server as part of a request for a web beacon.
The tracking code loads a larger JavaScript file from the Google web server and then sets variables with the user's account number. The larger file (currently known as ga.js) was typically 40 kB as of May 2018.
The file does not usually have to be loaded, however, due to browser caching. Assuming caching is enabled in the browser, it downloads ga.js only once at the start of the visit.
Furthermore, as all websites that implement Google Analytics with the ga.js code use the same master file from Google, a browser that has previously visited any other website running Google Analytics will already have the file cached on their machine.
In addition to transmitting information to a Google server, the tracking code sets a first party cookie (If cookies are enabled in the browser) on each visitor's computer. This cookie stores anonymous information called the ClientId.
Before the launch of Universal Analytics, there were several cookies storing information such as whether the visitor had been to the site before (new or returning visitor), the timestamp of the current visit, and the referrer site or campaign that directed the visitor to the page (e.g., search engine, keywords, banner, or email).
If the visitor arrived at the site by clicking on a link tagged with UTM parameters (Urchin Tracking Module) such as:
https://www.example.com/page?utm_content=buffercf3b2&utm_medium=social&utm_source=facebook.com&utm_campaign=buffer
then the tag values are passed to the database too.
Limitations:
In addition, Google Analytics for Mobile Package allows Google Analytics to be applied to mobile websites. The Mobile Package contains server-side tracking codes that use PHP, JavaServer Pages, ASP.NET, or Perl for its server-side language.
However, many ad filtering programs and extensions such as Firefox's Enhanced Tracking Protection, the browser extension NoScript and the mobile phone app Disconnect Mobile can block the Google Analytics Tracking Code. This prevents some traffic and users from being tracked and leads to holes in the collected data.
Also, privacy networks like Tor will mask the user's actual location and present inaccurate geographical data. A small fraction of users don't have JavaScript-enabled/capable browsers or turn this feature off. These limitations, mainly ad filtering programs, can allow a significant amount of visitors to avoid the tracker, sometimes more than the majority.
One potential impact on data accuracy comes from users deleting or blocking Google Analytics cookies. Without cookies being set, Google Analytics cannot collect data.
Any individual web user can block or delete cookies resulting in the data loss of those visits for Google Analytics users. Website owners can encourage users not to disable cookies; for example, by making visitors more comfortable using the site through posting a privacy policy.
These limitations affect the majority of web analytics tools which use page tags (usually JavaScript programs) embedded in web pages to collect visitor data, store it in cookies on the visitor's computer, and transmit it to a remote database by pretending to load a tiny graphic "beacon".
Another limitation of Google Analytics for large websites is the use of sampling in the generation of many of its reports. To reduce the load on their servers and to provide users with a relatively quick response to their query, Google Analytics limits reports to 500,000 randomly sampled sessions at the profile level for its calculations.
While margins of error are indicated for the visits metric, margins of error are not provided for any other metrics in the Google Analytics reports. For small segments of data, the margin of error can be very large.
Performance:
There have been several online discussions about the impact of Google Analytics on site performance. However, Google introduced asynchronous JavaScript code in December 2009 to reduce the risk of slowing the loading of pages tagged with the ga.js script.
Privacy:
Main articles: Browser security and Privacy concerns regarding Google
Due to its ubiquity, Google Analytics raises some privacy concerns. Whenever someone visits a website that uses Google Analytics, Google tracks that visit via the users' IP address in order to determine the user's approximate geographic location. To meet German legal requirements,
Google Analytics can anonymize the IP address. Google has also released a browser plug-in that turns off data about a page visit being sent to Google, however this browser extension is not available for mobile browsers.
Since this plug-in is produced and distributed by Google itself, it has met much discussion and criticism. Furthermore, the realization of Google scripts tracking user behavior has spawned the production of multiple, often open-source, browser plug-ins to reject tracking cookies.
These plug-ins allow users to block Google Analytics and similar sites from tracking their activities. However, partially because of new European privacy laws, most modern browsers allow users to reject tracking cookies, though Flash cookies can be a separate problem.
It has been anecdotally reported that errors can occur behind proxy servers and multiple firewalls, changing timestamps and registering invalid searches. Webmasters who seek to mitigate Google Analytics' specific privacy issues can employ a number of alternatives having their backends hosted on their own machines.
Until its discontinuation, an example of such a product was Urchin WebAnalytics Software from Google itself. On January 20, 2015, the Associated Press reported that HealthCare.gov was providing access to enrollees' personal data to private companies that specialized in advertising, mentioning Google Analytics specifically.
Support and training:
Google offers free Google Analytics IQ Lessons, Google Analytics certification test, free Help Center FAQ and Google Groups forum for official Google Analytics product support. New product features are announced on the Google Analytics Blog.
Enterprise support is provided through Google Analytics Certified Partners or Google Academy for Ads.
Third-party support:
The Google Analytics API is used by third parties to build custom applications such as reporting tools. Many such applications exist. One was built to run on iOS (Apple) devices and is featured in Apple's app store.
There are some third party products that also provide Google Analytics-based tracking. The Management API, Core Reporting API, MCF Reporting API, and Real Time Reporting API are subject to limits and quotas.
Popularity:
Google Analytics is the most widely used website statistics service. In May 2008, Pingdom released a survey stating that 161 of the 500 (32%) biggest sites globally according to their Alexa rank were using Google Analytics.
A later piece of market share analysis claimed that Google Analytics was used by around 49.95% of the top 1,000,000 websites (as ranked in 2010 by Alexa Internet).
In 2012, its use was around 55% of the 10,000 most popular websites. And in August 2013, Google Analytics was used by 66.2% of the 10,000 most popular websites ordered by popularity, as reported by BuiltWith.
See also:
- Official website
- Official blog
- Google marketing platform
- Google analytics help
- List of web analytics software
Google Search Console
- YouTube Video: New Google Search Console: How To Begin Optimizing Your Website
- YouTube Video: Google Search Console Tutorial 2020 Step-By-Step - Google Webmaster Tools Tutorial
- YouTube Video: Updated 2020 Tutorial // How to Link Google Analytics and Google Search Console
Google Search Console is a web service by Google which allows webmasters to check indexing status and optimize visibility of their websites.
Until May 20, 2015 the service was called Google Webmaster Tools. In January 2018, Google introduced a new version of the search console, with changes to the user interface. In September of 2019, old Search Console reports, including the home and dashboard pages, were removed.
Features:
This service includes tools that let webmasters
Criticism and controversy:
The list of inbound links on Google Webmaster Tools is generally much larger than the list of inbound links that can be discovered using the link:example.com search query on Google itself.
The list on Google Webmaster Tools includes nofollow links that do not convey search engine optimization authority to the linked site.
On the other hand, the list of links generated with a link:example.com type query is deemed by Google to be "important" links in a controversial way. Google Webmaster Tools, as well as the Google index, seems to routinely ignore link spam.
Once a manual penalty has been removed, Google Webmaster Tools will still display the penalty for another 1–3 days. After the Google Search Console re-brand, information has been produced demonstrating that Google Search Console creates data points that do not reconcile with Google Analytics or ranking data, particularly within the local search market.
See also:
Until May 20, 2015 the service was called Google Webmaster Tools. In January 2018, Google introduced a new version of the search console, with changes to the user interface. In September of 2019, old Search Console reports, including the home and dashboard pages, were removed.
Features:
This service includes tools that let webmasters
- Submit and check a sitemap.
- Check and set the crawl rate, and view statistics about when Googlebot accesses a particular site.
- Write and check a robots.txt file to help discover pages that are blocked in robots.txt accidentally.
- List internal and external pages that link to the website.
- Get a list of links which Googlebot had difficulty in crawling, including the error that Googlebot received when accessing the URLs in question.
- See what keyword searches on Google led to the site being listed in the SERPs, and the total clicks, total impressions, and the average click through rates of such listings. (Previously named 'Search Queries'; re-branded May 20, 2015 to 'Search Analytics' with extended filter possibilities for devices, search types and date periods).
- Set a preferred domain (e.g. prefer example.com over www.example.com or vice versa), which determines how the site URL is displayed in SERPs.
- Highlight to Google Search elements of structured data which are used to enrich search hit entries (released in December 2012 as Google Data Highlighter).
- View site speed reports from the Chrome User Experience Report.
- Receive notifications from Google for manual penalties.
- Provide access to an API to add, change and delete listings and list crawl errors.
- Rich Cards a new section added, for better mobile user experience.
- Check the security issues if there are any with the website. (Hacked Site or Malware Attacks)
- Add or remove the property owners and associates of the web property.
- Google Search console brought an advance featured breadcrumbs and Amp to provide ultimate help to the users.
Criticism and controversy:
The list of inbound links on Google Webmaster Tools is generally much larger than the list of inbound links that can be discovered using the link:example.com search query on Google itself.
The list on Google Webmaster Tools includes nofollow links that do not convey search engine optimization authority to the linked site.
On the other hand, the list of links generated with a link:example.com type query is deemed by Google to be "important" links in a controversial way. Google Webmaster Tools, as well as the Google index, seems to routinely ignore link spam.
Once a manual penalty has been removed, Google Webmaster Tools will still display the penalty for another 1–3 days. After the Google Search Console re-brand, information has been produced demonstrating that Google Search Console creates data points that do not reconcile with Google Analytics or ranking data, particularly within the local search market.
See also:
- Google Search Console
- Google Search Console (New version)
- "Official Google Webmaster Central Blog". Webmaster Central Blog. Google. 2010-02-16. Retrieved 2010-02-16.
- "Official Google Webmaster Central Help Forum". Webmaster Central Help Forum. Google. 2010-02-16. Retrieved 2010-02-16.
- Bing Webmaster Tools
- Google Insights for Search
Tim Berners-Lee, Inventor of the World Wide Web: "He Created the Web. Now He’s Out to Remake the Digital World".
(NY Times, 1/10/2021)
(NY Times, 1/10/2021)
- YouTube Video: Sir Tim Berners-Lee on how he came up with the Internet | Washington Post
- YouTube Video: Celebrating 30 years of the Web with Sir Tim Berners-Lee at the Science Museum
- YouTube Video: Father of the Web Sir Tim Berners-Lee prepares 'do-over'

Sir Tim Berners-Lee Created the Web. Now He’s Out to Remake the Digital World
Tim Berners-Lee wants to put people in control of their personal data. He has technology and a start-up pursuing that goal. Can he succeed?
Three decades ago, Tim Berners-Lee devised simple yet powerful standards for locating, linking and presenting multimedia documents online. He set them free into the world, unleashing the World Wide Web.
Others became internet billionaires, while Mr. Berners-Lee became the steward of the technical norms intended to help the web flourish as an egalitarian tool of connection and information sharing.
But now, Mr. Berners-Lee, 65, believes the online world has gone astray. Too much power and too much personal data, he says, reside with the tech giants like Google and Facebook — “silos” is the generic term he favors, instead of referring to the companies by name. Fueled by vast troves of data, he says, they have become surveillance platforms and gatekeepers of innovation.
Regulators have voiced similar complaints. The big tech companies are facing tougher privacy rules in Europe and some American states, led by California. Google and Facebook have been hit with antitrust suits.
But Mr. Berners-Lee is taking a different approach: His answer to the problem is technology that gives individuals more power.
The goal, he said, is to move toward “the web that I originally wanted.”
“Pods,” personal online data stores, are a key technical ingredient to achieve that goal. The idea is that each person could control his or her own data — websites visited, credit card purchases, workout routines, music streamed — in an individual data safe, typically a sliver of server space.
Companies could gain access to a person’s data, with permission, through a secure link for a specific task like processing a loan application or delivering a personalized ad. They could link to and use personal information selectively, but not store it.
Mr. Berners-Lee’s vision of personal data sovereignty stands in sharp contrast to the harvest-and-hoard model of the big tech companies. But it has some echoes of the original web formula — a set of technology standards that developers can use to write programs and that entrepreneurs and companies can use to build businesses. He began an open-source software project, Solid, and later founded a company, Inrupt, with John Bruce, a veteran of five previous start-ups, to kick-start adoption.
“This is about making markets,” said Mr. Berners-Lee, who is Inrupt’s chief technology officer.
Inrupt introduced in November its server software for enterprises and government agencies. And the start-up is getting a handful of pilot projects underway in earnest this year, including ones with Britain’s National Health Service and with the government of Flanders, the Dutch-speaking region of Belgium.
The Overlooked Stone Carvers of Escolásticas: Inrupt’s initial business model is to charge licensing fees for its commercial software, which uses the Solid open-source technology but has enhanced security, management and developer tools. The Boston-based company has raised about $20 million in venture funding.
Start-ups, Mr. Berners-Lee noted, can play a crucial role in accelerating the adoption of a new technology. The web, he said, really took off after Netscape introduced web-browsing software and Red Hat brought Linux, the open-source operating system, into corporate data centers.
Click here for the rest of the NY Times Article.
___________________________________________________________________________
Sir Tim Berners-Lee (Wikipedia)
Sir Timothy John Berners-Lee OM KBE FRS FREng FRSA FBCS (born 8 June 1955), also known as TimBL, is an English computer scientist best known as the inventor of the World Wide Web. He is a Professorial Fellow of Computer Science at the University of Oxford and a professor at the Massachusetts Institute of Technology (MIT).
Berners-Lee proposed an information management system on 12 March 1989, then implemented the first successful communication between a Hypertext Transfer Protocol (HTTP) client and server via the Internet in mid-November.
Berners-Lee is the director of the World Wide Web Consortium (W3C), which oversees the continued development of the Web. He co-founded (with his then wife-to-be Rosemary Leith) the World Wide Web Foundation. He is a senior researcher and holder of the 3Com founder's chair at the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). He is a director of the Web Science Research Initiative (WSRI) and a member of the advisory board of the MIT Center for Collective Intelligence.
In 2011, he was named as a member of the board of trustees of the Ford Foundation. He is a founder and president of the Open Data Institute and is currently an advisor at social network MeWe.
In 2004, Berners-Lee was knighted by Queen Elizabeth II for his pioneering work. He devised and implemented the first Web browser and Web server, and helped foster the Web's subsequent explosive development. He currently directs the W3 Consortium, developing tools and standards to further the Web's potential. In April 2009, he was elected as Foreign Associate of the National Academy of Sciences.
He was named in Time magazine's list of the 100 Most Important People of the 20th century and has received a number of other accolades for his invention. He was honored as the "Inventor of the World Wide Web" during the 2012 Summer Olympics opening ceremony in which he appeared working with a vintage NeXT Computer.
He tweeted "This is for everyone" which appeared in LED lights attached to the chairs of the audience. He received the 2016 Turing Award "for inventing the World Wide Web, the first web browser, and the fundamental protocols and algorithms allowing the Web to scale"
Click on any of the following blue hyperlinks for more about Sir Tim Bertners-Lee:
Tim Berners-Lee wants to put people in control of their personal data. He has technology and a start-up pursuing that goal. Can he succeed?
Three decades ago, Tim Berners-Lee devised simple yet powerful standards for locating, linking and presenting multimedia documents online. He set them free into the world, unleashing the World Wide Web.
Others became internet billionaires, while Mr. Berners-Lee became the steward of the technical norms intended to help the web flourish as an egalitarian tool of connection and information sharing.
But now, Mr. Berners-Lee, 65, believes the online world has gone astray. Too much power and too much personal data, he says, reside with the tech giants like Google and Facebook — “silos” is the generic term he favors, instead of referring to the companies by name. Fueled by vast troves of data, he says, they have become surveillance platforms and gatekeepers of innovation.
Regulators have voiced similar complaints. The big tech companies are facing tougher privacy rules in Europe and some American states, led by California. Google and Facebook have been hit with antitrust suits.
But Mr. Berners-Lee is taking a different approach: His answer to the problem is technology that gives individuals more power.
The goal, he said, is to move toward “the web that I originally wanted.”
“Pods,” personal online data stores, are a key technical ingredient to achieve that goal. The idea is that each person could control his or her own data — websites visited, credit card purchases, workout routines, music streamed — in an individual data safe, typically a sliver of server space.
Companies could gain access to a person’s data, with permission, through a secure link for a specific task like processing a loan application or delivering a personalized ad. They could link to and use personal information selectively, but not store it.
Mr. Berners-Lee’s vision of personal data sovereignty stands in sharp contrast to the harvest-and-hoard model of the big tech companies. But it has some echoes of the original web formula — a set of technology standards that developers can use to write programs and that entrepreneurs and companies can use to build businesses. He began an open-source software project, Solid, and later founded a company, Inrupt, with John Bruce, a veteran of five previous start-ups, to kick-start adoption.
“This is about making markets,” said Mr. Berners-Lee, who is Inrupt’s chief technology officer.
Inrupt introduced in November its server software for enterprises and government agencies. And the start-up is getting a handful of pilot projects underway in earnest this year, including ones with Britain’s National Health Service and with the government of Flanders, the Dutch-speaking region of Belgium.
The Overlooked Stone Carvers of Escolásticas: Inrupt’s initial business model is to charge licensing fees for its commercial software, which uses the Solid open-source technology but has enhanced security, management and developer tools. The Boston-based company has raised about $20 million in venture funding.
Start-ups, Mr. Berners-Lee noted, can play a crucial role in accelerating the adoption of a new technology. The web, he said, really took off after Netscape introduced web-browsing software and Red Hat brought Linux, the open-source operating system, into corporate data centers.
Click here for the rest of the NY Times Article.
___________________________________________________________________________
Sir Tim Berners-Lee (Wikipedia)
Sir Timothy John Berners-Lee OM KBE FRS FREng FRSA FBCS (born 8 June 1955), also known as TimBL, is an English computer scientist best known as the inventor of the World Wide Web. He is a Professorial Fellow of Computer Science at the University of Oxford and a professor at the Massachusetts Institute of Technology (MIT).
Berners-Lee proposed an information management system on 12 March 1989, then implemented the first successful communication between a Hypertext Transfer Protocol (HTTP) client and server via the Internet in mid-November.
Berners-Lee is the director of the World Wide Web Consortium (W3C), which oversees the continued development of the Web. He co-founded (with his then wife-to-be Rosemary Leith) the World Wide Web Foundation. He is a senior researcher and holder of the 3Com founder's chair at the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). He is a director of the Web Science Research Initiative (WSRI) and a member of the advisory board of the MIT Center for Collective Intelligence.
In 2011, he was named as a member of the board of trustees of the Ford Foundation. He is a founder and president of the Open Data Institute and is currently an advisor at social network MeWe.
In 2004, Berners-Lee was knighted by Queen Elizabeth II for his pioneering work. He devised and implemented the first Web browser and Web server, and helped foster the Web's subsequent explosive development. He currently directs the W3 Consortium, developing tools and standards to further the Web's potential. In April 2009, he was elected as Foreign Associate of the National Academy of Sciences.
He was named in Time magazine's list of the 100 Most Important People of the 20th century and has received a number of other accolades for his invention. He was honored as the "Inventor of the World Wide Web" during the 2012 Summer Olympics opening ceremony in which he appeared working with a vintage NeXT Computer.
He tweeted "This is for everyone" which appeared in LED lights attached to the chairs of the audience. He received the 2016 Turing Award "for inventing the World Wide Web, the first web browser, and the fundamental protocols and algorithms allowing the Web to scale"
Click on any of the following blue hyperlinks for more about Sir Tim Bertners-Lee:
- Early Life and education
- Career and research
- Personal life
- See also:
- Tim Berners-Lee at TED
- Tim Berners-Lee at IMDb
- Works by or about Tim Berners-Lee in libraries (WorldCat catalog)
- Tim Berners-Lee on the W3C site
- List of Tim Berners-Lee publications on W3C site
- First World Wide Web page
- Interview with Tim Berners Lee
- Tim Berners-Lee: "The next Web of open, linked data" – presented his Semantic Web ideas about Linked Data (2009), Ted Talks. on YouTube
- Appearances on C-SPAN